一、概述
首先:聚类算法是无监督学习算法;一般构建用户兴趣属性画像等可应用聚类算法;而一般的分类算法是有监督学习,基于有标注的历史数据进行算法模型构建
定义:对大量未知标注的数据集,按照数据内部存在的数据特征将数据集划分为多个不用的类别,使得类别内的数据比较相似,类别间的数据相似度较小。重点是计算样本之间的相似度,有时候也称为样本间的距离。
二、常用的距离公式:
1、闵可夫斯基距离公式,距离越近代表越相似,也是最常用的距离公式

当p为1的时候是曼哈顿距离(Manhattan),因为曼哈顿是城市,所以也称为城市距离;
当p为2的时候是欧式距离(Euclidean),一般都用这个距离
当p为无穷大的时候是切比雪夫距离(Chebyshev),试想当存在|x0-y0|比其他项都大时,即使开根号,其占比依然最大;
以上三个距离的具体表达式如下:

标准化欧式距离(Standardized Euclidean Distance):
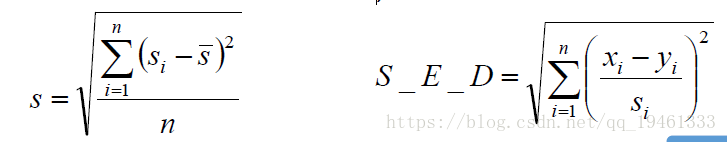
2、夹角余弦相似度(Cosine),夹角越小越相似,常用于文本识别,比如新闻的挖掘
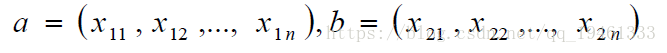
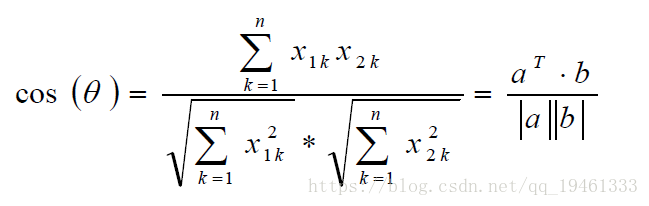
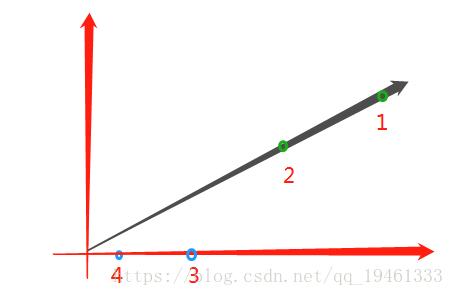
举例:
文本1中词语a,b分别出现100,50次,向量表示为(100,50)
文本1中词语a,b分别出现100,50次,向量表示为(100,50)
文本2中词语a,b分别出现50,25次,(50,25)
文本3中词语a,b分别出现10,0次,(10,0)
文本4中词语a,b分别出现2,0次;(2,0)
可以得知,1,2点向量平行(词频比例相同),3,4点向量平行,那么是不是可以判断1、2文本更相似,3,4文本更相似呢?
3、KL距离(相对熵):用的很少
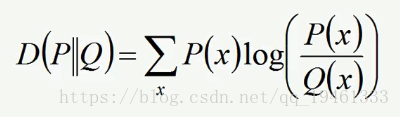
4、杰卡德相似系数:
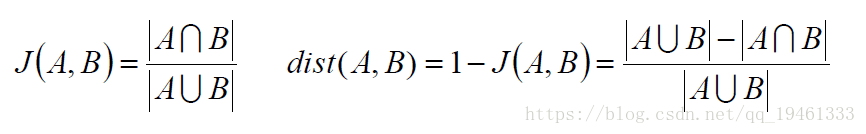
比如,A与B完全相同,则A交B=A并B,则J(A,B)=1
dist(A,B)就是距离,距离越小,则越相似。
5、Pearson相关系数,用协方差表示:
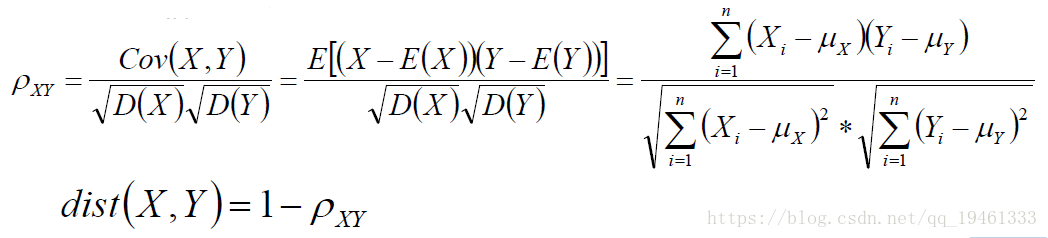
三、聚类的思想:
给定一个有M个对象的数据集,构建一个具有k个簇(类别)的模型,其中k<=M(类别数肯定小于样本数)。满足以下条件:
- 每个簇至少包含一个对象
- 每个对象属于且仅属于一个簇(其实是可以有有力状态的样本的,即既属于类别A又属于类别B)
- 将满足上述条件的k个簇成为一个合理的聚类划分