【Python爬虫实例学习篇】——5、【超详细记录】从爬取微博评论数据(免登陆)到生成词云
近段时间新型冠状病毒的问题引起了全国人民的广泛关注,对于这一高传染性的病毒,人们有着不同的声音,而我想通过大数据看看大多数人是怎么想的。
精彩部分提醒:
(1)微博评论页详情链接为一个js脚本
(2)获取js脚本链接需要该条微博的mid参数
(3)获取mid参数需要访问微博主页
(4)访问微博主页需要先进行访客认证
(5)微博主页几乎是由弹窗构成,所有html代码被隐藏在FM.view()函数的参数中,该参数是json格式
工具:
- Python 3.6
- requests 库
- json 库
- lxml 库
- urllib 库
- jieba 库(进行分词)
- WordCloud 库(产生词云)
目录:
1、爬取微博篇论数据
以央视新闻官方微博置顶的第一条微博为例,爬取其评论数据。

(1) 寻找评论页
第一步:寻找评论页
先用Ctrl+Shift+C 选取评论标签查看其html代码,发现其链接为一个js脚本,那么尝试用fddler看看能不能抓到这个js脚本的包,得到这个js的地址。
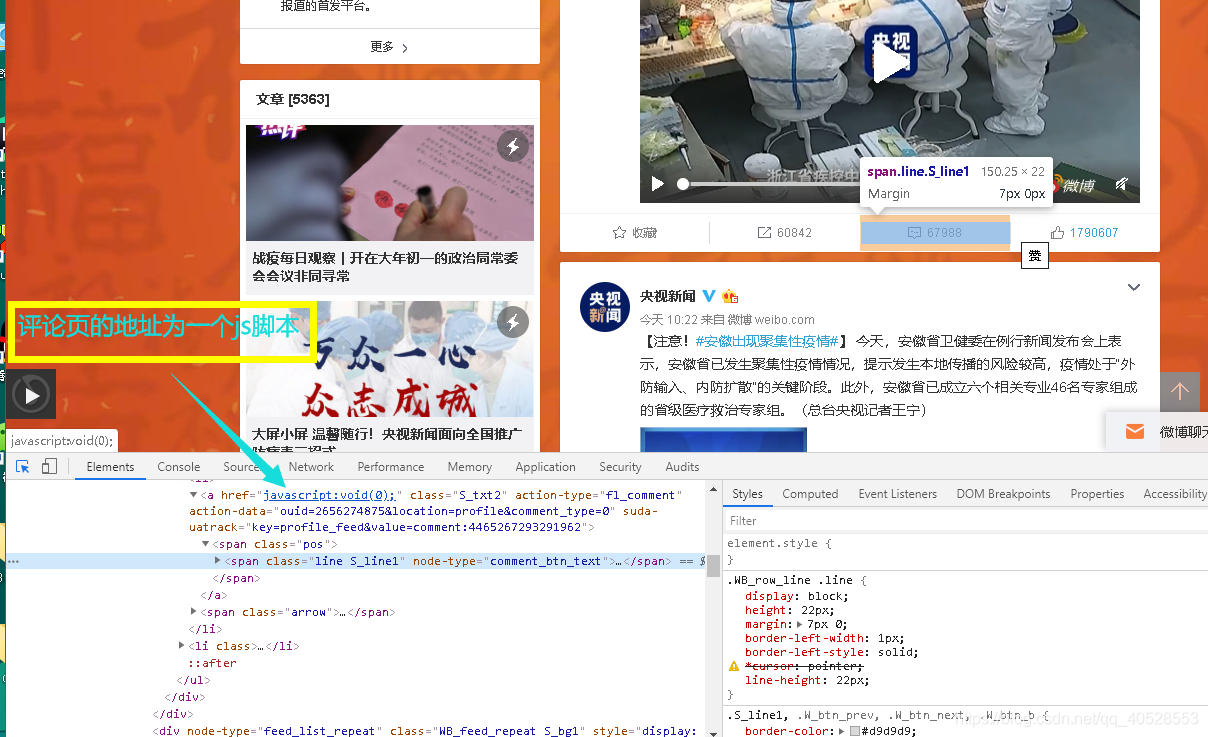
找到疑似js包,将数据解码,确认是我们要找的包。


