版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014248127/article/details/84493974
这是关于VQA问题的第三篇系列文章,这篇文章是一篇比较经典的文章,所以跟大家分享。本篇文章将介绍论文:主要思想;模型方法;主要贡献。有兴趣可以查看原文:Ask Your Neurons: A Neural-based Approach to Answering Questions about Images。
1,想法
模型以CNN和LSTM为基础,以一种新的使用方式,设计了一个预测结果长度可变的模型。该模型将视觉问答任务视为结合图像信息作为辅助的sequence to sequence任务。
2,模型
模型:首先由一个预训练好的深度CNN模型抽取出要回答的图片特征,然后将图片特征和转化为词向量的问题词一起送入LSTM网络,在每次送入一个问题词的同时将图片特征送入网络,直到所有的问题特征信息抽取完毕。接下来用同一个LSTM网络产生答案,直至产生结束符($)为止。该模型的训练过程是结合图像特征的LSTM网络的训练以及词向量的生成器的训练。
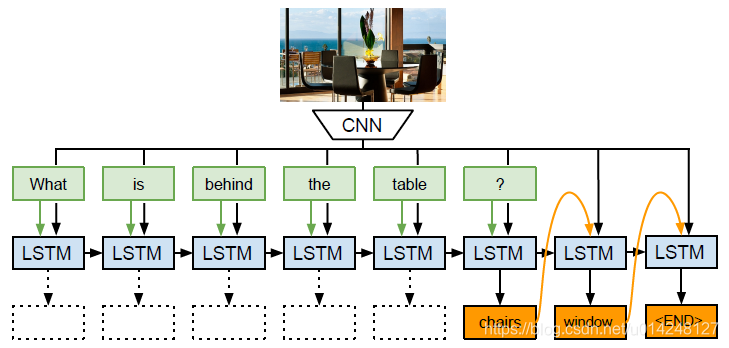
a.图像特征:
用一个训练好的cnn提取图像特征,然后把这个图像特征送入每一个LSTM网络的输入中。
b.文本特征,以及LSTM网络的输入
文本采用词向量的输入,即每个词的词向量。训练时,文本特征包括问题和答案:
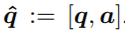
测试时,文本特征包括,问题和前一个词的预测答案:
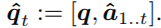
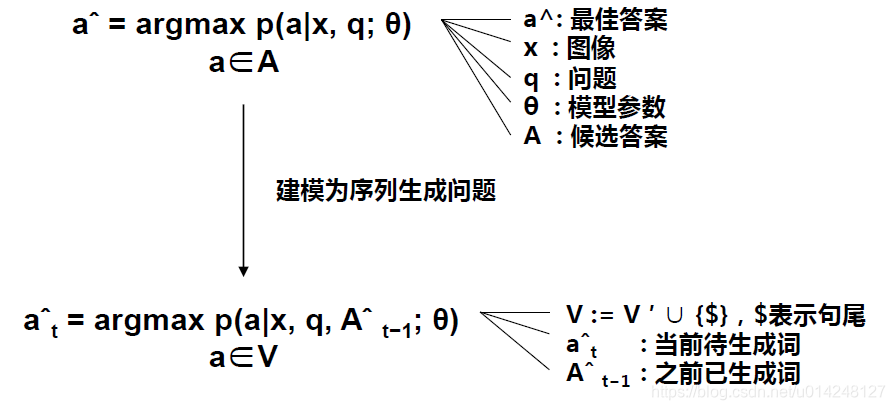
c.采用概率最大的方式预测答案
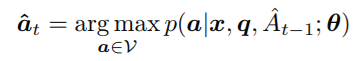
损失函数:只考虑了答案预测部分的损失函数,即问好前面的部分不考虑损失函数。
3.论文的贡献
- 论文提出了seq2seq的方式,长生变长的的答案
- 论文提出了两个新的评估指标,相亲见原论文