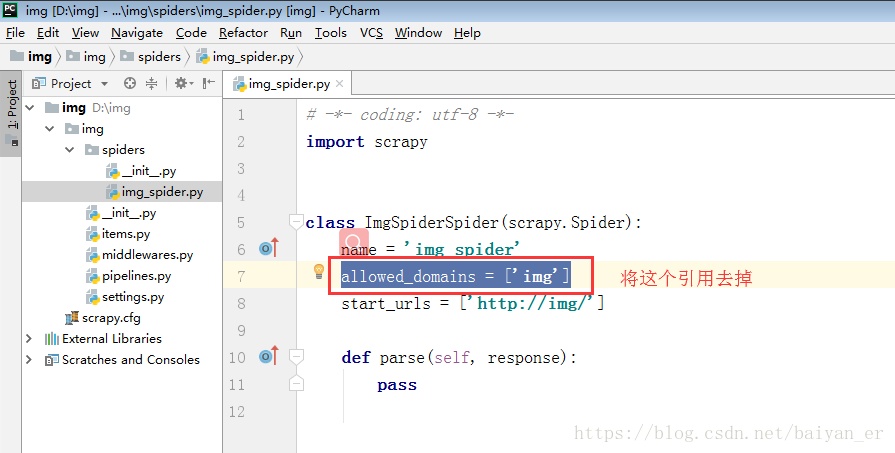
首先创建项目:

创建完成后pycharmy打开项目:
我们需要爬的是范冰冰的图片:
先在网站上分析下,图片在网页上向下拉,一直加载,用的是ajax异步加载图片,所以在爬的时候,需要ajax的地址
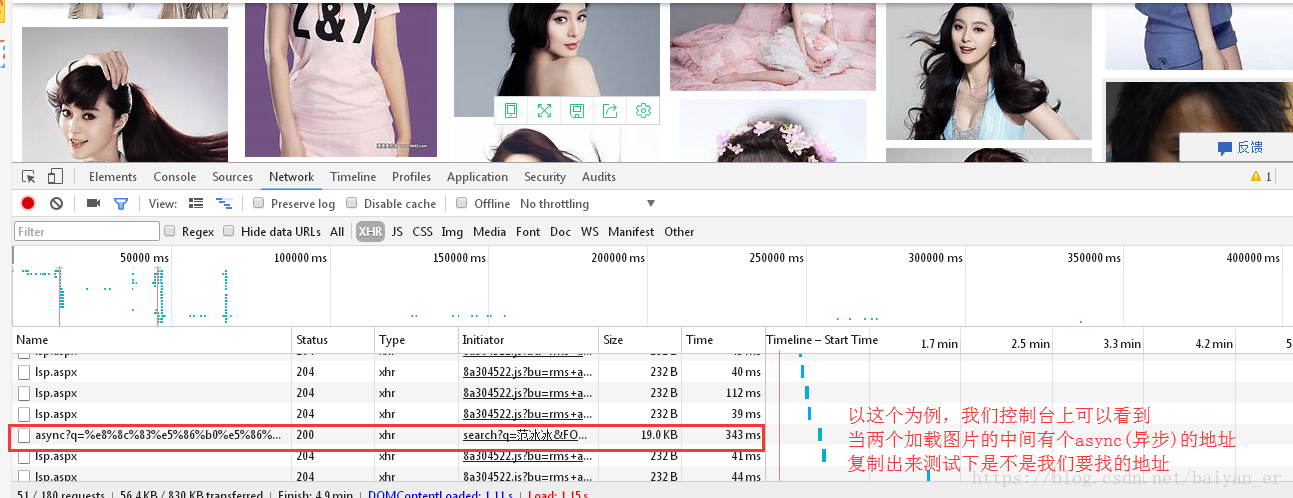

