这是一篇来自清华2018年的paper。
文章做的是基于知识注意力机制的细粒度实体分类任务(Fine-Grained Entity Typing)。
任务介绍:
给定一个句子,其中包含一个实体和它的上下文,以及一组实体类型,我们的模型旨在预测所提到的实体的每种类型的概率。
**提出问题:**大多数现有的方法通常分别从实体提及和上下文单词中提取特征来进行实体类型分类。这些方法不能对实体提及和上下文词之间的复杂关系进行建模,同时也忽视了知识库中关于这些实体的丰富背景信息。
贡献:(1)将knowledge base的信息引入特征向量.(2)将实体提及和它们的上下文联系起来,从而提出了融合知识-注意力的神经网络细粒度实体分类模型。
**模型:**模型分为两部分1)将句子s编码成特征向量x的句子编码器。2)类型预测器,通过从x计算y来推断实体类型。

**Knowledge Representation Learning:**知识表示学习(KRL)是将三元组中的实体和关系的语义信息编码到低维语义空间中,该部分使用TransE。
Sentence encoder:特征向量x包括entity mention representation m、context representations c。
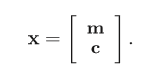
Entity mention representation:
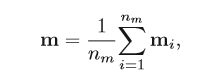
n_m是entity mention的长度,通常是1或2。这里是求entity mention中每个词的向量的均值。
Context representation:
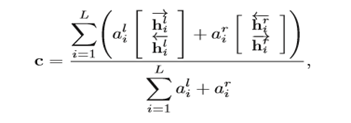
al i 、ar i 分别表示上文的注意力和下文的注意力。
注意力机制:
文章考虑了不同的注意力机制。
(1)语义注意力机制(Semantic Attention),就是考虑上下文信息的权重,由自身的语义信息来计算所占的比重,类似于self-attention:
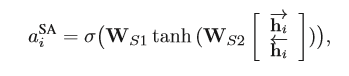
WS1 、WS2是多层感知机的参数矩阵,这里的注意力是跟句子中的实体无关的,只是计算某个实体上下文的注意力。
(2)实体注意力机制(Mention Attention),因为要考虑的是实体表示的类别,那么也可以计算实体表示所关注的重点在什么地方。
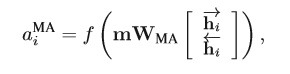
m是指句子中的实体词向量的均值,WMA是双线性参数矩阵。
(3)知识注意力机制(Knowledge Attention),知识图谱不仅包含了实体,同时还有实体之间的关系信息,这点也是十分重要的,因此作者使用了知识图谱中表示关系的方法TransE来处理知识图谱中的关系表示,并将其应用到注意力机制中。
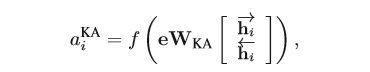
实体向量的表示由实体词向量的均值变为了entity embedding,WKA是双线性参数矩阵,h是当前实体的上下文embedding。
Type Predictor:该部分是一个两层的全连接神经网络。激活函数采用sigmiod,Wy1 、Wy2是多层感知机中的参数矩阵,ti 是当前实体预测的第i个type,θ代表模型中所有的参数。
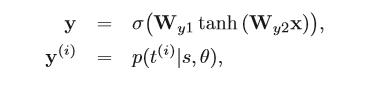
激活函数采用sigmiod,Wy1 、Wy2是多层感知机中的参数矩阵,ti 是当前实体预测的第i个type,θ代表模型中所有的参数。
目标函数:最后使用二分类的交叉熵作为损失函数,因为每一个实体表示的类别可能不止一个,这可能是一个多分类问题,因此作者在每个类别上都是用了二分类的交叉熵,最后将所有的全都加起来作为最终的损失函数。
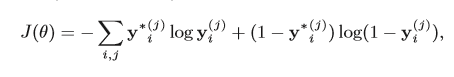
y* 真实类型,y代表预测类型。
实验:
欢迎关注博主的公众号!公众号不定期更新机器学习、深度学习、自然语言处理的干货~
