今天写的是一篇关于ItemLoader的基本用法的一个点睛解释。
爬取网站:妹子图上所有的图片。链接可以打不开(直接用你的浏览器输入(www.meizitu.com))
首先贴几张图,是网站的首页和详情页的结构
首页是一个大图的形式呈现

详情页由很多小的图片组成的类似九宫格的形式
我们的目标就是要爬取首页和详情页(15页)的全部图片
当然,我们在这里肯定要用到我们的新知识,用ItemLoader进行数据的提取和对item的填充。
爬虫类型:CrawlSpider爬虫
我们知道用CrawlSpider对网页的翻页是很方便的,直接定义Rule(不包含call参数)就可以实现自动化的翻页了,那么,我们的首页就要用parse_start_url方法进行提取了。
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.contrib.loader import ItemLoader
from jj.items import JjItem
class CrawlspiderSpider(CrawlSpider):
name = 'crawlspider'
allowed_domains = ['meizitu.com']
start_urls = ['http://www.meizitu.com']
def parse_start_url(self, response):
# 用于提取首页的图片
Loader = ItemLoader(item=JjItem(),response=response)
Loader.add_xpath('picture_urls','.//*[@id="picture"]/p/a/img/@src')
# 这样就图取出来了该网页所有的图片链接,也就是图片链接以一个列表的形式收集在一个字段里面
yield Loader.load_item()
rules = (
Rule(LinkExtractor(restrict_xpaths='.//*[@id="subcontent clearfix"]/div[2]/span/a'),follow=False),
# 用于遍历所有的小标题如:颜值控,萌妹等
Rule(LinkExtractor(restrict_xpaths='.//*[@id="wp_page_numbers"]/ul/li/a',unique=True),callback='parse_item', follow=False),
# 对上一个Rule下载下来的所有页面提取各个小标题的翻页链接(每个小标题好象有15页左右)
)
# 上面规则提取每个页面的其他页面的链接,并不进行跟进(因为一个页面上就能提取出所有详情页的链接,所以不需要进行跟进)
def parse_item(self, response):
Loader = ItemLoader(item=JjItem(), response=response)
Loader.add_xpath('picture_urls', './/*[@id="maincontent"]/div/ul/li//a/img/@src')
# 将一个详情页的所有的图片链接都放到一个字段里面
print(Loader.get_collected_values('picture_urls'))
yield Loader.load_item()上面是我们的爬虫程序,很简单。所以用一个parse_start_url,爬取了首页上的所有的图片,并保存到了picture_urls字段中,也就是说,用一个字段保存了一个页面上所有的链接,然后自动调用图片的调度器和下载器对图片进行下载。
用parse_item方法对详情页的内容进行了提取,是同样的。在第二个方法里我用ItemLoader的get_collected_values方法获得了进入输入处理器之前的列表,算是做一个测试把。
其他爬虫文件的配置都不难,你们可以通过学习我前面几篇文章的内容自己就可以做出来了。
在这里我们明白了两点内容:
一、item的一个字段不但接受一个str还可以接受一个列表(实际上,一个item字段可以接受任何python类型的数据,不只上面两个)
二、图片链接字段只接受一个列表(这与一有点冲突,记住就好了。)
在前面的内容,我还强调了说,图片链接字段只接受列表(即使只有一个图片),这里就讲明了原因,在某种程度上是为了ItemLoader服务的。
这里和前面的item不一样的在于,前面几篇的item一个字段往往只接受了一个值,通过循环的方式每次返回一个值,而这里一个item字段接受了一个列表的数据。
进过上面的程序的运行,我们的成果给祢看一下呀!
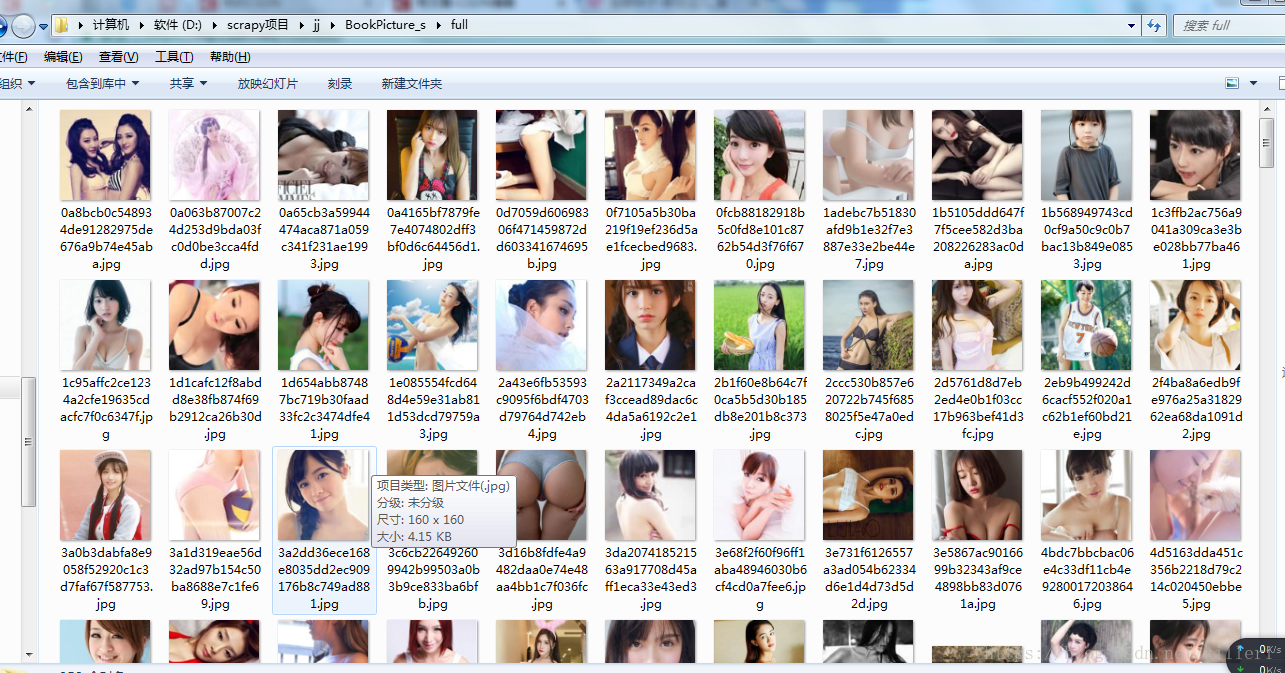
注意:本博客不涉黄!!!!!!!!!!!!!!!!!!
关注一波?
这个程序只是对一个页面上的主体图片进行了提取,那
这些链接的内容该怎么提取呢,其实很简单。我给一个思路:
增加一个Rule((allow=’http://www.meizitu.com/a/\d+?.html’,unique=True),callback=”,follow=True)
这样我们就能够提取到所有已经下载到的页面的如正则相匹配的链接并下载页面内容,然后在用回调函数解析页面就可以了!