Selective Sparse Sampling for Fine-grained Image Recognition

文章目录
参考
Introduction
-
本文非常有意思,引入一种名为稀疏注意力的机制,通过这个机制将目标的关键细粒度(Fine-grained)特征放大,然后concat进行细粒度分类。
-
之所以说有意思,是因为这个稀疏注意力机制的实现,下文会详细描述。
-

-
作者的主要贡献如下:
- 开发了一种新的选择性稀疏采样框架,该框架通过学习一组稀疏注意来选择性采样信息区域,并在保留上下文信息的同时提取鉴别和互补特征,从而解决了具有挑战性的细粒度图像识别问题
- 使用流行的CNN(如ResNet50)实现作者的的方法,这表明在模型准确性和挖掘视觉证据的能力方面比基线有了实质性的改进
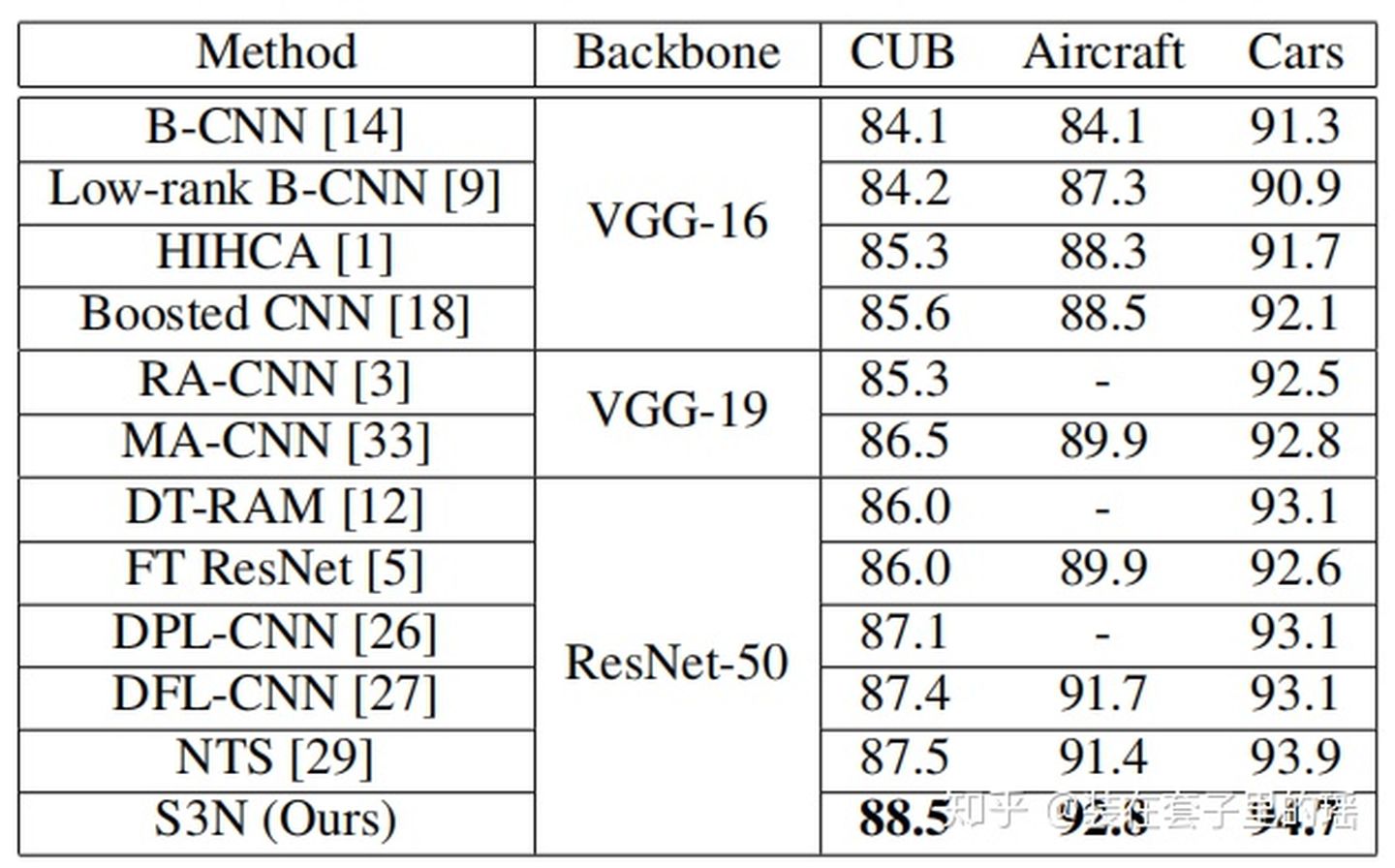
- 综合实验分析以及常见细粒度识别基准的最新性能,包括CUB-2002011鸟类、FGVC飞机和斯坦福汽车
Related Work
-
本文中作者一直在强调的一个点,如下:
- 细粒度识别的一个关键点是局部特征的抽取与识别,但如MA- CNN中所示,他虽然识别出来了bird的局部特征,但是直接将局部crop出来可能会导致环境信息的丢失,这就是作者在强调的,传统细粒度识别更关注局部特征的抽取而或略了周边环境的影响
- 于是作者提出将局部特征放大的同时保留周边环境等信息,就如下半边所示只是吧鸟头、翅膀、尾巴放大,并没有剪裁
-

Methodology
Model Structure
-
模型的结构如下图所示
-

-
对于输入,先经过一段CNN提取特征
-
然后激活得到Class Response Map(这一部分见下文Class Peak Response)
-
对其进行苹果得到Sparse Attention(这一部分见下文Learning Sparse Attention)
-
然后分为Discriminative和Complementary两类,前者提供了主要的细粒度特征,后者作为补充
-
然后Reuse之前的CNN进行分类,Discriminative和Complementary以及原来的Input image各有一个loss,再加上整体concat后的分类有一个loss,求和就是整体的loss,于是这样整体concat后的分类就是最终的分类结果
-
代码实现如下,已注释,位于sss_net.py中的class S3N(nn.Module)类中的forward:
-
def forward(self, input_x, p): # 复制分类器的weight和bias用于公式1 self.map_origin.weight.data.copy_(self.raw_classifier.weight.data.unsqueeze(-1).unsqueeze(-1)) self.map_origin.bias.data.copy_(self.raw_classifier.bias.data) # basemodel(这里用的是res50)走一遍CNN feature_raw = self.features(input_x) # 先走一个GAP,再走一个FC分类得到agg_origin agg_origin = self.raw_classifier(self.avg(feature_raw).view(-1, 2048)) with torch.no_grad(): # 根据给定 size 或 scale_factor,上采样或下采样输入数据input. # 上采样算法有:nearest, linear(3D-only), bilinear(4D-only), trilinear(5D-only). # 首先self.map_origin(feature_raw)是一个1x1卷积, nn.Conv2d(in_channels=2048, out_channels=num_classes, kernel_size=1, stride=1, padding=0) # 这里将channel降到num_class,目的就是为了实现文中公式1得到Mc, # 我们知道feature_raw就是文中的S,是DXHXW维的,然后self.map_origin复制了FC的weight和bias于是就实现了公式1 # self.grid_size = 31 class_response_maps = F.interpolate(self.map_origin(feature_raw), size=self.grid_size, mode='bilinear', align_corners=True) # 这里是Class Response Map生成peak点也就是Sparse Attention x_sampled_zoom, x_sampled_inv = self.generate_map(input_x, class_response_maps, p) # 