尝试Ajax数据爬取微博
作者:墨非墨菲非菲
前言
时光荏苒,岁月如梭。在不经意间,一天的时光化作一分一秒,毫无动静的却电光火石般滑过指缝,再难寻觅。转眼又到了周五,又是哪个熟悉的周五,放学铃一响,瞬间人去楼空。我独自坐在教室的最后一排,靠着后窗,独守空门。人群的一合一散,一动一静,让人踌躇难安,举止无状。静静地望着楼下那颗银杏树,人在二楼教室,时间定格在2013年11月的某个周五,思绪却早已飘向了远方。
上面一段引用了当年极其矫揉造作的日记。到这里,可能好事的读者就要问了,请问这位上下,那您的思绪究竟飘到了哪里呢?我要说,既不是张骞出使的塞外边疆的豪壮,也不似田维心心念念半亩花田文静。没错,那个懵懂的年轻人想到了今天的主题————爬取Ajax数据。
一. 简要介绍Ajax
Ajax 即“Asynchronous Javascript And XML”(异步 JavaScript 和 XML),是指一种创建交互式、快速动态网页应用的网页开发技术,无需重新加载整个网页的情况下,能够更新部分网页的技术。
通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
翻译一下,网页的html框架就像一个出租房,它里面定义了客厅,厨房和卫生间,但是里面究竟放什么不管。这时,来了一个客户,装饰了客厅,厨房和卫生间(JavaScript)。当下一个客户来时,依然可以用这个空的出租屋来装饰她的房间(网页前端显示)。数据通过Ajax请求和传输,并最后通过网页加载和渲染出来,这样数据的位置(XHR)和格式就清楚出了。
二. 面向对象编程