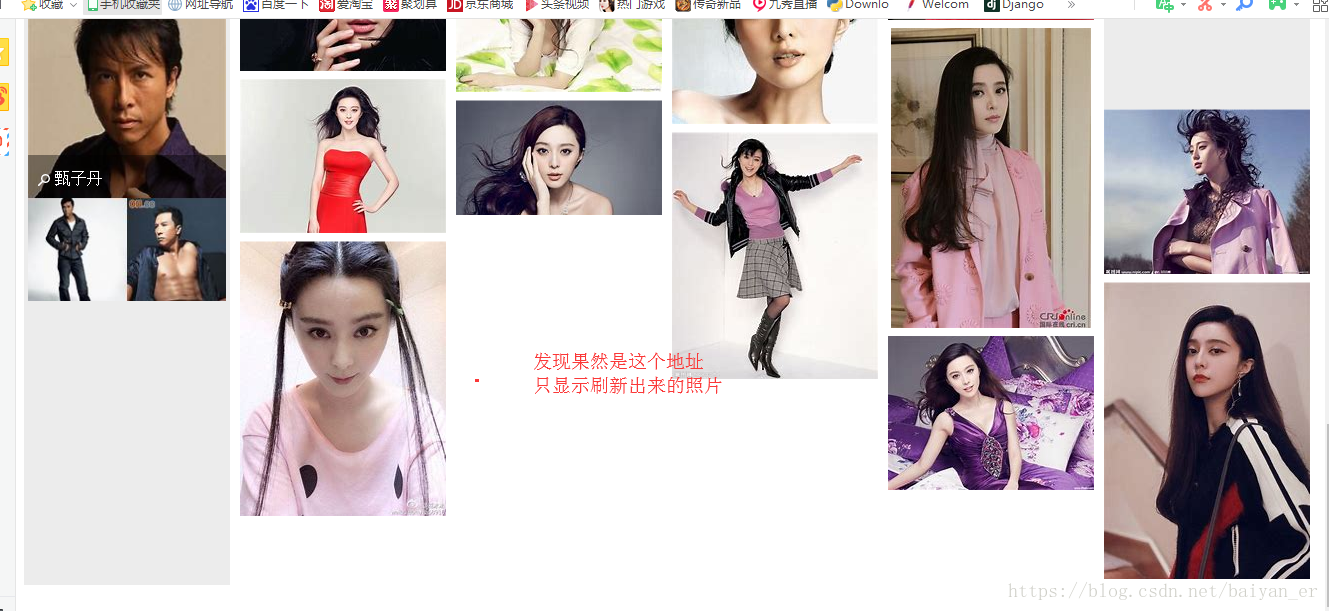
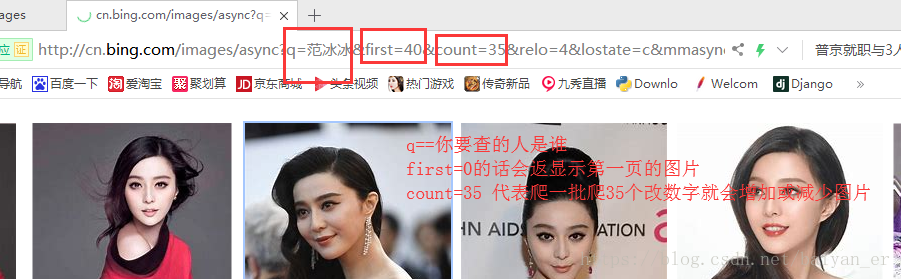
接下来爬取图片下载以500为例,这有可能有些地方下载不下来,现大爬的地址确定下来了
首先找到单个图片的地址