这里是Td,及其sample,sample就是一组卷积+BN+池化,然后进入cls feature_D = self.sampler_buffer(self.features(x_sampled_zoom)) agg_sampler = self.sampler_classifier(self.avg(feature_D).view(-1, 2048)) # 这里是Tc,及其sample同上 feature_C = self.sampler_buffer1(self.features(x_sampled_inv)) agg_sampler1 = self.sampler_classifier1(self.avg(feature_C).view(-1, 2048)) # concat之后的进行cls aggregation = self.con_classifier(torch.cat([self.avg(feature_raw).view(-1, 2048), self.avg(feature_D).view(-1, 2048), self.avg(feature_C).view(-1, 2048)], 1)) return aggregation, agg_origin, agg_sampler, agg_sampler1 -
可以看出代码这块基本就和论文的流程是一致的
Class Peak Response
-
这一段是全文值得推敲的地方之一,如何得到所谓的Class Response Map,也即是Activate是怎么做的
-

-
首先,做一个分类,这个分类结果再后面总分类的时候会用到,实现的话,就下面一行
-
浅谈Global average pooling (GAP):每个讲到全局池化的都会说GAP就是把avg pooling的窗口大小设置成feature map的大小,这虽然是正确的,但这并不是GAP内涵的全部。GAP的意义是对整个网络从结构上做正则化防止过拟合。
-
# 先走一个GAP,再走一个FC分类得到agg_origin agg_origin = self.raw_classifier(self.avg(feature_raw).view(-1, 2048))
-
-
接下来就是公式1:
-
M c = ∑ d = 1 D W d , c f c × S d M_c = \sum^D_{d=1} W^{fc}_{d,c} \times S_d Mc=d=1∑DWd,cfc×Sd
-
这个公式使用FC的权重去乘以经过CNN之后的Feature Map S,对某个类注意这里是S逐channel乘以FC中相应的权重得到的Mc,代码实现的话,摘出来就长这样:
-
# 复制分类器的weight和bias用于公式1 self.map_origin.weight.data.copy_(self.raw_classifier.weight.data.unsqueeze(-1).unsqueeze(-1)) self.map_origin.bias.data.copy_(self.raw_classifier.bias.data) # 根据给定 size 或 scale_factor,上采样或下采样输入数据input. # 上采样算法有:nearest, linear(3D-only), bilinear(4D-only), trilinear(5D-only). # 首先self.map_origin(feature_raw)是一个1x1卷积, nn.Conv2d(in_channels=2048, out_channels=num_classes, kernel_size=1, stride=1, padding=0) # 这里将channel降到num_class,目的就是为了实现文中公式1得到Mc, # 我们知道feature_raw就是文中的S,是DXHXW维的,然后self.map_origin复制了FC的weight和bias于是就实现了公式1 # self.grid_size = 31 class_response_maps = F.interpolate(self.map_origin(feature_raw), size=self.grid_size, mode='bilinear', align_corners=True)
-
-
自此我们就得到了它:
-

Learning Sparse Attention & Selective Sampling
- 给他俩放一起的原因是在代码中他们是一个方法,下面是整体的实现,接下来会尽力解释公式与代码
def generate_map(self, input_x, class_response_maps, p):
# 上采样后的map维度
N, C, H, W = class_response_maps.size()
