目录
论文链接:https://arxiv.org/pdf/2307.11278.pdf
摘要
开放域问答(QA)任务通常需要从大型语料库中检索相关信息以生成准确的答案。我们提出了一种称为生成器-检索器-生成器(GRG)的新颖方法,它将文档检索技术与大型语言模型(LLM)相结合,首先提示模型根据给定问题生成上下文文档。
同时,双编码器网络从外部语料库中检索与问题相关的文档。然后,生成和检索的文档将传递给第二个LLM,后者生成最终答案。
通过结合文档检索和 LLM 生成,我们的方法解决了开放域 QA 的挑战,例如生成信息丰富且上下文相关的答案。
GRG 的性能优于最先进的“生成然后读取”和“检索然后读取”管道(GENREAD 和 RFiD),在 TriviaQA、NQ 和分别是 WebQ 数据集。我们提供代码、数据集和检查点。
Introduction
开放域问答 (QA) 任务带来了重大挑战,因为它们需要访问大型文档集合或领域知识存储库。现有的 QA 方法(Chen 等人,2017 年;Karpukhin 等人,2020 年;Izacard 和 Grave,2020 年)通常依赖于检索然后读取的管道,其中相关上下文文档是从维基百科等外部来源检索的,并且答案预测以这些文件和问题为条件。
然而,这些方法有几个缺点。首先,检索到的文档通常是分块和固定的,这可能导致包含噪音和不相关的信息。固定大小的文档块可能无法充分捕获所需的上下文寻找准确的答案。因此,不相关信息的存在可能会导致检索到的文档中出现噪音,从而对生成答案的质量和相关性产生负面影响。其次,当前方法中问题和文档的表示通常是独立获得的(Oguz 等人,2020;Yu 等人,2018)。这种独立的处理无法捕获问题和文档之间复杂的交互和依赖关系。因此,模型对问题的理解以及从检索到的文档中提取相关信息的能力可能会受到限制。问题和文档之间的浅层交互阻碍了模型充分利用数据中存在的上下文线索的能力,从而限制了其答案生成的准确性。由于需要有效处理大型语料库,检索器模型参数和嵌入大小受到限制,限制了模型充分利用大型语言模型的世界知识和推导能力的能力。因此,检索器模型可能难以捕获准确生成答案所需的丰富语义和上下文信息(Levine et al., 2022)。
另一方面,开放域 QA 通常涉及训练语言模型来生成给定问题的答案,而无需访问包含答案的随附文档(Zhu et al., 2021;Cheng et al., 2021;阿卜杜拉等人,2023)。开放域 QA 中一种有前途的方法是使用外部知识源(例如维基百科)来增强语言模型,称为证据文档(Izacard 和 Grave,2020)。该方法包括两个核心组件:一个信息检索系统(检索器),用于从知识源中识别相关文本片段;以及一个系统(阅读器),用于根据检索到的文档和问题生成答案。
本文提出了一种称为生成器-检索器-生成器(GRG)的新方法,用于开放域问答。我们的方法将文档检索技术与大型语言模型相结合,以解决生成信息丰富且上下文相关的答案的挑战。我们利用 GPT3 和 InstructGPT(Brown 等人,2020;Ouyang 等人,2022)等大型语言模型的强大功能,根据给定问题生成上下文文档,同时采用密集段落检索( Singh 等人,2021;Karpukhin 等人,2020)从外部来源检索相关文档的系统。然后,第二个大型语言模型处理生成和检索的文档以产生最终答案。通过集成文档检索和大型语言模型生成,所提出的 GRG 方法旨在提高开放域问答的质量和准确性。 GRG 方法的高级架构如图 1 所示。