整篇代码的完成建立在许多函数之上的。把每一个单独的功能封装为一个方法(也叫函数),并调用,面向一个个单独的对象。这里的对象,不是你的对象,当然也不是我的对象6_6。面向对象有一个显而易见的好处,在参数修改的时候非常方便,之后的维护升级只需要在函数内部进行处理,不会牵一发而动全身体。举个例子,同样要把大象放进冰箱里面(大象内心os:我做错了什么?)面向过程编程需要:打开冰箱;放入大象;关上冰箱。而面向对象编程需要:定义打开冰箱的方法;定义放入大象的方法;定义关上冰箱门的方法;定义主函数(main())并调用以上的方法。
这里,看起来面向对象编程要复杂太多。但是,当你换到装一个新的大象的时候,面向过程编程就会出现:大象(我要我的Hair冰箱_),改完后,关冰箱门(从新定义关Hair冰箱门的方法)而面向对象编程只需要在主函数里面修改新的大象,新的冰箱。这就是方便之处。
三. 步骤实现
1.写一个步骤
打开weibo主页后,显示每一条微博,下拉到底刷新。研究源代码,发现信息并不在html里面,猜测应该是Ajax动态加载。打开XHR,找到了每一条微博的地址。于是,大概的构思就出来了:
- :获取主页,解析json,找到每一条动态的url。
- :获取一条动态,解析json,得到文本,时间,设备,转发评论点赞数和前五条评论。
- :储存。
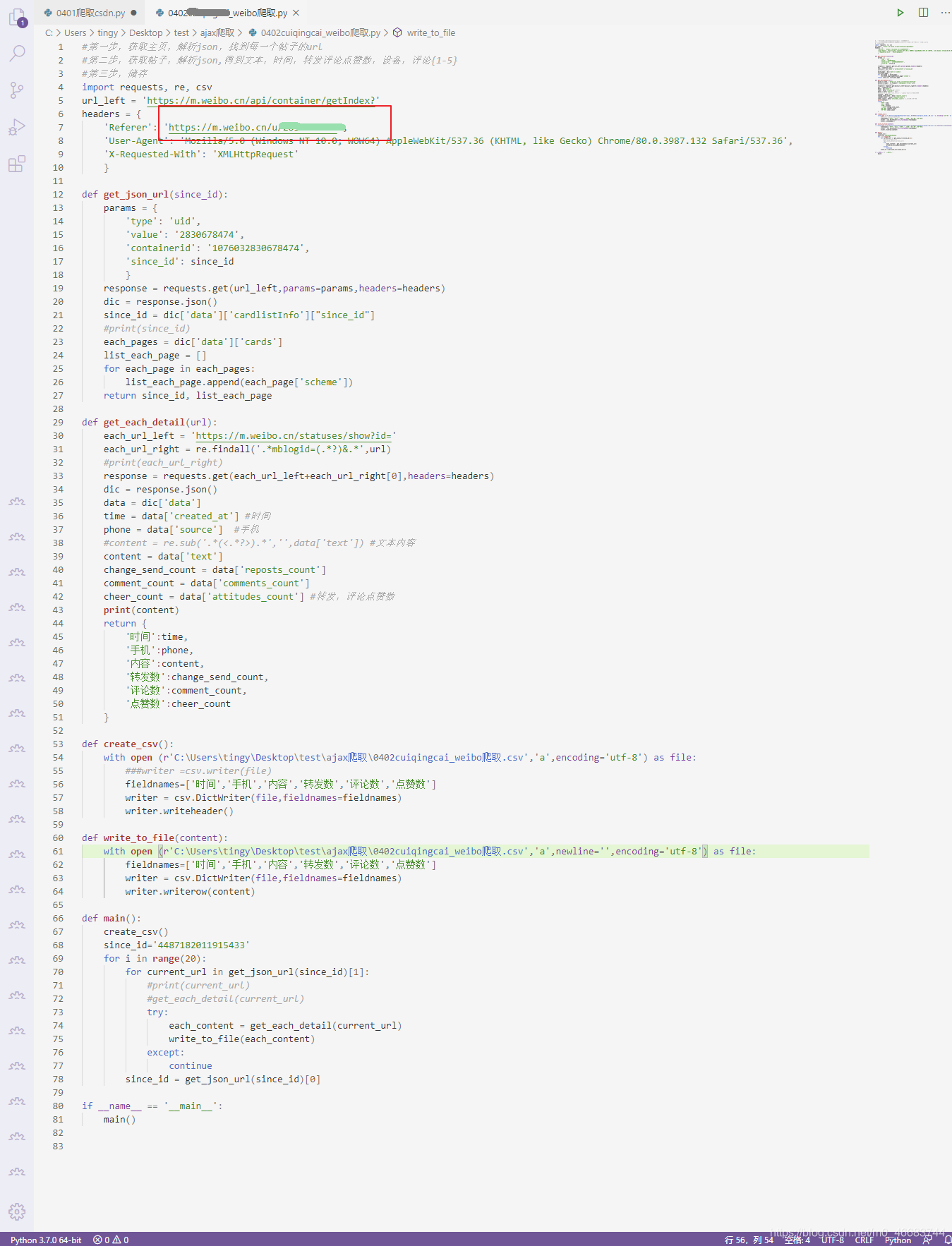
2.导入库,主页和Headers
先导入requests,之后需要什么再往里面添加就行了。
3.定义方法,获取每一条动态的网址
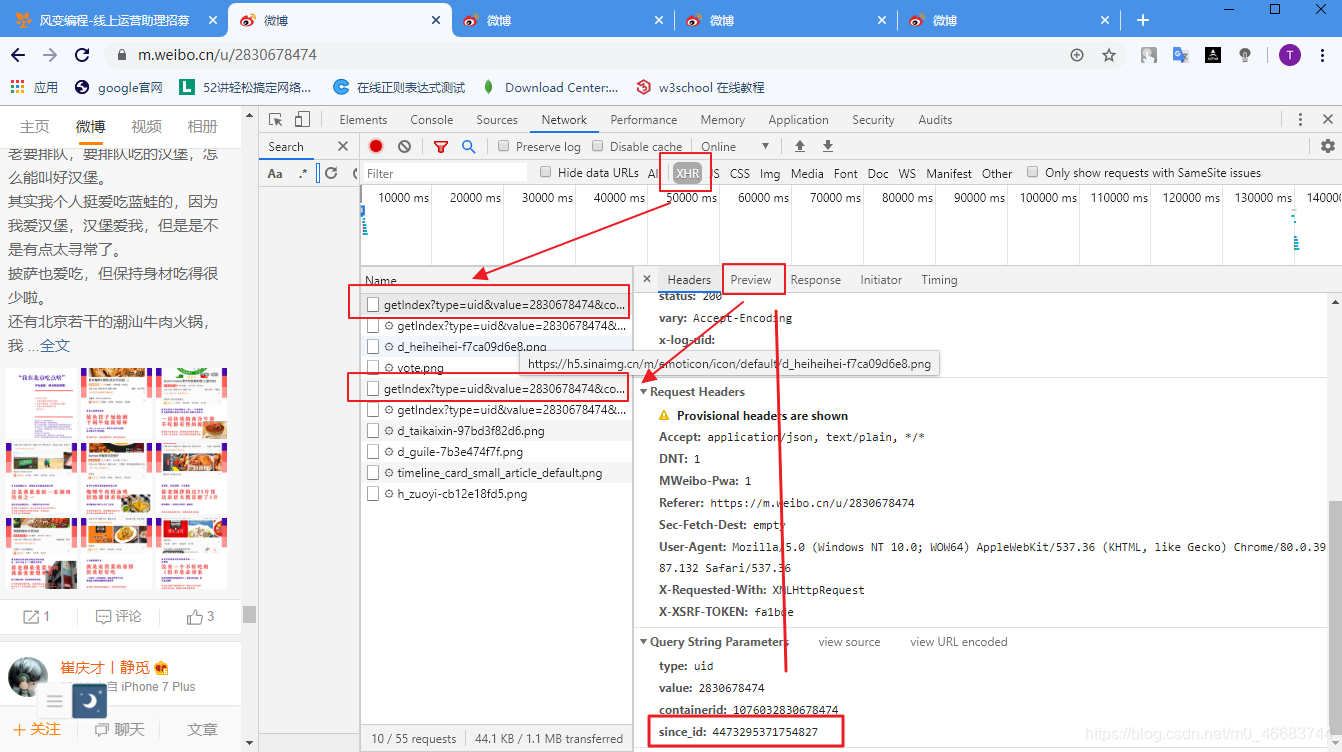
