这里我们爬取的是360图片
链接为"http://image.so.com/z?ch=photography"
随着页面下滑,他会自动加载图片,我们能推断出这使用的是Ajax加载方式
我们打开开发工具,选择XHR

我们观察可以发现sn这里是以30的倍数增长
我们可以使用一个for循环来进行url的更新
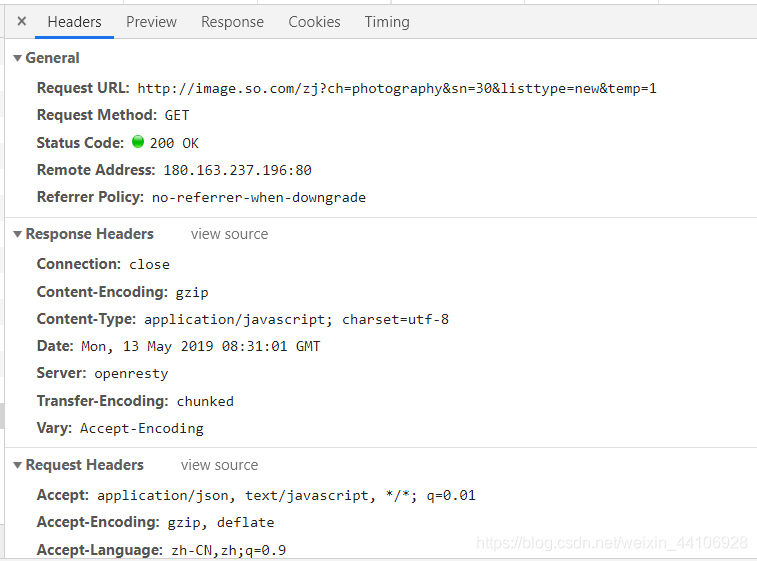
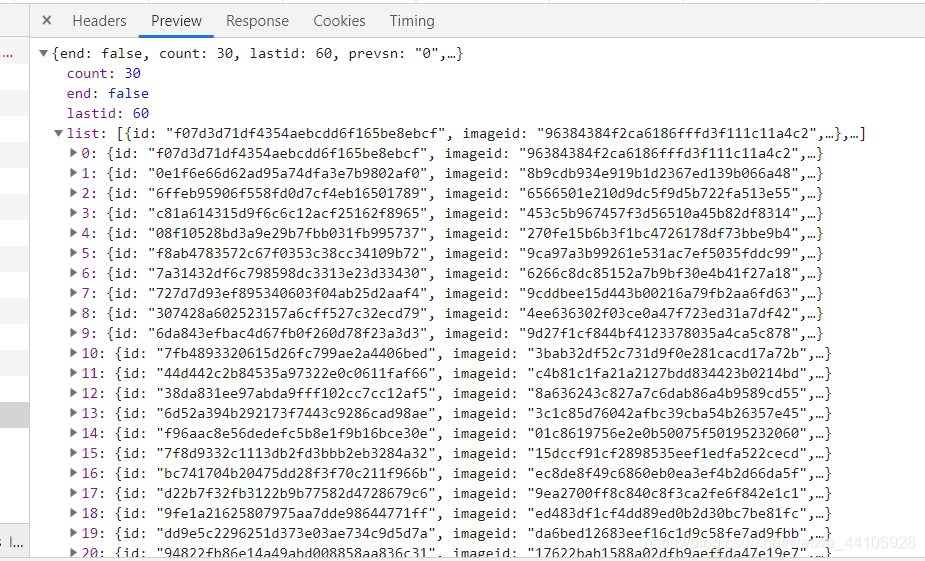
我们所要爬取的图片信息都在这list里面
首先我们创建一个scrapy项目,在你想创建项目的路径下shift + 右键
在此处打开Powershell
scrapy startproject images360
cd images360
scrapy genspider images images.so.com
然后在settings.py里设置一些常量
MAX_PAGE = 50
BOT_NAME = 'images360'
SPIDER_MODULES = ['images360.spiders']
NEWSPIDER_MODULE = 'images360.spiders'
MONGN_URI = 'localhost'
MONGO_DB = 'images360'
IMAGES_STORE = 'D:\pythonProject\Spiderr\Chapter13\images360\images360\images'
ROBOTSTXT_OBEY = False
本次我们使用Mongodb来存储url等信息,所以这里定义一下变量
IMAGES_STORE是我们等等利用scrapy自带的组件进行图片下载时,图片存放的路径
在images.py 也就是爬虫主程序写如下代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request, Spider
from urllib.parse import urlencode
import json
from images360.items import ImageItem
class ImagesSpider(scrapy.Spider):
name = 'images'
allowed_domains = ['images.so.com']
start_urls = ['http://images.so.com/']
def start_requests(self):
data = {'ch':'photography', 'listtype':'new'}
# http://images.so.com/zj?ch=photography&sn=30&listtype=new&temp=1
base_url = 'http://images.so.com/zj?'
for page in range(1, self.settings.get('MAX_PAGE')+1):
data['sn'] = 30 * page
params = urlencode(data)
url = base_url+params
yield Request(url, self.parse)
def parse(self, response):
# self.logger.debug(response.text)
result = json.loads(response.text)
for image in result.get('list'):
item = ImageItem()
item['id'] = image.get('imageid')
item['url'] = image.get('qhimg_url')
item['title'] = image.get('group_title')
item['thumb'] = image.get('qhimg_thumb_url')
yield item
我们用urlencode进行编码,进行url的更新,并存入Request的调度队列
在parse方法里
我们用json格式读出response
也就是网页源代码
然后按照前面图片的顺序来进行内容的获取
注意这里最后要yield item,作为生成器
然后就是处理我们的存放数据部分了
在Pipelines.py里
import pymongo
class MongoPipeline(object):
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DB')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
name = 'images'
self.db[name].insert(dict(item))
return item
def close_spider(self, spider):
self.client.close()
from scrapy import Request
from scrapy.exceptions import DropItem
from scrapy.pipelines.images import ImagesPipeline
class ImagePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield Request(item['url'])
def file_path(self, request, response=None, info=None):
url = request.url
file_name = url.split('/')[-1]
return file_name
def item_completed(self, results, item, info):
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem('Image Download Failed')
return item
第一个类我们实现了mongodb的存储,将item转换为字典形式并插入到数据库里
第二个类是实现了我们图片的下载
image_paths那里是一个列表推导式的写法
相当于
for ok, x in results:
if ok:
print(x['path'])
因为results是一个列表,里面元素是元组,包含下载信息,比如是否ok
我们判断ok这个字段对下载失败的元素raise DropItem错误
最后在settings.py加上一个字段来表示Pipelines的优先级
ITEM_PIPELINES = {
'images360.pipelines.MongoPipeline':300,
'images360.pipelines.ImagePipeline':301
}
参考自崔庆才《python3网络爬虫实战》