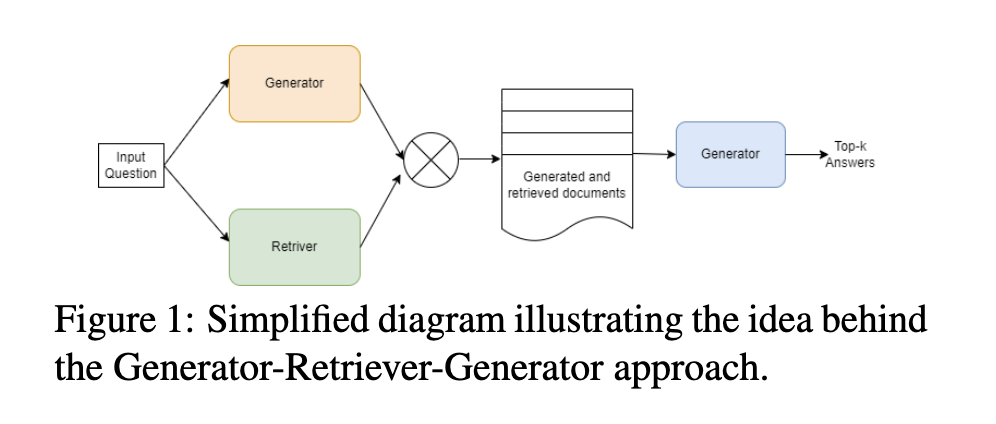
图 1:说明生成器-检索器-生成器方法背后的思想的简化图。
我们的贡献可以总结如下:首先,我们引入了 GRG 方法,该方法集成了文档生成和检索过程以增强答案生成。其次,我们使用 InstructGPT 开发了一种文档生成方法,指示模型生成针对给定问题的上下文丰富的文档。第三,我们提出了向量索引检索器,这是一种基于向量的检索方法,可以根据问题相似性有效地检索相关文档,从而提高知识覆盖率和答案可能性。此外,通过广泛的实验,我们证明了 GRG 方法在开放域问答中的有效性,包括用于分析每个组件贡献的消融研究。最后,我们通过发布我们的代码和检查点来为研究社区做出贡献,实现可重复性并促进未来。
方法
图 2 给出了描述 GRG 方法及其顺序过程的架构图。我们提出的方法,生成器-检索器-生成器(GRG),由三个组成部分组成:(i)用于文档生成的大型语言模型(LLM),(ii)用于文档检索的双编码器网络,以及(iii)用于生成答案的第二个大型语言模型。在以下部分中,我们对每个组成部分进行全面讨论,并概述我们的训练方法。
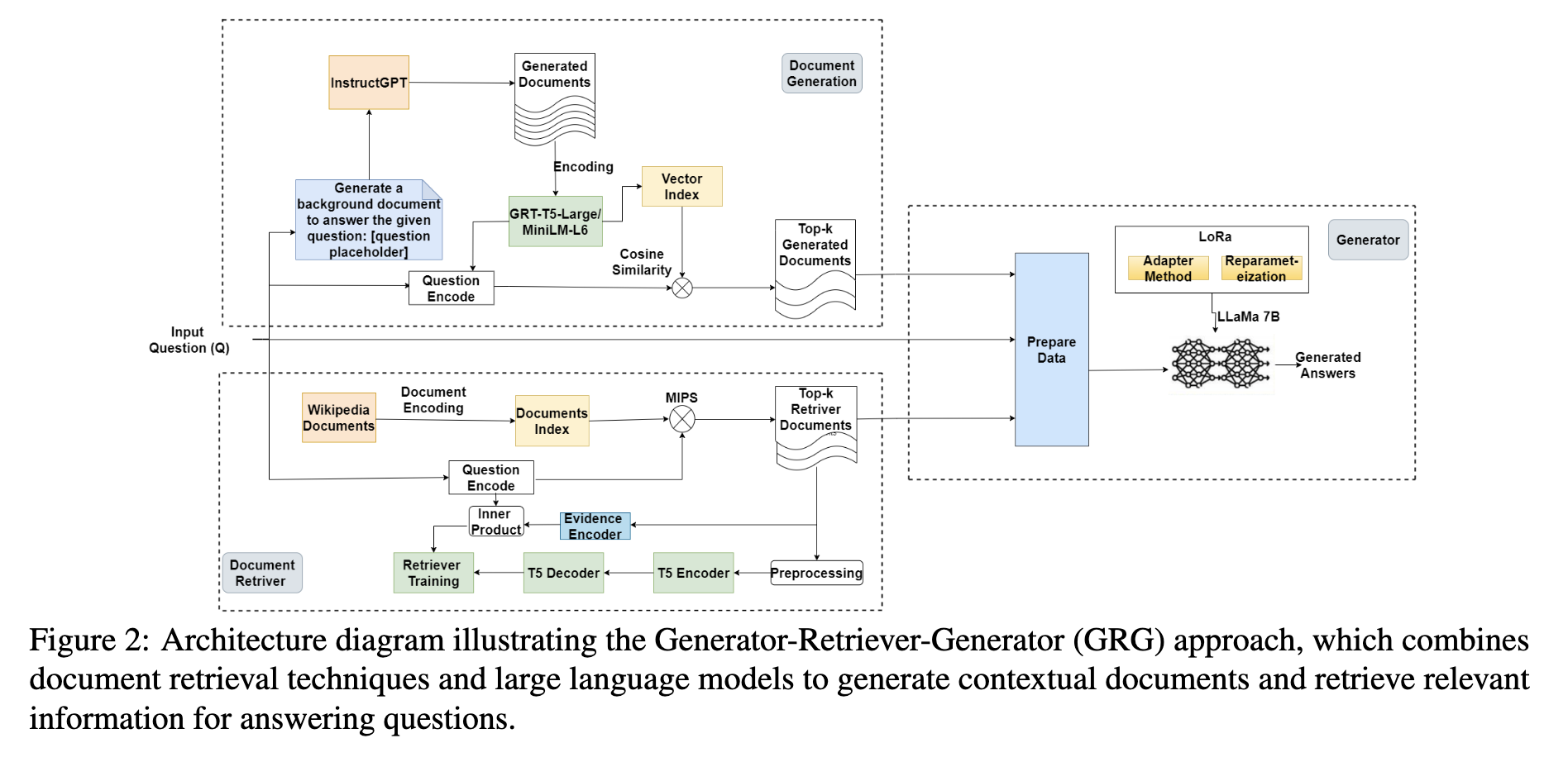
架构图展示了生成器-检索器-生成器 (GRG) 方法,该方法结合文档检索技术和大型语言模型来生成上下文文档并检索相关信息以回答问题。
3.1 文档生成
少样本信息提取任务旨在识别新颖的关系,并从具有有限注释实例的非结构化文本中提取相关信息(Han et al., 2021; Fei et al., 2022; Agirre, 2022; Agrawal et al., 2022)。传统的信息提取方法与数据稀缺作斗争,并且经常面临识别新兴关系类型及其关联实体对的挑战。为了克服这个问题,少样本学习技术利用少量标记样本来泛化到未见过的实例(Lazaridou et al., 2022; Chen et al., 2019; Liu et al., 2018)。
对于我们的例子,当利用语言模型,特别是 InstructGPT (Ouyang et al., 2022) 的力量时,生成信息丰富且上下文丰富的背景文档可以用作少量技术。然后,所提出的 GRG 使用 InstructGPT 通过提供输入提示来生成上下文。对于少样本信息提取,合适的提示结构可以是:“生成背景文档来回答给定问题:[问题占位符]”。通过用实际问题替换“问题占位符”,我们指示模型生成包含回答问题的相关信息的文档。利用 InstructGPT,我们生成信息丰富且上下文丰富的文档,为回答给定问题提供相关信息。然后,这些生成的文档将包含在证据文档集合 D 中。
3.1.1 向量索引检索