这里发现了一个巨大的问题!!!原以为微博会用offset=’/d’来切片不同的网页,结果我让我准备关电脑的是,出现了让我完全找不着规律的since_id,它的整个完整的url长这样:
urls = ['https://m.weibo.cn/status/IvxUIvnzi?mblogid=IvxUIvnzi&luicode=10000011&lfid=1076032830678474',
'https://m.weibo.cn/status/IyieDa0M1?mblogid=IyieDa0M1&luicode=10000011&lfid=1076032830678474',
'https://m.weibo.cn/status/Ix2jNtRNI?mblogid=Ix2jNtRNI&luicode=10000011&lfid=1076032830678474'
没错,所有的字段都一样,唯独这个mblogid完全找不到规律。
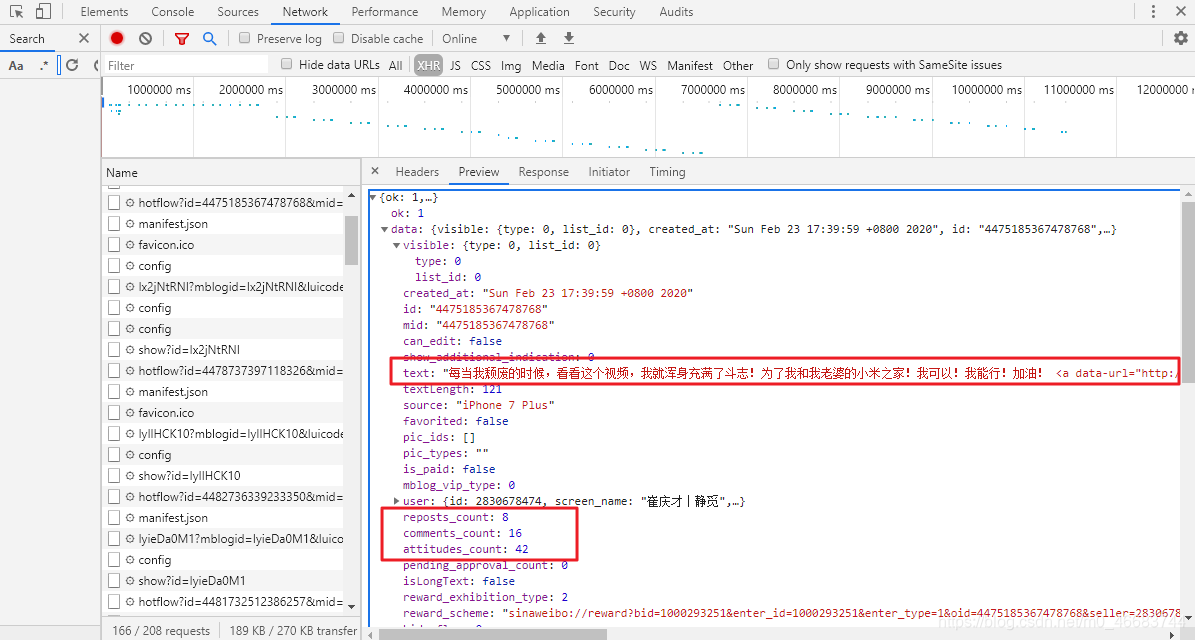
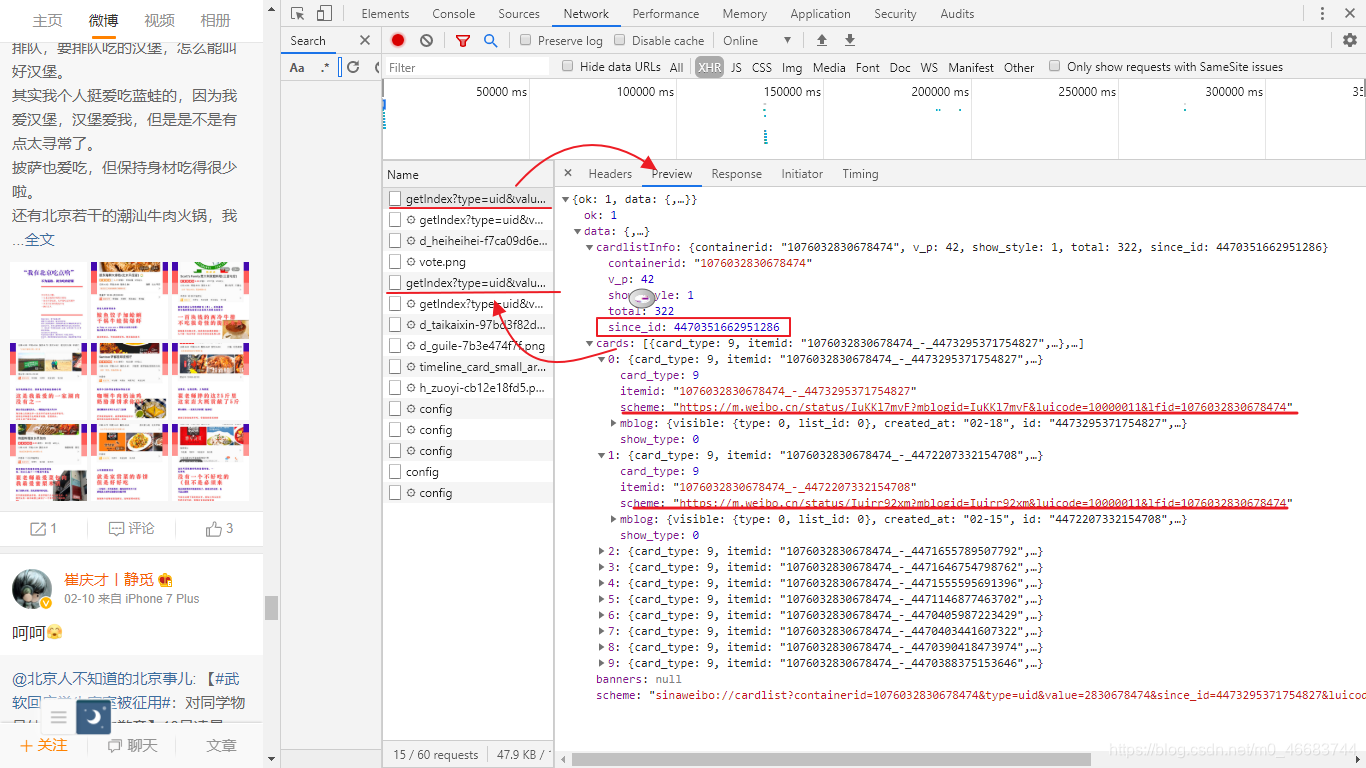
遂有面向谷歌和CSDN和ctrl+find找到了,原来它隐藏在每一页的data[‘cardlistInfo’][“since_id”]下面。问题解决了。
此时获取每一条动态的方法返回两个参数:since_id, list_each_page。
4.主函数里面循环前10页
先放入一个默认的参数(第一个url的参数)sence_id,for循环爬取20页,再次for循环取这一页的每一个动态的url。
5.定义方法,获取每一个动态的信息