# 先对每个类进行F.softmax分类,然后排序,用于下面信息熵的计算
score_pred, sort_number = torch.sort(F.softmax(F.adaptive_avg_pool2d(class_response_maps, 1), dim=1), dim=1, descending=True)
# 这里是公式2,得到信息熵
gate_score = (score_pred[:, 0:5]*torch.log(score_pred[:, 0:5])).sum(1)
xs = []
xs_inv = []
# N代表minibatch数,这里表示逐张处理
for idx_i in range(N):
# 这里是根据gate_score[idx_i](这东西是文中的信息熵),来判定是5个M叠加只取第一个,这就实现了公式3
if gate_score[idx_i] > -0.2:
decide_map = class_response_maps[idx_i, sort_number[idx_i, 0],:,:]
else:
decide_map = class_response_maps[idx_i, sort_number[idx_i, 0:5],:,:].mean(0)
# 这里做了一下归一化,也就是文中的Min-Max Normalize
min_value, max_value = decide_map.min(), decide_map.max()
decide_map = (decide_map-min_value)/(max_value-min_value)
# 实际上是调用类PeakStimulation方法,
peak_list, aggregation = peak_stimulation(decide_map, win_size=3, peak_filter=_mean_filter)
# 维度压缩
decide_map = decide_map.squeeze(0).squeeze(0)
score = [decide_map[item[2], item[3]] for item in peak_list]
# peak坐标
x = [item[3] for item in peak_list]
y = [item[2] for item in peak_list]
if score == []:
temp = torch.zeros(1, 1, self.grid_size,self.grid_size).cuda()
temp += self.base_ratio
xs.append(temp)
xs_soft.append(temp)
continue
# peak数量
peak_num = torch.arange(len(score))
temp = self.base_ratio
temp_w = self.base_ratio
if p == 0:
for i in peak_num:
temp += score[i] * kernel_generate(self.radius(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda()
temp_w += 1/score[i] * \
kernel_generate(self.radius_inv(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda()
elif p == 1:
# 看论文中的描述,p应该是1,也就是下面的这段
for i in peak_num:
# 生成一个随机阈值
rd = random.uniform(0, 1)
# 下面的两断计算的是sparse attention A
# Td和Tc
if score[i] > rd:
# Td,公式5的上半部
# self.radius是放大层,作用就是将输入放大radius倍
# self.radius = ScaleLayer(radius)
# self.radius_inv = ScaleLayer(radius_inv)
# kernel_generate是Gaussian kernel
# score[i]就是之前公式3中计算的R
temp += score[i] * kernel_generate(self.radius(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda()
else:
# Tc,公式5的下半部
temp_w += 1/score[i] * \
kernel_generate(self.radius_inv(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda()
elif p == 2:
index = score.index(max(score))
temp += score[index] * kernel_generate(self.radius(score[index]), H, (x[index].item(), y[index].item())).unsqueeze(0).unsqueeze(0).cuda()