我们提出了一种基于向量的检索(Liu,2022)方法,使用向量索引检索器来增加生成文档中知识的相关性(Huang 和Zhang,2009;Xiao 等人,2022;Li 等人,2023)。这种方法利用向量表示和向量存储索引,根据文档与输入问题的相似性来有效地检索文档。矢量索引检索器对于我们的信息检索管道至关重要。它利用向量存储索引,该索引存储由大型语言模型生成的文档的向量表示。
我们通过使用高维向量对每个文档进行编码来捕获每个文档的语义和上下文信息。在检索过程中,矢量索引检索器采用基于相似性的方法来识别最相关的文档。给定一个问题,它重新检索预先指定数量的 top k 结果可以调整k参数来平衡精度和效率。我们在下面描述每个步骤的细节。
第 1 步:生成文档。我们首先使用 InstructGPT 为每个问题 q ∈ Q 生成 10 到 50 个上下文文档 D。这里,Q 代表数据集中的问题集。
第 2 步:对每个文档进行编码。使用 GTR-T5-large/MiniLM-L6(Reimers 和 Gurevych,2019;Ni 等人,2021)语言模型,我们对每个文档进行编码,从而为每个文档生成 768/384 维向量 ei。
步骤 3:向量索引检索。我们存储所有嵌入向量 {ei}|Q|使用向量存储索引 i=1。这允许根据文档与问题的相似性来有效地检索文档。
第 4 步:检索生成的文档。存储编码文档后,我们利用向量索引检索器来处理问题并检索最多 k 个(在我们的实验中为 2 或 5 个)最相关的具有高余弦相似度分数阈值(例如 0.7)的文档。
通过遵循这些步骤,我们的方法可以有效地检索生成的上下文文档以进行开放域问答,特别是选择与问题高度相似的文档,从而选择可能包含正确答案的文档。该检索过程利用向量表示和基于相似性的技术来优先考虑最相关和信息量最大的文档。
3.2 文档检索器
检索器模块在我们的问答模型中起着至关重要的作用。给定一个集合证据文件 D = {d1, . 。 。 , dM } 和问题 q,其目标是选择与问题最相关的文档 Z ⊂ D 的子集。该文档子集将用于进一步处理和答案生成。为此,我们的检索器模型基于 EMDR(多文档阅读器和检索器的端到端训练)(Singh 等人,2021),这是一个双编码器网络(Vaswani 等人,2017) ; Devlin et al., 2019)由两个独立的编码器组成:fq 用于编码问题,fd 用于编码证据文件。每个编码器将一个序列(问题或文档)作为输入并生成其固定大小的向量表示。为了量化问题 q 和证据文档 di 之间的相关性或相似性,我们使用编码器 fq 和 fd 计算它们各自的编码向量。然后通过取这些向量之间的点积来确定检索分数:

其中 enc(q; Φq) 和 enc(di; Φd) 分别表示问题和文档的编码向量,其中 Φ 表示检索器参数。通过计算点积,我们捕获了问题和文档之间的相似性,分数越高表明相关性越强。根据检索分数,我们从集合 D 中针对给定问题 q 选择前 k 个文档,表示为 Z = z1,…。 。 。 ,zk。
3.3 生成模型
我们的生成器基于 LLaMA 模型,这是一个开源语言模型的集合,使用公开可用的数万亿个代币进行了预训练。它在许多基准测试中实现了最先进的性能。生成器模型将问题 q 以及一组检索和生成的文档作为输入来生成答案。