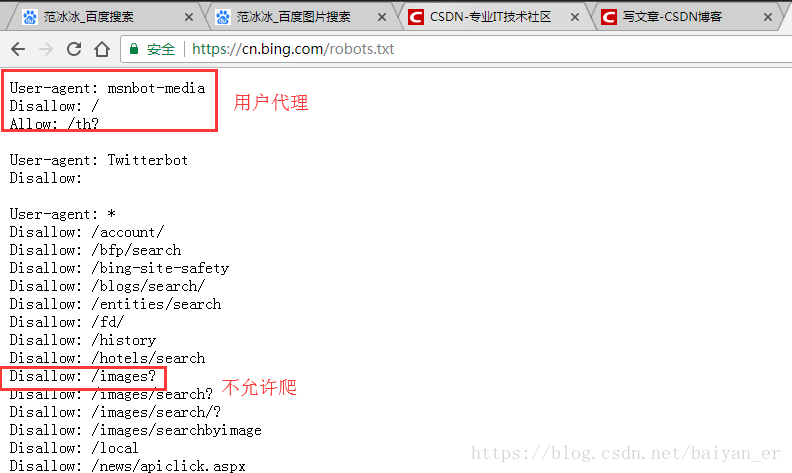
我们爬的地址是带images

但又想爬(只是做性练习 )
看官网上有个downloading and processimg files ang images说提供了一个可重用的项目管道,下载文件的附件,或一个图片元素,如果不做高级的处理,已经满足了你想做的事情。两个管道,一个是下载内容多媒体。下载的内容存到亚马逊,谷歌,本地(指定存储的位置)。下边还说,图片管道提供了额外函数,格式转换,缩略图,重缩图片大小等等提代长用的功能 。使用文件管道,和使用图片管道是一样的,比如使用文件管道,不需要写管道代码,只需要定义item,item包含两个成员变量_urls,files在item中应用,把下载的内容赋值给urls,这个集全包含了所有要下载文件的url地址,管道会读取这些urls,并使用资源调试器下载的这些资源保存在files中。
接着就会对files中的内容进行存储,图片管道非常像files,不同是成员变量由_urls改成img,files改成imges就可以使用图片管道。


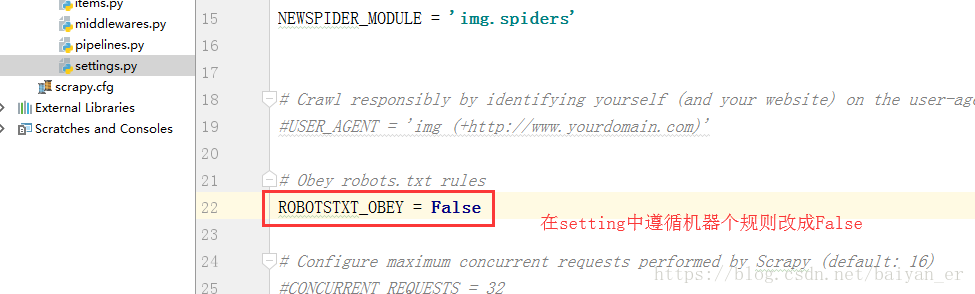
写上以后管道并不会起作用,因为参数不够,然后配置,图片存储的有效路径,如果不设置,管道将被禁用

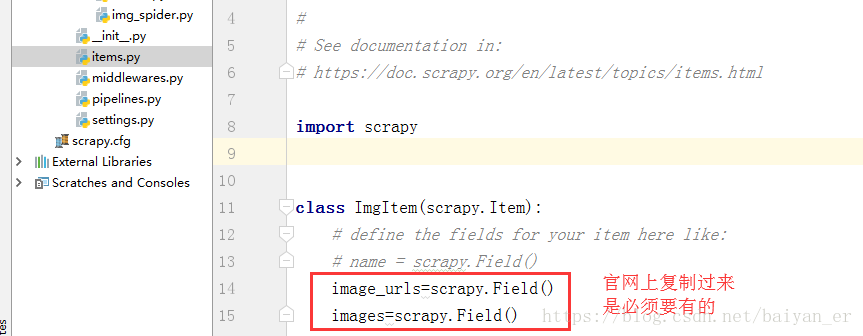
下边必须做个item.py文件中:
接下来要在蜘蛛中:
import scrapy
from img.items import *
class ImgSpiderSpider(scrapy.Spider):
name = 'img_spider'
start_urls = ['http://cn.bing.com/images/async?q=%e8%8c%83%e5%86%b0%e5%86%b0&first=43&count=35&relo=4&lostate=c&mmasync=1&dgState=c*6_y*1538s1642s1672s1593s1480s1630_i*40_w*206&IG=7349FD4BE39544F7A20B678E8BA6D468&SFX=2&iid=images.5747']
def parse(self, response):
#得到列的所有ul
uls = response.css("ul.dgControl_list")
#循环遍历每一个ul
for ul in uls:
#得到ul中class是mimg的img标签
#imgs是一个数组,是一个一个链接
imgs=ul.css("img.mimg::attr(src)").extract()
#创建item对象
item=ImgItem()
#下方是一系列下载的地址
item['image_urls']=imgs
#下方这个信息会返回settings中
yield item