index = score.index(min(score))
temp_w += 1/score[index] * \
kernel_generate(self.radius_inv(torch.sqrt(score[index])), H, (x[index].item(), y[index].item())).unsqueeze(0).unsqueeze(0).cuda()
if type(temp) == float:
temp += torch.zeros(1, 1, self.grid_size,self.grid_size).cuda()
xs.append(temp)
if type(temp_w) == float:
temp_w += torch.zeros(1, 1, self.grid_size,self.grid_size).cuda()
xs_inv.append(temp_w)
# 这一句是公式6的上半部Td的Ai求和
xs = torch.cat(xs, 0)
xs_hm = nn.ReplicationPad2d(self.padding_size)(xs)
# 生成自定义网格,在这里进行局部放大
grid = self.create_grid(xs_hm).to(input_x.device)
# https://blog.csdn.net/qq_29679623/article/details/89341746
x_sampled_zoom = F.grid_sample(input_x, grid)
# 这一句是公式6的下半部Tc的Ai求和
xs_inv = torch.cat(xs_inv, 0)
xs_hm_inv = nn.ReplicationPad2d(self.padding_size)(xs_inv)
# 同上
grid_inv = self.create_grid(xs_hm_inv).to(input_x.device)
x_sampled_inv = F.grid_sample(input_x, grid_inv)
return x_sampled_zoom, x_sampled_inv
-
首先计算Prob(用softmax做一个分类)
-
P r o b = s o f t m a x ( s ) Prob = softmax(s) Prob=softmax(s)
-
# 先对每个类进行F.softmax分类,然后排序,用于下面信息熵的计算 score_pred, sort_number = torch.sort(F.softmax(F.adaptive_avg_pool2d(class_response_maps, 1), dim=1), dim=1, descending=True) -
然后计算信息熵(公式2),用于表示信息量大多少:
-
H = − ∑ i = 1 5 p i log p i p i ∈ P r o b ^ H = - \sum^5_{i=1}p_i\log p_i \qquad pi \in \hat {Prob} H=−i=1∑5pilogpipi∈Prob^
-
其中 P r o b ^ \hat {Prob} Prob^是Prob的top-5,代码实现的话就,比较好理解:
-
# 这里是公式2,得到信息熵 gate_score = (score_pred[:, 0:5]*torch.log(score_pred[:, 0:5])).sum(1) -
response map R的计算公式如下(公式3):
-
R = { M 1 ^ i f H ⩽ σ ∑ i = 1 5 M k ^ i f H > σ R = \left\{ \begin{array}{cc} \hat{M_1} & if \quad H \leqslant \sigma \\ \sum^5_{i=1} \hat{M_k} & if \quad H > \sigma \end{array} \right. R={ M1^∑i=15Mk^ifH⩽σifH>σ
- M ∈ R 5 × H × W M \in R^{5×H×W} M∈R5×H×W ,top-5对应的Map
- σ \sigma σ是threshold
-
# 这里是根据gate_score[idx_i](这东西是文中的信息熵),来判定是5个M叠加只取第一个,这就实现了公式3 if gate_score[idx_i] > -0.2: decide_map = class_response_maps[idx_i, sort_number[idx_i, 0],:,:] else: decide_map = class_response_maps[idx_i, sort_number[idx_i, 0:5],:,:].mean(0) -
接下来做了一个Min-Max Normalize
-