每个检索到的文档 zi 和生成的文档 di 都与问题连接起来。我们使用换行符 (\n) 作为分隔符来确保文档之间的分隔。此外,我们在每个话语的末尾包含 </s> 标记作为回合结束标记,它指示每个输入段的完成。我们的生成器模型的输入表示如下:

LLaMA 语言模型使用了一种称为余弦损失的新型损失函数,可以帮助模型更好地区分相似的单词并提高其准确性。余弦损失定义如下:

其中 hi 是序列中第 i 个标记的隐藏状态,ti 是该标记的目标嵌入。 τ 是控制分布锐度的温度参数。通过合并问题、检索到的文档和生成的文档,我们的生成器模型能够生成针对特定问题和可用输入信息定制的上下文信息答案。
4 实验设置
4.1 数据集
评估是在几个数据集上进行的,遵循与(Yu et al., 2022;Izacard and Grave, 2020;Lee et al., 2019)相同的实验设置。有关如何拆分数据集的更详细说明,我们请读者参阅附录 A。
我们考虑以下数据集: • NaturalQuestions(Kwiatkowski 等人,2019):该数据集由与 Google 搜索查询相对应的问题组成。
TriviaQA(Joshi 等人,2017):该数据集包含从琐事和测验联盟网站收集的问题。对于开放域问答,我们使用数据集的未过滤版本。
WebQ(Berant 等人,2013):WebQ 数据集包含使用 Google Suggest API 获得的问题,答案使用 Mechanical Turk 进行注释。
为了评估我们模型的性能,我们采用了 Zhu 等人提出的精确匹配 (EM) 分数。 (2021)。 EM 分数通过将标准化形式与可接受的答案列表进行比较来衡量答案的正确性。通过这些评估,我们的目的是评估 GRG 模型在开放域问答领域的有效性。
4.2 文件编号的选择
在我们的方法中,由于计算限制和 LLaMA 模型所需的大量训练时间,我们在生成过程中仅使用 2 或 5 个文档。正如 Izacard 和 Grave(2020)报道的那样,使用 100 个文档训练 T5 模型需要大量的计算资源,例如运行大约一天的 64 个 Tesla V100 32GB GPU。虽然增加文档数量可以提高模型性能(Izacard 和 Grave,2020),但它会在内存消耗和训练时间方面产生巨大的成本。
4.3 实验设置
在本节中,我们描述使用 DeepSpeed 框架训练 LLaMA 模型的实验设置(Rajbhandari 等人,2020;Rasley 等人,2020)。 DeepSpeed 提供技术和自动参数调整来优化训练效率和内存利用率。我们使用 DeepSpeed 的配置选项定制了训练过程。首先,我们启用了具有 bfloat16 (bf16) 精度的混合精度训练,以在保持准确性的同时加速训练。选择 AdamW 优化器(Loshchilov 和 Hutter,2017),其超参数由 DeepSpeed 自动确定。为了控制学习率,我们使用 WarmupDecayLR 调度程序。有关实验设置的详细信息,读者可以参阅附录 B。
5 结果
