论文解读:Question Answering over Knowledge Base with Neural Attention Combining Global Knowledge Information
KB-QA任务的第二作,其是对上一篇(Question Answering over Freebase with Multi-Column Convolutional Neural Networks)的改进,它也运用了候选答案的多个aspect信息来提升效果,不同的是,其还联合了知识表示学习和注意力机制。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | KBQANG |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 知识图谱问答系统 |
| 4 | 核心内容 | KB-QA;Knowledge Embedding;Attention |
| 5 | GitHub源码 | |
| 6 | 论文PDF | https://arxiv.org/pdf/1606.00979.pdf |
二、全文摘要
随着互联网上知识库的增加,如何充分利用它们变得越来越重要。基于知识库的问答(KB-QA)是获得实质性知识的最有前瞻性的任务之一,同时,随着神经网络的发展,基于神经网络的KB-QA已经获得很大的提升效果。然而,先前的工作并没有强调对问句的表征,同时在对问句表示为低维度固定向量的时候并没有考虑到候选答案的特征,因此这种简单的表征策略并不能很好的表达出合适的候选答案。因此,我们提出一个基于神经网络的注意力机制模型来自动的根据每一个候选答案的各个层面aspect来表征答案。另外,我们利用了知识库下的知识信息来对候选答案进行表征,我们也可以解决OOV(未知词)问题,其有助于注意力机制有效的表示答案。实验在WEBQUESTION数据集上表现出很好的效果。
KB-QA是一个基于知识库完成问答的一个任务,通常的任务逻辑是给定一个问句(wh-系列),根据问句的中心实体来确定候选答案。通常传统的基于SparQL语句既可以完成对知识库的查询(类似于Mysql语句),然而这一类办法通常不能解决大规模图谱以及含有问句的问答形式。现如今比较常用的即是基于语义解析和信息抽取。一种是将问句通过语义分析来确定查询的SparQL语句,或其他逻辑形式,另一种方法则是基于信息抽取,其将问句转化(或提取)有关的中心实体,并与知识库对齐,寻找潜在的候选答案。当然最近可能单纯以KB-QA任务或许比较简单,因此其可以辅助用于一些对话系统中。
KB-QA基于信息抽取的方法中,本文解决方法是将问句和候选答案映射到相同固定维度的向量,其提出四种层面信息(answer entity:候选答案;answer relation:候选答案语义关系;answer type:答案的类型;answer context:候选答案所在的上下文子图),因此每一个Q-A对可以映射到四个不同的语义空间中,每一次对问句进行表征时,通过注意力模型有选择的对问句中每个词进行加权求和。
作者依然也发现了OOV问题,即测试集中可能存在训练集没有遇到的Q-A对,其解决方法是先预训练一个知识表示向量,其涵盖了整个个数据集中每一个Q-A对,因此在测试集测试过程中可以利用这个知识表示向量。
三、模型
给定一个问句
,目标是得到对应的所有可能的答案
。如第一张图所示:
(1)首先,我们识别出问句的中心实体,例如图中中心实体可能是France,然后通过图谱API找出对应的候选答案,图谱选用FreeBase;
(2)然后应用注意力机制对问句进行表征,表征从四个语义层面进行,每次表征则分别根据候选答案对问句中每个词进行加权求和;
(3)最后,每个问句和答案都会形成四个向量,在每个层面上进行相似度计算,最终将四个相似度值相加,即代表这个Q-A的相似度。

具体的模型架构如下图所示。左侧为问句编码,右侧为候选答案编码。候选答案是根据FreeBase API完成的,中心实体则可以使用实体识别工具等(事实上即便是将每个词都作为中心实体,首先会有一部分词因为不在FreeBase中则会过滤掉,剩下的词仅会使得候选答案集合变大,通常来讲KB-QA的问句不会太长,涉及到的中心实体数量不多)。

(1)问句编码:首先使用预训练的词向量对问句每个单词进行表示,并喂入一层双向LSTM,每个单词
输出部分则为
。
(2)候选答案:由于模型的训练是一个问句和一个候选答案,因此每次只喂入一个候选答案,而答案仅是一个实体词,且包含四个层面信息(answer entity;answer relation;answer type;answer context),因此其存在四个向量。其中answer context是指与该候选答案有相连边的临近实体集合,作者处理办法是取均值。最终的四个向量记为
。
(3)注意力模型:作者认为之前的模型存在一个问题:对问句和候选答案的表征都是独立的,二者没有interaction,作者在本文则使用Attention来充当二者之间的interaction部分。如图可知,对问句的表征也有四个层面,对于每个层面来说,其先将
与
拼接一同喂入神经网络和softmax计算权重系数,然后根据这个系数来对每一个
进行加权求和,最终形成问句的表征向量
,其中
。
(4)相似度计算:对于某一个层面信息
,Q-A对为
,相似度为
,最终相似度为四者和,记做
。
(4)训练:我们知道这类任务是需要引入一些负样本。首先对于一个问句
,其可对应于一个候选答案集合
。在训练过程中,这个集合中是可以知道哪些是正确的答案
,哪些是错误的答案
,在训练一个
对时,如果此时的
,则再随机从
中选择
个错误的答案
(作为负样本)。如果
包含的错误答案数量不够,则可以从其他问句的候选答案中随机选取。训练的目标函数为
。总体的训练loss则为:
其中
是一个margin超参。
(5)测试:首先对问句提取候选答案,然后依次计算相似度,并取最大值对应的候选答案作为最佳答案
,然后再依次对其他答案
计算:
, 将大小于
的对应的答案加入到正确答案集合中(简单理解即其他答案的相似度与最佳答案差距小于某个阈值的都可以作为正确答案)。
(6)结合知识库:作者发现上述模型并没有直接使用KB,因此可以联合知识表示学习做增强。选择TransE模型(具体算法讲解可参考博主的另一篇文章:https://blog.csdn.net/qq_36426650/article/details/103316877)。作者采用Multi-Task Learning同时训练两个模型,每一个epoch时,将TransE中的向量更新到KB-QA中。因此KB-QA中候选答案实体也都有对应的embedding,在测试阶段,如果遇到OOV的词,则完全可以使用TransE预训练的向量,解决了OOV问题。
四、实验
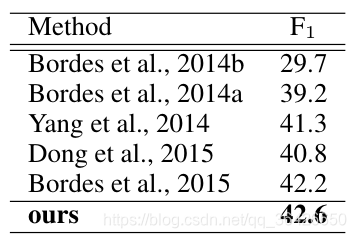
作者在WEBQUESTION数据集上进行实验,与几个BaseLine做比较,效果如下:
同时也执行了一些消融分析,例如对表征部分的LSTM进行分析:

另外,作者也通过可视化方法,对某一个case进行分析,发现四个层面对模型训练的影响:

这里面可以发现,answer entity层面更加关注中心实体词 the carpathian moutain,answer type更加关注where,通过之前的工作也可以知道,这两部分对训练重要性更强。
作者也进行了错误分析,例如模型无法完成对具有逻辑比较的问句进行处理,例如the first,the best等。
本文为较早的一篇KB-QA文章,其解决思路在当时也是非常先进,可以作为入门和学习KB-QA的一篇经典文章。