R = R − min ( R ) max ( R ) − min ( R ) R = \frac{R−\min(R)}{\max(R)−\min(R)} R=max(R)−min(R)R−min(R)
-
# 这里做了一下归一化,也就是文中的Min-Max Normalize min_value, max_value = decide_map.min(), decide_map.max() decide_map = (decide_map-min_value)/(max_value-min_value) -
公式4、5在代码中是一块的,4就是用if挑选Td和Tc然后只想对应的公式5部分,而公式5就是利用Gaussian kernel去计算sparse attention A(稀疏注意力)
-
T d = { ( x , y ) ∣ ( x , y ) ∈ T i f R x , y ≥ ζ } T c = { ( x , y ) ∣ ( x , y ) ∈ T i f R x , y < ζ } Td= \{(x, y)| (x, y) ∈ T ifRx,y \geq ζ \} \\ Tc= \{(x, y)| (x, y) ∈ T ifRx,y< ζ \} Td={ (x,y)∣(x,y)∈TifRx,y≥ζ}Tc={ (x,y)∣(x,y)∈TifRx,y<ζ}
-
A i , x , y = { R x i , y i exp ( − ( x − x i ) 2 + ( y − y i ) 2 R x i , y i β 1 2 ) i f ( x i , y i ) ∈ T d 1 R x i , y i exp ( − ( x − x i ) 2 + ( y − y i ) 2 R x i , y i β 2 2 ) , i f ( x i , y i ) ∈ T d A_{i,x,y} = \left \{ R_{x_i,y_i} \exp(-\frac{(x-x_i)^2+(y-y_i)^2}{R_{x_i,y_i}\beta^2_1}) \quad if (x_i,y_i) \in T_d \\ \frac{1}{R_{x_i,y_i}} \exp(-\frac{(x-x_i)^2+(y-y_i)^2}{R_{x_i,y_i}\beta^2_2}),if (x_i,y_i) \in T_d \right. Ai,x,y={ Rxi,yiexp(−Rxi,yiβ12(x−xi)2+(y−yi)2)if(xi,yi)∈TdRxi,yi1exp(−Rxi,yiβ22(x−xi)2+(y−yi)2),if(xi,yi)∈Td
-
elif p == 1: # 看论文中的描述,p应该是1,也就是下面的这段 for i in peak_num: # 生成一个随机阈值 rd = random.uniform(0, 1) # 下面的两断计算的是sparse attention A # Td和Tc if score[i] > rd: # Td,公式5的上半部 # self.radius是放大层,作用就是将输入放大radius倍 # self.radius = ScaleLayer(radius) # self.radius_inv = ScaleLayer(radius_inv) # kernel_generate是Gaussian kernel # score[i]就是之前公式3中计算的R temp += score[i] * kernel_generate(self.radius(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda() else: # Tc,公式5的下半部 temp_w += 1/score[i] * \ kernel_generate(self.radius_inv(torch.sqrt(score[i])), H, (x[i].item(), y[i].item())).unsqueeze(0).unsqueeze(0).cuda() -
自此我们就有了它,同时这些peaks被分为两类:discriminative分支和complementary分支:
-

-
接下来就是Selective Sampling部分了
-
据作者描述,用了SS补充的peak不会随着训练而消失
-

-
公式6就是吧两部分A加起来(在代码中这两部分A本来就是存在两个数组里面的)后面分别对 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-w4IaCr40-1630642218898)(https://www.zhihu.com/equation?tex=Q%5E%7Bd%7D)] 和 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mmdLCKAi-1630642218899)(https://www.zhihu.com/equation?tex=Q%5E%7Bc%7D)] 做Selective Sampling. Selective Sampling 在论文Learning to Zoom: a Saliency-Based Sampling Layer for Neural Networks(ECCV2018) 中有描述。
