-
用scrapy写一个爬取百度贴吧的爬虫,以壁纸吧为例。
-
进入壁纸吧,审查元素,找到所有的帖子链接,获取帖子链接
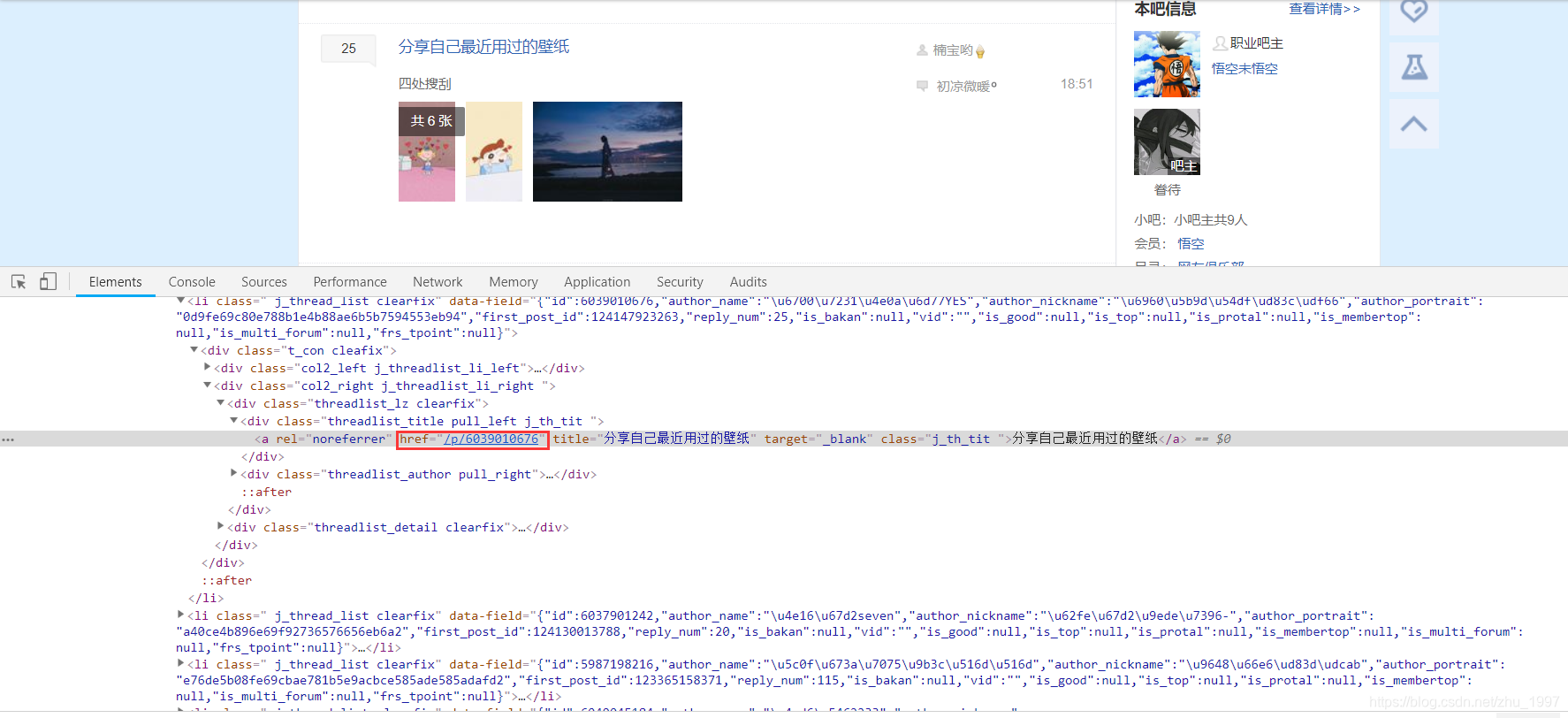
代码:
results = response.css(".threadlist_lz.clearfix a::attr(href)").extract()
- 设置item
import scrapy
class tiebaItem(scrapy.Item):
# define the fields for your item here like:
# 图片链接
url = scrapy.Field()
# 帖子标题,作为文件夹名存储本帖子的图片
title = scrapy.Field()
- 进入帖子审查元素,获取帖子内所有图片的链接和帖子名称,存入item
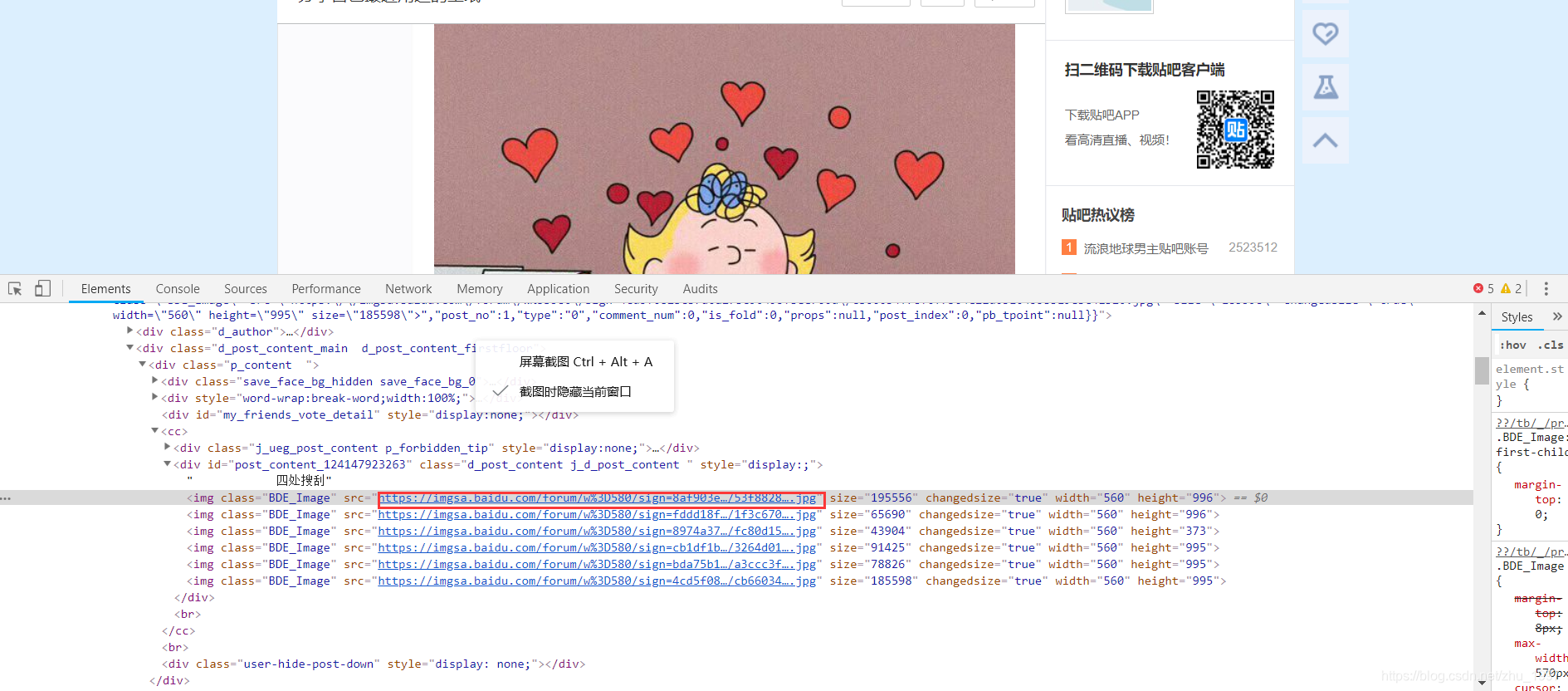
代码
item['url'] = response.css('.BDE_Image::attr(src)').extract()
item['title'] = response.css('h3::attr(title)').extract_first()
- 因为帖子内的页面不止一页,所以这里选择获取获取当前的页数和总页数,如果当前页不是最后一夜,则继续解析下一页,直到最后一页
cur_page = response.css('.l_pager.pager_theme_4.pb_list_pager span::text').extract_first()`
last_page = response.css('.l_posts_num .l_reply_num span::text').extract()[1]
if cur_page and last_page and int(cur_page) < int(last_page):
next_url = url_page + '?pn={page}'.format(page=str(int(cur_page)+1))
yield Request(url=next_url, callback=self.image_parse)
- 通过ImagesPipeline下载所有照片
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
from scrapy import Request
class TiebapicPipeline(object):
def process_item(self, item, spider):
return item
class ImagesPipeline(ImagesPipeline):
'''
获取item的ulr,生成Request请求,加入队列,等待下载,
同时通过request.meta携带文件夹名
'''
def get_media_requests(self, item, info):
for i in item['url']:
yield Request(i, meta={'item': item})
'''
处理每张照片,返回当下request对象路径和文件名
'''
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
title = request.meta['item']['title']
path = title+'/'+file_name
return path
'''
单个item完成下载处理,通过判断文件路径是否存在,不存在说明下载失败,剔除下载失败的图片
'''
def item_completed(self, results, item, info):
image_path = [x['path'] for ok, x in results if ok]
if not image_path:
raise DropItem('Item contains no images')
#item['image_paths'] = image_path
return item
- 修改setting, 启用ImagesPipeline
ITEM_PIPELINES = {
'tiebapic.pipelines.ImagesPipeline': 300,
}
完整代码:https://github.com/ZhuLinsen/Scrapy/tree/master/tiebapic
个人博客:zhulinsen.github.io 欢迎访问!