我们在本节中介绍实验结果,分为三个小节:开放域 QA 的结果(第 5.1 节)、文档生成的结果(第 5.2 节)和消融研究。
评估我们的文档检索方法在生成回答开放域问题的相关且信息丰富的文档方面的有效性。在消融研究(第 5.3 节)中,我们研究了不同因素(top-k 答案、架构组件和零样本策略)对我们方法性能的影响
5.1 开放域 QA 结果
本节介绍了所提出的 GRG 方法的结果,该方法结合了生成和检索的文档来回答问题。使用 EM 评分的实验结果如表 1 所示。我们在三个基准数据集:TriviaQA、WebQ 和 NQ 上将 GRG 的性能与多个基准和现有最先进模型进行比较。我们首先将 GRG 与利用维基百科文档检索的基线模型进行比较。这些基线包括 BM25 + BERT (Lee et al., 2019)、REALM (Guu et al., 2020)、DPR (Karpukhin et al., 2020)、RAG (Lewis et al., 2020)、FiD-l (Yu等人,2022)、FiD-xl(Yu 等人,2022)、FiD(Izacard 和 Grave,2020)、EMDR(Singh 等人,2021)、DensePhrases 模型(Lee 等人,2020、2021) ,和 RFiD-large(Wang 等人,2023)。这些基线报告的数字直接取自各自的论文。
具体来说,GRG 比 BM25 + BERT(在 TriviaQA 开发集上提高 29.9%)、REALM(在 WebQ 测试集上提高 15.3%)、DPR(在 WebQ 测试集上提高 14.9%)、FiD(在 WebQ 测试集上提高 14.9%)取得了显着的改进。 NQ 测试集提高了 7.1%),RAG(NQ 测试集提高了 14.0%),证明了组合生成和检索文档方法的有效性。接下来,我们将 GRG 与采用短语检索的 DensePhrases 模型(Lee 等人,2020、2021)进行比较。 DensePhrases 已被证明在问答任务中表现良好。然而,我们的 GRG 方法在所有数据集上都超越了 DensePhrases 的性能。在 TriviaQA 开发集上,GRG 比 DensePhrases 提高了 23.3%(Lee 等人,2020),在 WebQ 测试集上,它比 DensePhrases 提高了 14.5%(Lee 等人,2021)。

此外,我们还针对仅生成文档的 GenRead(Yu 等人,2022)模型评估了 GRG 的性能。 GenRead 模型在生成信息文档方面显示出了有希望的结果。尽管如此,我们的方法在所有数据集上的问答准确性方面始终优于 GenRead。在 TriviaQA 开发集上,GRG 比 GenRead (FiD-l) 提高了 7.3%,在 WebQ 测试集上,
消融