同时,根据“查看更多”可以确定跳转的链接,将这一结果在json解析结果中搜索,可以进一步确定这个js包就是我们要找的包。接下来需要确定这个js包是来源于哪。
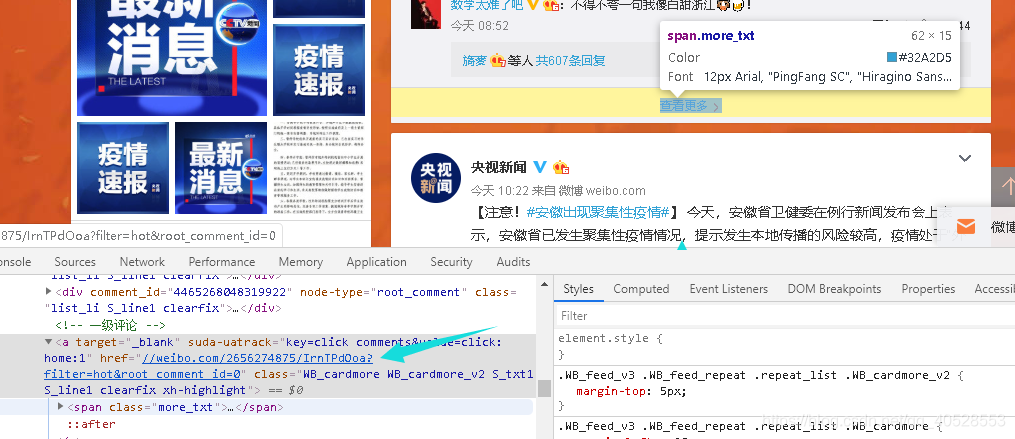
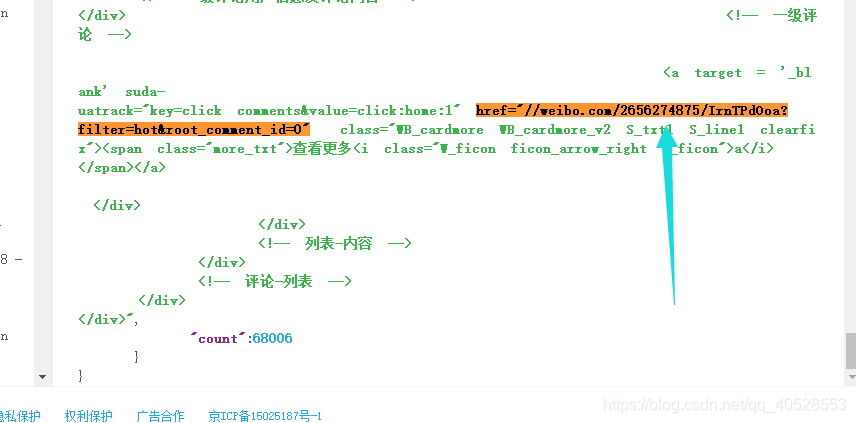
第二步:找到js包地址
js包地址为:“https://weibo.com/aj/v6/comment/small?ajwvr=6&act=list&mid=4465267293291962&uid=3655689037&isMain=true&dissDataFromFeed=%5Bobject%20Object%5D&ouid=2656274875&location=page_100206_home&comment_type=0&_t=0&__rnd=1580130440282”,链接很长,且参数很多,根据以往经验,我们尝试删除一些参数进行访问测试。
经过测试发现只需mid这一个参数即可获取该数据包。
所以有效js包地址为:”https://weibo.com/aj/v6/comment/small?mid=4465267293291962“。
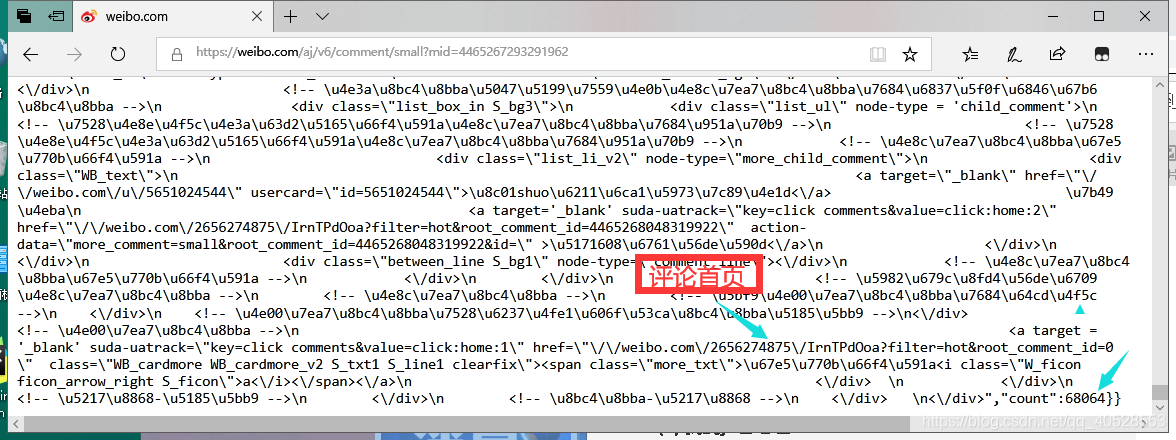
那么,接下来的工作就是去寻找mid这以参数的值(猜测应该是微博的唯一序列号)。在Fiddler中搜索 “mid=4465267293291962”可以发现在央视新闻首页中,每条微博里面都包含了该微博的mid信息。

