原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 概述
在博文Python爬虫之微博评论数据的爬取(十)中,已经介绍了爬取移动端的用户评论。(关于微博的基本知识可以见博文微博爬虫基本知识了解(十一)),这篇文章主要介绍,Python爬取手机端的数据。手机端的数据加载时用Ajax技术,相关内容可以参考文章AJAX数据爬取基本认识及原理。废话少说,直接开始啦!!!!!
二、Ajax动态加载数据
首先呢,要先找到自己的cookie(了解cookie的作用和会话机制可参考博文:session和Cookies实现会话机制),这里就不赘述了。直接去认识,手机端的数据,是如何进行加载的,通过以下的图1翟天临的致歉信内容来认识(个人观点:人孰能无过,知错能改善莫大焉)。
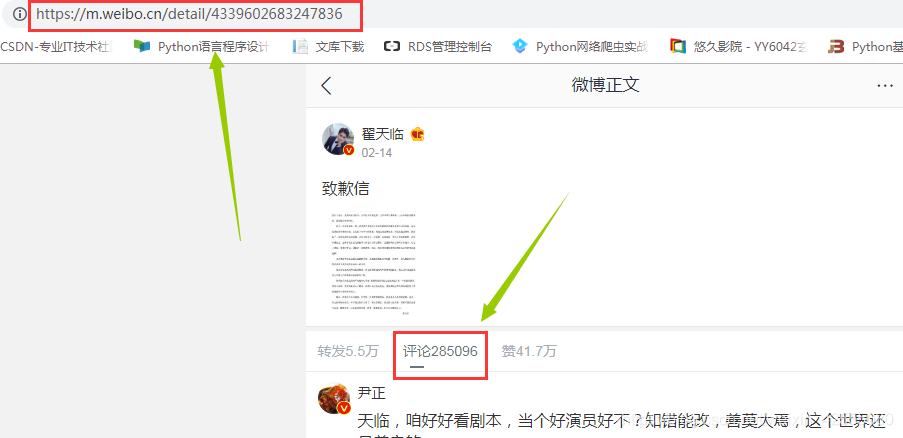
图1
F12打开开发者工具,Network—》XHR,筛选出所有的xhr文件,如下图2:在⚙config(绿色箭头)的xhr文件中可以找到自己的cookie、user-agent,包括传输方式等信息。在⚙hotflow?..(红色箭头)所指的文件中,来查看Request URL。

