我的结论(仅仅代表个人观点)
* 2020年2月的论文
* 官方论文没有公开代码(20200526)。没有代码,一些重要的结论无法测试和验证。
* 恢复结果结构信息以及图像清晰度得到保障。(第一次看到论文直接说了清晰度这个问题。值得注意)
* 分辨率,512*512
* 正脸和小角度侧脸都好用,大角度侧脸没有给出测试结果,没有代码无法测试。
* 对人脸和日常场景照修复效果都挺好的。
* 论文自己说它比以下论文效果好。
20. 《CE: Context encoders: Feature learning by inpainting》 (CVPP 2016)
28.《Shift-net: Image inpainting via deep feature rearrangement》(ECCV 2017)
26.《GMCNN:Image inpainting via generative mulit-column convolutional neural networks》(NeurIPS 2018)
33.《PICNet:Pluralistic image completion》(CVPR 2019)
1、题目
《Image Fine-grained Inpainting》
作者:

论文地址:
https://arxiv.org/pdf/2002.02609.pdf
代码地址:
* 作者给的,在20200526日看的时候没有代码,不知道以后还会不会给。https://github.com/Zheng222/DMFN
* 某个读者自己实现的。代码地址:https://github.com/HannH/DMFN
读者自己写了一篇关于论文解读的博客,地址为:https://blog.csdn.net/h8832077/article/details/105166776
2、创新点
a、self-guided regression loss
We propose a novel self-guided regression loss to explicitly correct the low-level features, according to the normalized error map computed by the output and
ground-truth images. This function can significantly improve the semantic structure and fidelity of images
b、a geometrical alignment constraint
We present a geometrical alignment constraint to supplement the shortage of pixel-based VGG features matching loss.
c、a dense multi-scale fusion generator
We propose a dense multi-scale fusion generator, which has the merit of strong representation ability to extract useful features. Our generative image inpainting framework achieves compelling visual results (as illustrated in Figure 1) on challenging datasets, compared with previous state-of-the-art approaches
3、网络框架
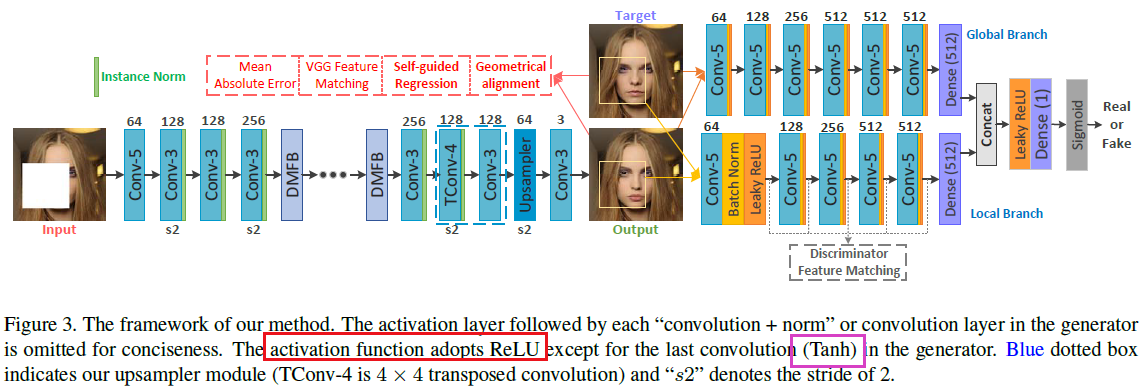
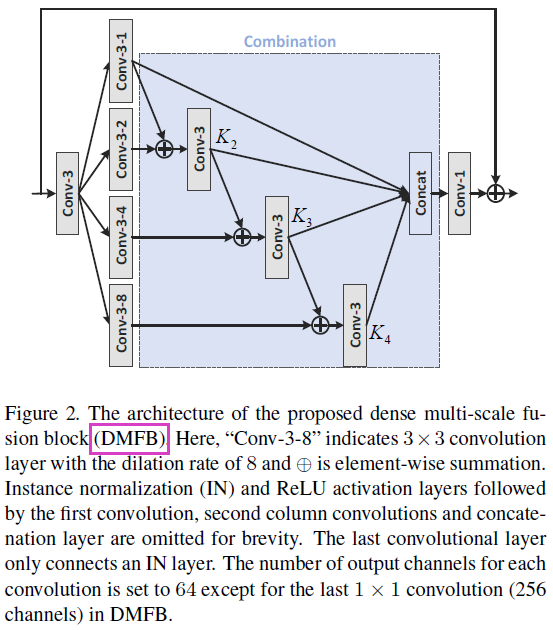
4、loss函数
a、 L1 loss
![]()
b、Perceptual Loss

c、Adversarial Loss

d、Overall Loss

5、实验
AA、实验数据集
a、CelebA数据集:
数据:200K celebrity images,each with 40 attribute annotations
划分:随机选择3000张图进行测试,剩下的训练
****:训练和测试的过程中,没有采用任何属性label
b、Helen数据集:
数据:2330个脸
划分:2000训练,300测试。
CelebA数据集,进行模型的训练、测试和验证。Helen数据集,交叉验证,对模型进行进一步的评估。
BB、实验细节
* Training epoch 50。完成50epoch,采用NVIDIA TITAN X GPU,用时69h。
* Adam优化算法,学习率0.0002,beta1=0.5, beta2=0.9。
* CeleA数据对齐到160*160大小的脸,然后resize脸图到128*128。
* 一个训练样本包含:原始图像+二值mask。遮挡图像的不同区域,获得不同的二值mask,给一张图像,可以得到多组训练数据。
* mask包含两种样式的:
1) Random irregular masks with approximately 25%–40% missing;
2) Homocentric squares pattern masks with around 7 to 16 pixels are missing
6、实验结果
a、图像清晰度效果
双眼皮,睫毛等细节信息保留的超级好。


b、正脸or小角度脸的效果

c、非人脸图像的测试效果

