转https://blog.csdn.net/ellin_young/article/details/80282081
《Learning Multi-Attention Convolutional Neural Network for Fine-Grained Image Recognition》是微软亚洲研究院17年出的一篇细粒度图像识别论文,它的姊妹篇是《Look Closer to See Better: Recurrent Attention Convolutional Neural Network for Fine-grained Image Recognition》。
之所以是姊妹篇,只因作者是同一班人马,原理还是很不同的,hhh。
一、概述
细粒度识别现在主要依赖于1.具有区分度的局部定位(discriminative part localization)和2.基于局部的精细特征学习(part-based fine-grained feature learning)。目前主流方法是将两者独立开来,忽略了他们两者之间的联系。这篇文章就提出了一个多注意力卷积神经网络(MA-CNN),让part generation 和 feature learning能互相强化。同时模型抛弃手工标记attention part 的方法,采用弱监督学习方法。(手工标注attention part 难定标注位置,且耗费人力)
本文亮点:1.利用feature map 不同通道(channels)关注的视觉信息不同,峰值响应区域也不同这一特点,聚类响应区域相近的通道,得到 attention part。
2.由于1中part 定位方式特殊,本文提出了一个channel grouping loss,目的让part内距离更近(intra-class similarity),不同part距离尽量远(inter-class separability)。
二、模型
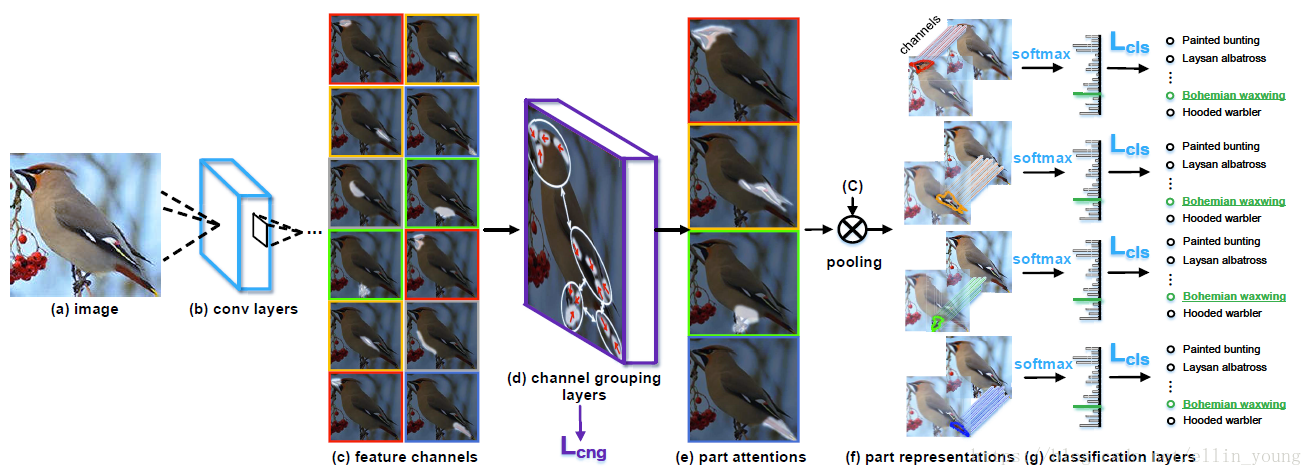
MA-CNN框架如上图所示。模型分为三部分,base network、channel grouping layers 和part classification sub-networks.
输入一张图片(a)给网络,通过base network 产生feature map(b);将(b)中的各通道展开,以12个通道为例,得到(c),可见每个通道都有一个峰值响应区域(白色部分),同时有些通道的峰值响应区域相近(同一种颜色外框表示);文中通过堆叠的全连接层达到聚类效果,把相近的区域归为一类,如图(e),图中划为4类。同类的channel相加,取sigmoid(归一化到0-1)产probabilities,等效于产生4个空间注意区域,即4个mask(局部定位!),这四个mask分别和feature map 进行点乘,得到4个局部精细化的特征,分别进行分类。MA-CNN就是交替的学习,使对每个part的softmax分类损失,及对每个part的channel grouping loss(Lcng)收敛。
三、方法
3.1 channel grouping layers 的预训练
channel grouping layers 是论文最重要的结构(用于 discriminative part localization),也是复现论文的难点之处。
以N个part 为例,就有N组channel grouping layer。每组channel grouping layer的结构由带有tanh的两个fc层构成。
为了防止训练陷入局部最优解,需要对 channel grouping layers进行预训练。具体地,由于每个feature channel 都会对特定类型的视觉模式产生响应,所以每个feature channel 都有一个峰值响应点(peak responses coordinate),这样每个feature channel 都可以用一个位置向量(position vector)表示,其元素是所有训练图像在该通道上的峰值响应坐标(each feature channel can be represented as a position vector whose elements are the coordinates from the peak responses over all training image instances)
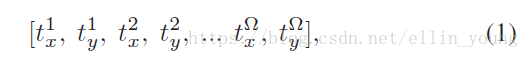
我们把这些位置向量当作特征,进行聚类,将不同的channels分成N个groups,即N个parts。用长度为c(通道数)的指示向量表示每个channel 是否属于该group,如果是,该channel 位置为1,否则为0。
N个指示向量为互斥的关系。
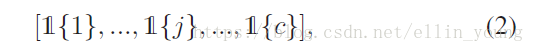
为了保证上述过程在训练中得到优化,我们用fc近似这个聚类过程,产生N个part,就用N组FC layers.每个fc接收base network 的feature map,然后产生一个权重向量di
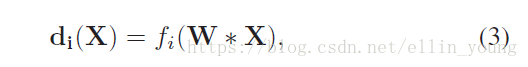

