Bootstrap your own latent :A new approach to self-supervised Learning(BYOL)
自我监督学习的新方法
Bootstrap your own latent: A new approach to self-supervised Learning | Papers With Code
这篇论文提出了一个新的方法来做自监督的图像的特征学习。使用两个神经网络,即online network和target network,用online network来预测target network输出的特征。之前做自监督常用正负样本进行对比学习,这篇文章的一大创新点在于不再使用负样本,只使用正样本进行学习。
一、就是这么简单
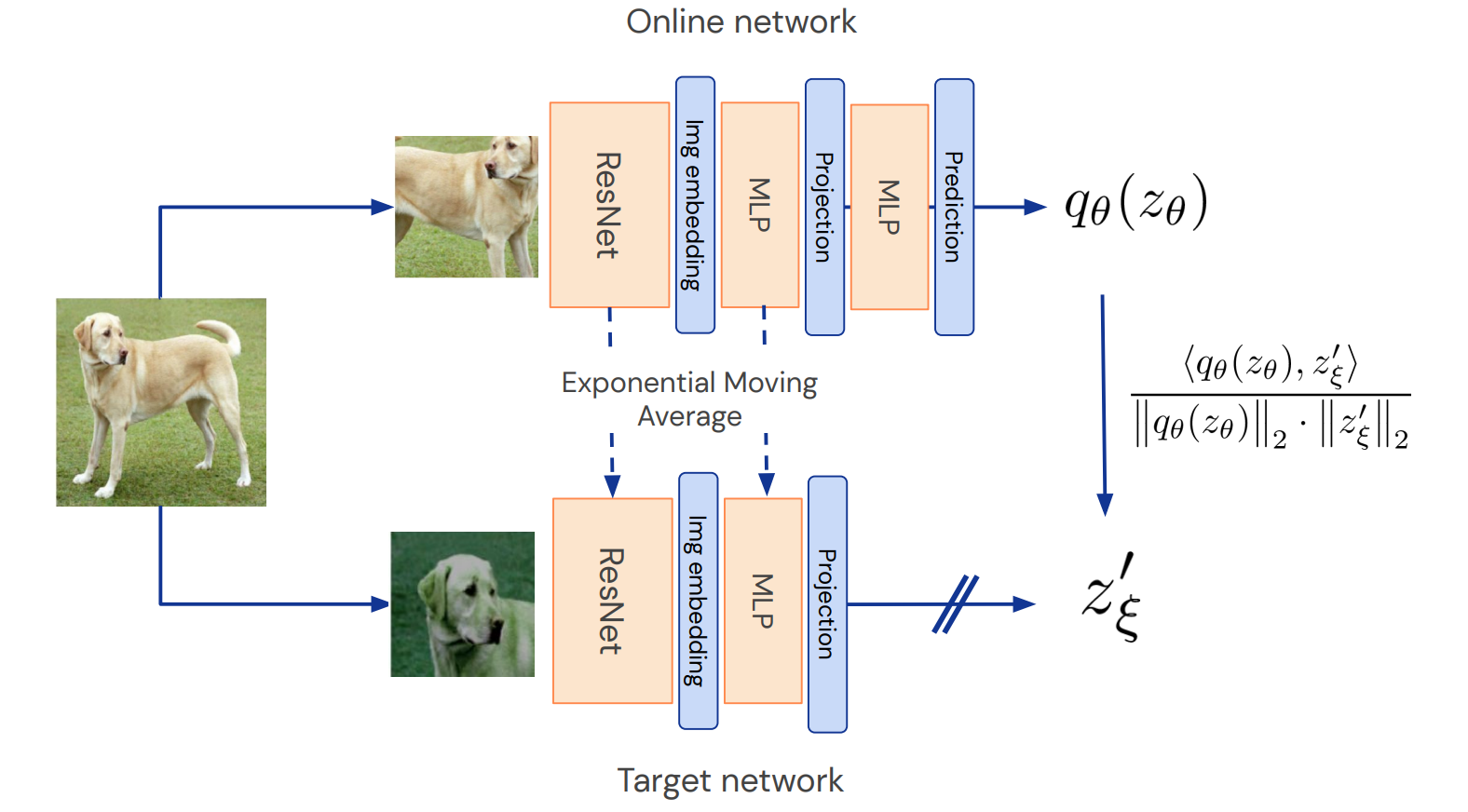
框架真的简单,如图2所示