现在下载的比较少,想多下载一些图片:
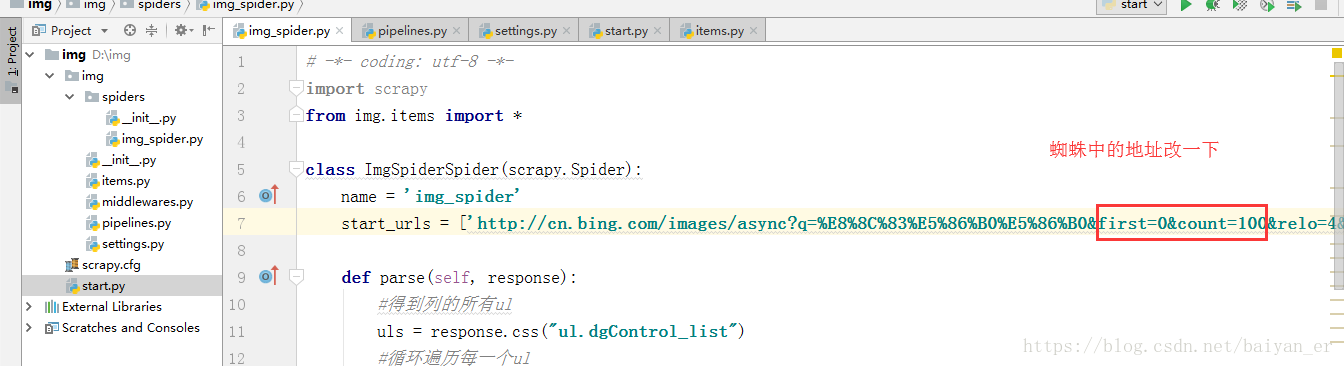
改下蜘蛛文件:
if self.page_index <=10:
next_page="http://cn.bing.com/images/async?q=%E8%8C%83%E5%86%B0%E5%86%B0&first={0}&count=100&relo=4&lostate=c&mmasync=1&dgState=c*6_y*1538s1642s1672s1593s1480s1630_i*40_w*206&IG=7349FD4BE39544F7A20B678E8BA6D468&SFX=2&iid=images.5747".format(self.page_index*90)
self.page_index = self.page_index + 1
yield response.follow(next_page,self.parse)



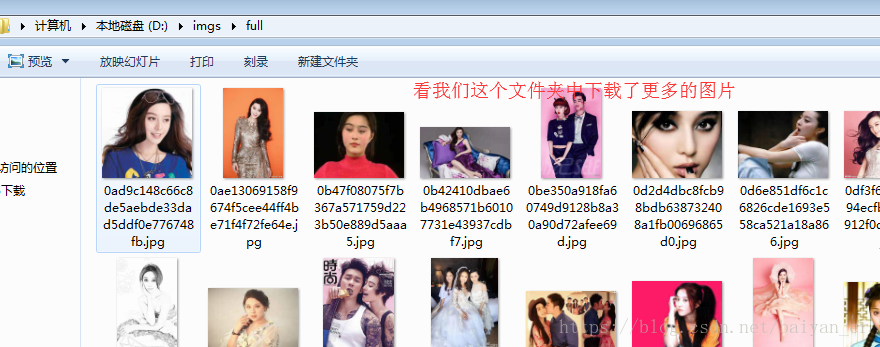
简单的爬取图片完成了