为了获得准确的权重向量,我们需要预训练fc参数,使(3)的输出接近预于(2)。基于学习到的权重向量,我们可以得到每个part 的 attention map。W*X 代表base network 提取的feature map .dj与对应feature channel 相乘,相加后用sigmoid 归一化得到一个probabilities map.
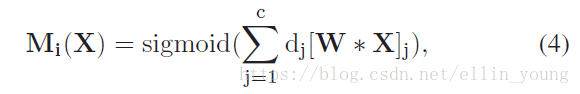
延伸一点,局部精细化特征(fine features),由probabilities map 与base network 提取的feature map进行点乘,累加,如Eqn.(5)
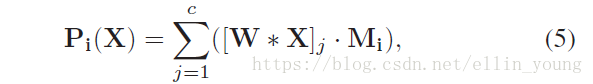
3.2 MA-CNN损失函数
MA-CNN的损失由两部分组成,一部分是part classification loss,即普通的分类网络中的交叉熵;另一部分是channel grouping loss。一张图片X的loss表示如下,N表示N个part。

其中,lcng是由Dis和Div两块组成。Dis是使同一part内的坐标更聚集,Div是使不同part尽量疏远。
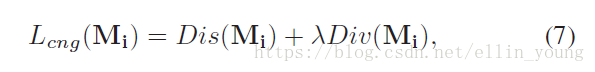

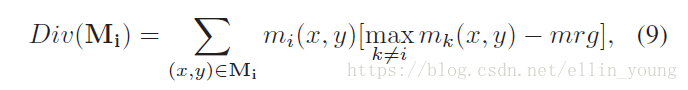
3.3 交替优化
论文中采用相互强化的方式,交替训练分类网络和channel group layers。首先,固定卷积层,通过Lcng优化channel grouping layers 。然后固定channel grouping layers,通过Lcls,训练卷积层和softmax。交替迭代直至两类loss都不再改变。
四、实验结论:
part数量在一定范围内增加会提高准确率,但达到一定量后会处于饱和状态,准确率不再提升。