随着代理IP技术的普及,爬虫的使用也变得简单起来,许多企业和个人都开始用爬虫技术来抓取数据。那么今天就来分享一个爬虫实例,帮助你们更好的理解爬虫。下面我们用程序模拟Ajax请求,将我的前10页微博全部爬取下来。
首先,定义一个方法来获取每次请求的结果。在请求时,page是一个可变参数,所以我们将它作为方法的参数传递进来,相关代码如下: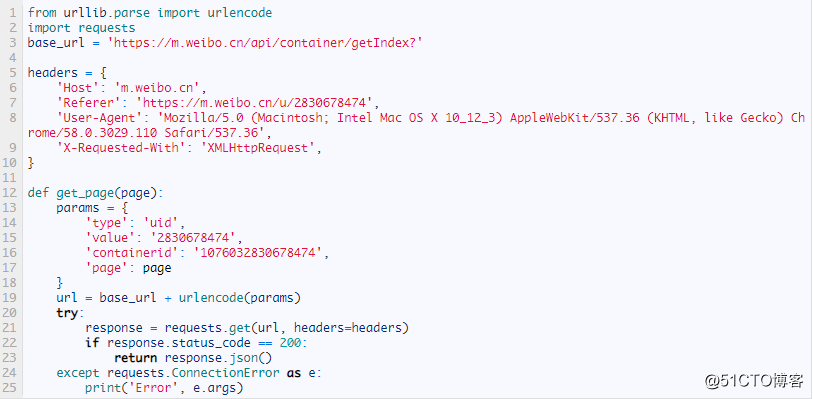
首先,这里定义了base_url来表示请求的URL的前半部分。接下来,构造参数字典,其中type、value和containerid是固定参数,page是可变参数。接下来,调用urlencode()方法将参数转化为URL的GET请求参数,即类似于type=uid&value=2830678474&containerid=1076032830678474&page=2这样的形式。随后,base_url与参数拼合形成一个新的URL。接着,我们用requests请求这个链接,加入headers参数。然后判断响应的状态码,如果是200,则直接调用json()方法将内容解析为JSON返回,否则不返回任何信息。如果出现异常,则捕获并输出其异常信息。
随后,我们需要定义一个解析方法,用来从结果中提取想要的信息,比如这次想保存微博的id、正文、赞数、评论数和转发数这几个内容,那么可以先遍历cards,然后获取mblog中的各个信息,赋值为一个新的字典返回即可:
这里我们借助pyquery将正文中的HTML标签去掉。
最后,遍历一下page,一共10页,将提取到的结果打印输出即可:
另外,我们还可以加一个方法将结果保存到MongoDB数据库:
这样所有功能就实现完成了。运行程序后,样例输出结果如下:
查看一下MongoDB,相应的数据也被保存到MongoDB,如下图所示。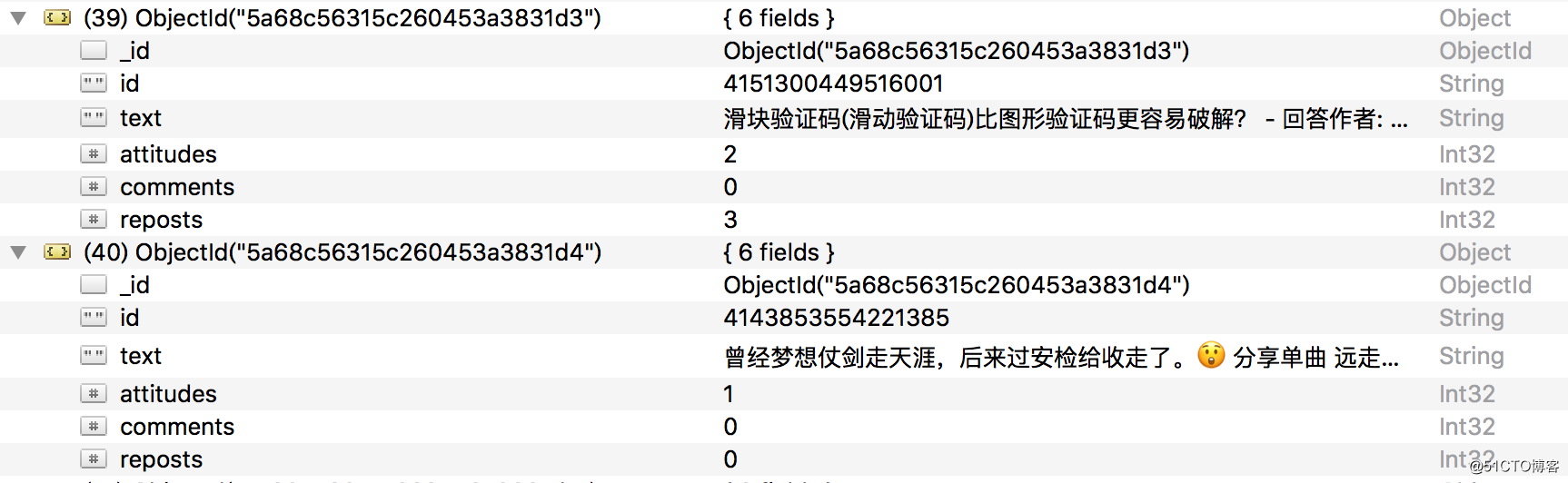
这样,我们就顺利通过分析Ajax并编写爬虫爬取下来了微博列表。通过这个实例,我们主要学会了怎样去分析Ajax请求,怎样用程序来模拟抓取Ajax请求。