用Ctrl+Shift+C 任意选取一条微博,可以发现有一个 “mid” 属性,里面包含mid的数据
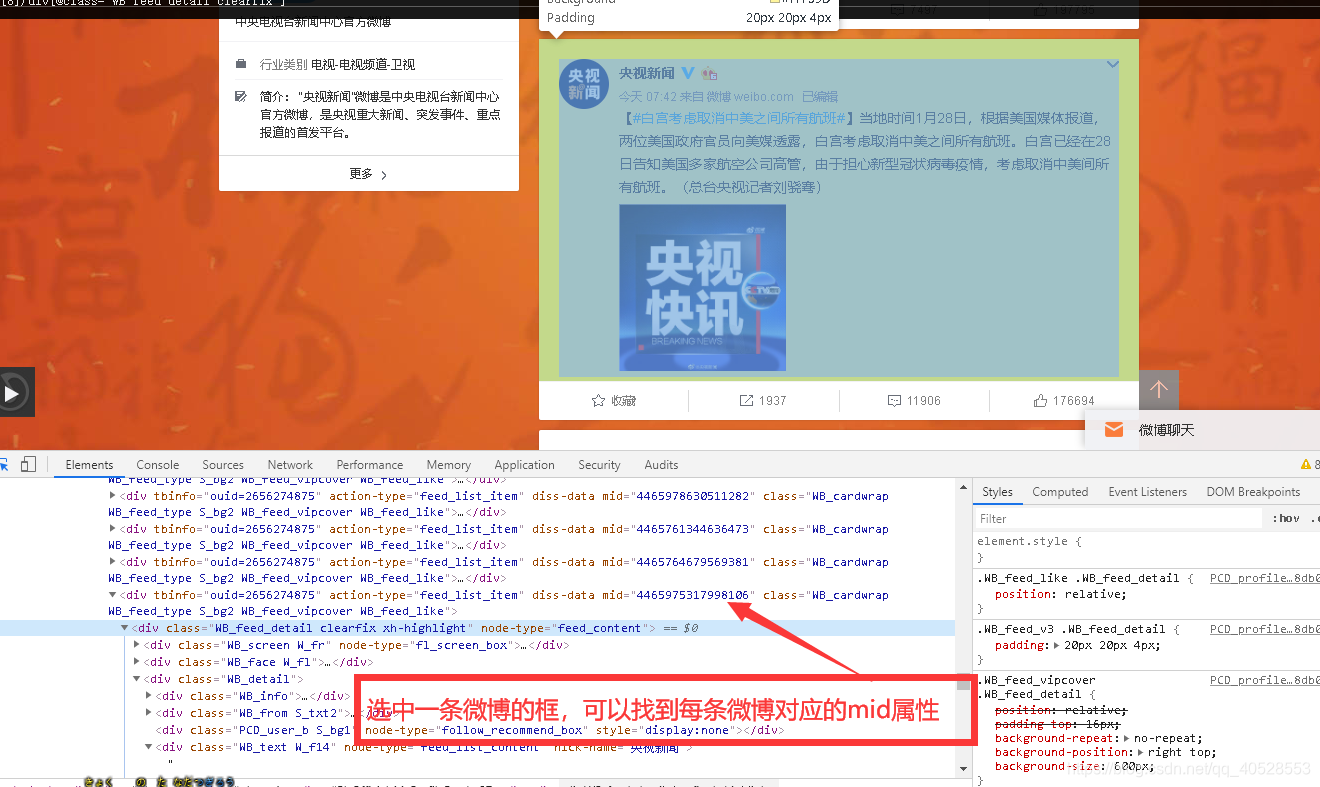
用XPath Helper进行调试,没有问题,接下来在python上实现这部分代码,(经过后面测试发现获取评论数据只需获取微博的mid即可,因此下面这几步可以跳过,但是为例保证探索过程的完整性,我将其留在了这里)