先对图像做个数据增强,再用ResNet提特征,然后用MLP做个变换,然后online network再用MLP去预测target network的输出,为什么online network要用两个MLP呢?第一个MLP(Projector)是因为SimCLR[2]发现这样好使,作者就follow了这个做法。第二个MLP(Predictor)对这篇论文很重要。最后用输出的两个特征计算L2 Loss作为loss,loss的梯度只在online network上反传,那个双斜杠就是梯度不反传的意思(stop gradient),target network的参数是online network的滑动平均。下图描述更加生动形象一些:
把loss的公式写一下,L2 Loss:

有了loss,参数怎么更新呢,这样更新:
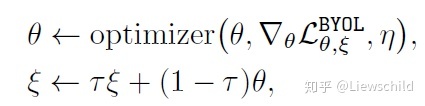
θ 表示online network的参数, ξ 是target network的参数, τ 是更新参数时的权重, τ 越大,更新越缓慢。就是无监督版本的Mean Teacher[4]。
二、为什么这么简单它就work了呢
许多成功的自监督学习方法都是基于多视角预测的框架(cross-view prediction framework)来做的,经典的做法就是,通过预测同一张图的不同视角来学习特征,就是说,同一张图,经过不同的数据增强,得到相同的特征。这会导致一个问题,collapsed representation,也就是不管输入的图像是什么,输出的特征都是一样的,这显然不是我们想要的特征。为了解决这一问题,对比学习的做法是引入负样本,同一图像经过不同数据增强(正样本对)后的特征的距离尽可能近,不同图像(负样本对)的特征的距离尽可能远,这样就保证了学到的特征的判别性。那么,为了防止collapse,负样本是必不可少的吗?
只用图2所示的框架中的online network,随机初始化参数,在ImageNet上的性能是1.4%。加上target network,对target network也随机初始化参数,且固定target network的参数不变,只更新online network的参数,性能涨到了18.8%。注意,此过程没有用到负样本,loss是正样本对的L2距离。看来不用负样本也能提升性能,有希望啊!但是,为什么引入target network就可以避免collapsed representation,作者试图解释,hypothesize和assume了很多东西,但似乎没有解释清楚。
一个较为粗糙的解释可能是,BYOL的参数只有online network的参数 θ 是沿着最小化loss的方向走的,而target network的参数 ξ 不是沿着最小化loss的方向走的,而是 θ 的滑动平均。这解释了为什么引入target network可以避免collapsed representation的原因,但并没有解释为什么BYOL性能这么好。
捋一下作者的思路
作者先假设BYOL的predictor是最优的,可以得到最优的predictor的表示 q∗

然后把这个最优的 q∗ 代入loss的梯度(我觉得应该把求梯度的算子去掉。因为我们是希望loss最小,而不是loss的梯度最小),可以得到
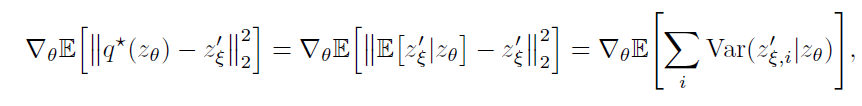
对于任意随机变量 z′ ξ, Zθ 和常量 c , ,所以,online network输出c这种情况最多也就是一个局部最优点(loss不是最小),它不稳定,这样就可以避免collapsed representation了。
这个推导是从假设predictor是最优的开始的,所以要保证predictor一直处于接近最优的状态,才能避免collapsed representation,所以target network不可以突变,因为这样会破坏predictor的最优性,所以对target network采用滑动平均的方式更新参数,而不是直接把online network的参数复制过去。
三、性能
性能非常好,在分类、分割、检测任务上beat SimCLR[2],MoCov2[3],有些还超过了全监督,具体有多好我就不贴图了,感兴趣的话可以去看论文中的表。
四、Ablation
4.1 batch size和数据增强对性能的影响
如图4所示,4096的batch size,在512块Cloud TPU上做实验,啊,计算资源(金钱)的力量真香。在batch size的实验中,随着batch size的减小,BYOL性能掉得比SimCLR少,作者的解释是因为BYOL不需要负样本,所以性能降得少。在数据增强的实验中,SimCLR在移除跟色彩相关的操作后,性能大幅下降,且跌幅远大于BYOL。解释是,同一张图的不同crop的color histogram是相似的,不同图像的histogram则差别较大,在移除color相关的操作后,SimCLR只要学会跟color histogram相关的信息就可以了,但BYOL没有负样本,所以学到的东西不止是color hitogram。综上,BYOL比SimCLR对batch size和数据增强更鲁棒。