-
Q d = ∑ A i i f ( x i , y i ) ∈ T d Q c = ∑ A i i f ( x i , y i ) ∈ T c Q^d = \sum A_i \quad if (x_i,y_i) \in T_d \\ Q^c = \sum A_i \quad if (x_i,y_i) \in T_c Qd=∑Aiif(xi,yi)∈TdQc=∑Aiif(xi,yi)∈Tc
-
公式7、8是根据采样生成的新的网格点,将像素按照比例映射到图片上
-
f ( v ) = ∑ v ′ Q ( v ′ ) k ( v ′ , v ) v x ′ ∑ v ′ Q ( v ′ ) k ( v ′ , v ) g ( v ) = ∑ v ′ Q ( v ′ ) k ( v ′ , v ) v y ′ ∑ v ′ Q ( v ′ ) k ( v ′ , v ) f(v) = \frac{\sum_{v^{'} }Q(v^{'})k(v^{'},v)v^{'}_x}{\sum_{v^{'} }Q(v^{'})k(v^{'},v)} \\ g(v) = \frac{\sum_{v^{'} }Q(v^{'})k(v^{'},v)v^{'}_y}{\sum_{v^{'} }Q(v^{'})k(v^{'},v)} f(v)=∑v′Q(v′)k(v′,v)∑v′Q(v′)k(v′,v)vx′g(v)=∑v′Q(v′)k(v′,v)∑v′Q(v′)k(v′,v)vy′
-
# 这一句是公式6的上半部Td的Ai求和 xs = torch.cat(xs, 0) xs_hm = nn.ReplicationPad2d(self.padding_size)(xs) # 生成自定义网格,在这里进行局部放大 grid = self.create_grid(xs_hm).to(input_x.device) # https://blog.csdn.net/qq_29679623/article/details/89341746 x_sampled_zoom = F.grid_sample(input_x, grid) # 这一句是公式6的下半部Tc的Ai求和 xs_inv = torch.cat(xs_inv, 0) xs_hm_inv = nn.ReplicationPad2d(self.padding_size)(xs_inv) # 同上 grid_inv = self.create_grid(xs_hm_inv).to(input_x.device) x_sampled_inv = F.grid_sample(input_x, grid_inv) -
自此我们就得到了它:
-

-
然后后面就是全部进CNN再concat feature map之后做cls这部分偷了个懒抓了知乎的一篇里对应的内容
Fine-Grained Feature Learning
-
上述生成的两个采样图像(分别包含discriminative和complementary信息)和原图具有相同的尺寸大小,采样后的图像输入到S3N提取Fine-Grained feature,相同的backbone重新用作特征提取。
-
F j = { F O , F D , F C } F_j = \{F_O,F_D,F_C\} Fj={ FO,FD,FC}中 F O , F D , F C F_O,F_D,F_C FO,FD,FC分别表示原图,disciriminative分支的图像和complementary分支的图像。这些特征图全部concatenate之后经过FC和softmax 进行分类。
-
Loss 定义如下:
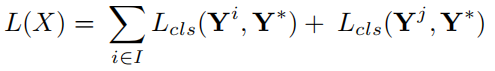
- L c l s L_{cls} Lcls是Cross-entropy 损失, I I I是 { O , D , C } \{O,D,C\} { O,D,C} , $ y^i$是预测向量。 Y ∗ Y^* Y∗ 是标签向量, Y j Y^j Yj 是concatenate feature的预测向量。
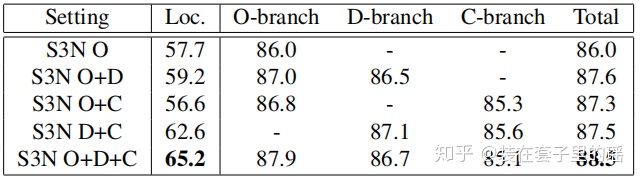
实验结果
5.实验结果
- Image size =448x448
- Backbone= Resnet50
- epoch=60
- batchsize=16
- weight decay =1e-4
- momentum=0.9
- parametres 加载在ImageNet上的预训练权重
- initial learning rate=0.001
- 其他参数 initial learning rate=0.01.