图2
接着,滑动页面的滚动条,发现加载了更多的⚙hotflow?..的xhr文件,如图3。将它们一一打开找到Request URL,进行对比。
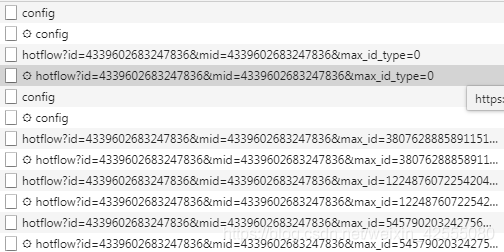
图3
Request URL: https://m.weibo.cn/comments/hotflow?id=4339602683247836&mid=4339602683247836&max_id_type=0
Request URL: https://m.weibo.cn/comments/hotflow?id=4339602683247836&mid=4339602683247836&max_id=3807628885891151&max_id_type=0
Request URL: https://m.weibo.cn/comments/hotflow?id=4339602683247836&mid=4339602683247836&max_id=1224876072254204&max_id_type=0
Request URL: https://m.weibo.cn/comments/hotflow?id=4339602683247836&mid=4339602683247836&max_id=545790203242756&max_id_type=0
发现只是max_id的值不同(实际上还有max_id_tpye也不同)。也就是说只要可以不断获取这个max_id的值,并不断的更新URL(url是由https://m.weibo.cn/comments/hotflow?用户id&midid&max_id&max_id_type组成),就可以知道将数据爬出来,如图4所示,这些数据包括:微博数据,个人信息,单条微博评论数据。选择preview—》data里面可以看到这些信息。
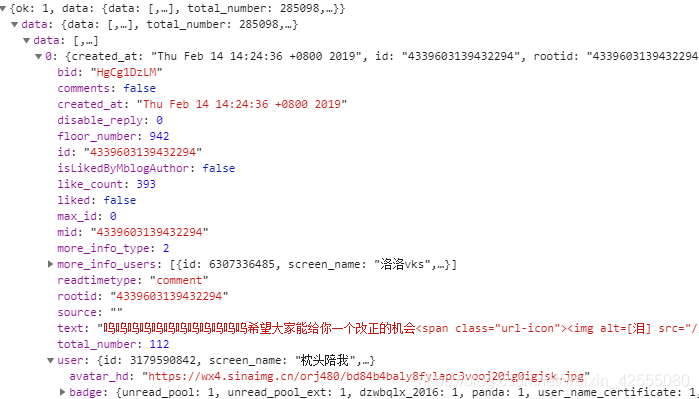
图4
言归正传,要想获得下一次的url,该从哪个地方得到这个max_id和max_id_type。实际上,在之前的返回的json文件的最后面有下一个的max_id和max_id_type。打开之前的⚙hotflow的preview,如下图5所示:
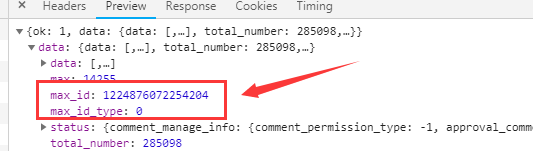
图5
这下子就找到了,可以拼接下一个url了,所以只要不断更新这个max_id和max_id_type就可以实现热评的多次爬取了。
三、代码及结果展示
# -*- coding: utf-8 -*-
import requests
import time
import os
import csv
import sys
import json
from bs4 import BeautifulSoup
import importlib
importlib.reload(sys)
# 要爬取热评的起始url
url = 'https://m.weibo.cn/comments/hotflow?id=4339602683247836&mid=4339602683247836&max_id='
headers = {
'Cookie': '请给出你的cookie',
'Referer': 'https://m.weibo.cn/detail/4312409864846621',
'User-Agent': '请给出你的user-agent',
'X-Requested-With': 'XMLHttpRequest'
}
def get_page(max_id, id_type):
params = {
'max_id': max_id,
'max_id_type': id_type
}
try:
r = requests.get(url, params=params, headers=headers)
if r.status_code == 200:
return r.json()
except requests.ConnectionError as e:
print('error', e.args)
def parse_page(jsondata):
if jsondata:
items = jsondata.get('data')
item_max_id = {}
item_max_id['max_id'] = items['max_id']
item_max_id['max_id_type'] = items['max_id_type']
return item_max_id
def write_csv(jsondata):
datas = jsondata.get('data').get('data')
for data in datas:
created_at = data.get("created_at")
like_count = data.get("like_count")
source = data.get("source")
floor_number = data.get("floor_number")
username = data.get("user").get("screen_name")
comment = data.get("text")
comment = BeautifulSoup(comment, 'lxml').get_text()
writer.writerow([username, created_at, like_count, floor_number, source,
json.dumps(comment, ensure_ascii=False)])
# 存为csv
path = os.getcwd() + "/weiboComments.csv"
csvfile = open(path, 'w',encoding = 'utf-8')
writer = csv.writer(csvfile)
writer.writerow(['Usename', 'Time', 'Like_count', 'Floor_number', 'Sourse', 'Comments'])
maxpage = 50 #爬取的数量
m_id = 0
id_type = 0
for page in range(0, maxpage):
print(page)
jsondata = get_page(m_id, id_type)
write_csv(jsondata)
results = parse_page(jsondata)
time.sleep(1)
m_id = results['max_id']
id_type = results['max_id_type']
如图6是用记事本打开的csv格式数据,如图7是excel打开的csv数据格式。

图6

图7
四、 总结
这篇文章主要介绍了,Python爬取手机端微博。是对前面文章的一个应用。这样就介绍了两种爬取评论的方式。第三种爬取PC端,还需要经过一段时间的积累和沉淀。一起学习加油。这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