零样本开放域质量检查。表 3 显示了零样本开放域问答 (QA) 评估的结果,其中在没有任何外部文档的情况下评估了不同的模型。这些模型包括 FLAN、GLaM、Chinchilla、Gopher、InstructGPT、GPT-3 和 LLaMA (Rae et al., 2021; Wei et al., 2021; Du et al., 2022; Roberts et al., 2020; Ouyang等人,2022;Touvron 等人,2023),拥有不同的参数大小,并接受过大规模语料库的训练,使他们能够捕获广泛的世界知识。当检查每个模型在回答 TQA、NQ 和 WebQ 数据集问题时的性能时,我们观察到了显着的变化。
尽管 LLaMA 的参数大小相对较小,但它展示了有效利用其参数中嵌入的知识的能力,展示了其作为零样本问答任务的强大工具的潜力。 InstructGPT 和 GPT-3 等模型具有较大的 175B 参数大小,也表现出了有竞争力的性能。 InstructGPT 在 TQA 数据集上实现了 57.4% 的高精度,并且在其他数据集上始终表现良好。 GPT-3 还展示了有竞争力的结果。
详细的架构组件分析我们现在评估在我们的方法中使用的每个组件的性能,特别是检索器和生成器,当与 LLaMA 结合使用时。目标是了解这些组件对整体性能的个别贡献。我们使用不同的模型组合比较 TQA 和 NQ 数据集的结果。图3显示了 TQA 和 NQ 数据集上的 DPR + LL aMA 和翘舌 GPT + LLaMA 模型的性能比较。

在 TQA 数据集上,当用2个文档进行训练时,DirectGPT + LLaMA 模型在开发和测试集上分别达到67.1% 和70.1% 的 EM 评分。当使用5个文档进行培训时,开发集和测试集的性能分别提高到68.4% 和71.8% 。在 NQ 数据集上,DirectGPT + LLaMA 模型表现出竞争性能。在2个文档中,该模型在开发集上的 EM 得分为42.1% ,在测试集上的 EM 得分为42.0% 。当用5个文档进行训练时,EM 分数在开发集上仅增加到43.6% ,在测试集上仅增加到44.5% 。这些发现表明,尽管在培训过程中加入更多的文档可以对模型的性能产生一些积极的影响,但是在提高准确性方面可能会有一个递减的回报。因此,应该在培训文件的数量和由此产生的业绩之间小心地取得平衡,以确保最佳利用计算资源和训练时间。
top-k 答案对性能的影响 我们最终分析了不同的 top-k 值对我们提出的方法的性能的影响。表 4 显示了 NQ 和 TQA 数据集上不同 top-k 值的 EM 和 F1 分数。我们观察到,随着 top-k 值的增加,EM 分数持续提高。例如,在 NQ 数据集上,EM 分数从 top-1 的 56.3% 增加到 top-5 的 71.6%。同样,在 TQA 上,EM 分数从 top-1 的 76.2% 增加到 top-5 的 82.6%。

6 结论
在本文中,我们提出了一种用于改进开放域问答系统的生成器-检索器-生成器方法。通过结合生成和检索的文档,我们在多个基准数据集上取得了显着的性能提升。我们的实验表明,GRG 在准确性和效率方面优于现有基线。结果表明,在阅读过程中结合生成的文档和检索到的文档,充分利用语言模型和检索系统的综合优势,是有效的。未来的工作应该集中于提高文档检索方法的准确性,可能通过使用更多的方法来提高文档检索方法的准确性。高级检索模型或合并附加上下文信息。进一步研究超参数配置,例如生成和检索的文档的数量。