图4 batch size和数据增强对性能的影响
4.2 target network的更新速度 τ
如图5所示, τ=0 表示直接使用online network的参数作为target network的参数, τ=1 表示对target network随机初始化后不再更新target netwotk的参数。当 τ≥0.9 时候,就可以左脚踩右脚,慢慢上天了。

图5 τ对实验性能的影响

4.3 各个模块对性能的影响
BYOL和SimCLR的Loss可以整合到InfoNCE的框架下一起讨论, β=0 表示不使用负样本, β=1 表示使用负样本。

对比前两行,可以发现,在BYOL的框架下,使用负样本会降低性能(但是通过调整 α 的值可以达到72.7的性能),再看4-7行,可以发现,没了负样本。SimCLR基本就废了。
加上predictor对SimCLR性能没有太大的影响,在使用负样本的情况下,BYOL有没有predictor对性能的影响也不大。

图6 各个模块对性能的影响
4.4 Projector和Predictor的设置对性能的影响
如图7所示,projector和predictor的深度为2层的时候性能最佳,projector的输出维度为512的时候性能最佳。
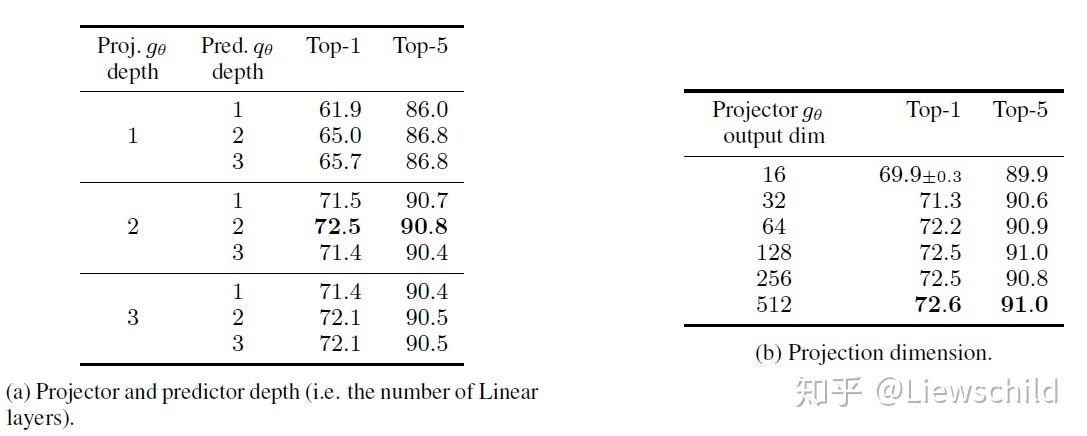
图7 projector和predictor的设置对性能的影响
论文附录里还有一些其他实验,感兴趣的可以去看论文,这里不再一一列出了。
总结一哈
这篇论文的最大的亮点在于完全不用负样本来做自监督学习(世界观),是一个全新的想法。为了避免得到collapsed representation,作者引入了target network/mean teacher(方法论)。