信息是多种多样的并且散乱不堪,这个时候数据清洗和格式化就显得特别重要!在前面一文浅谈解析库XPath,bs4和pyquery中,没有提到regex,因为它实在复杂。然而,re确实操作字符串(string)的绝对利器,可以对字符串进行任何想到达到的操作。比如时间文本等等。这里需要提取mblogid的字段也就水到渠陈了,像这样:
import re
url = 'https://m.weibo.cn/status/IvxUIvnzi?mblogid=IvxUIvnzi&luicode=10000011&lfid=1076032830678474'
each_url_right = re.findall('.*mblogid=(.*?)&.*',url)
这一步没什么问题。唯独解析json的时候字典列表互相嵌套的特别仔细。
6.主函数main()里运行
试跑几次发现这里面会有错误的数据,会报错。后来加上了try…except字段以确保顺利的跑完全程。还有一个问题至今也没想明白,迭代列表后导入单个url之后为什么进入函数里面回事list,实在没搞明白,时间关系type()并打印后直接取索引值了。
7.储存csv
储存到excel中,但是没有相关的储存字典的方法。于是我就选取csv中的csv.DictWriter()方法。
第一次出现了每一次都写入一行header,糟糕,写表头一个方法,写content一个方法。
第二次出现了空行,百度之后发现需要在打开文件的时候加入" newline=’’ "
成功解决!
展示一下爬取后的excel结果。

四. 结束语
时间一晃而过,从周四中午11点到下午三点,所有的数据最后呈现在屏幕面前无疑是激动的,晚上抽时间整理了’尝试Ajax数据爬取微博.md’出来,算是分享个人的一点经验和心得。最后展示一下源代码。