得到评论页的代码:
import requests
from lxml import etree
requests.packages.urllib3.disable_warnings()
name="cctvxinwen"
home_url='https://weibo.com/'+name
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36"
}
session=requests.session()
res=session.get(home_url,headers=headers,timeout=20,verify=False)
html=etree.HTML(res.content.decode('gb2312',"ignore"))
mid_list=html.xpath("//div/@mid")
本以为可以轻松获取新闻主页,结果发现若是没有附带cookie的话,会自动跳转到微博登陆验证页面。

用chrome的无痕访问结合fiddler,重新抓包,可以清晰的发现微博的验证登陆流程。其中最重要的是第11号包,其余6号包用于提供参数解析,9号包提供参数s和参数sp的数据,8号包用于提供9号包访问链接中参数的数据。

对于我们的爬虫来说,只需要从第8号包开始访问即可,8号包需要提交的数据为(常量):
cb=gen_callback&fp={"os":"1","browser":"Chrome80,0,3970,5","fonts":"undefined","screenInfo":"1920*1080*24","plugins":"Portable Document Format::internal-pdf-viewer::Chrome PDF Plugin|::mhjfbmdgcfjbbpaeojofohoefgiehjai::Chrome PDF Viewer|::internal-nacl-plugin::Native Client"}
需要注意的是,在使用requests库时,需要向协议头中添加:
‘Content-Type’: ‘application/x-www-form-urlencoded’,否则返回数据为空。
9号包的链接为:
“https://passport.weibo.com/visitor/visitor?a=incarnate&t=39dNzddUHqqZOWZQbMiDrOvkea/y7s06WFyX%2BzsGk8w%3D&w=2&c=095&gc=&cb=cross_domain&from=weibo&_rand=0.5282100349168277”,其中_rand参数可以忽略。这里需要注意,添加tid参数时,tid参数需要 url编码。
在完成9号包的访问后,就可以获取央视新闻微博的主页了:

第三步:获取评论页链接
在这里有一个很有意思的现象,当我在网页用xpath helper调试的时候,能够非常容易的获取对应的属性值,但是一旦将该xpath语法应用与python中进行解析时,总是得到空的数据。经过一番调试发现,是由于微博这个 ==“欧盟隐私弹窗”==所致。所有我们需要的数据全部被隐藏在这个弹窗之中,微博页面的所有内容通过调用 FM.view() 这个函数显示出来,网页的html代码就隐藏在 FM.view() 函数的json格式的参数中。

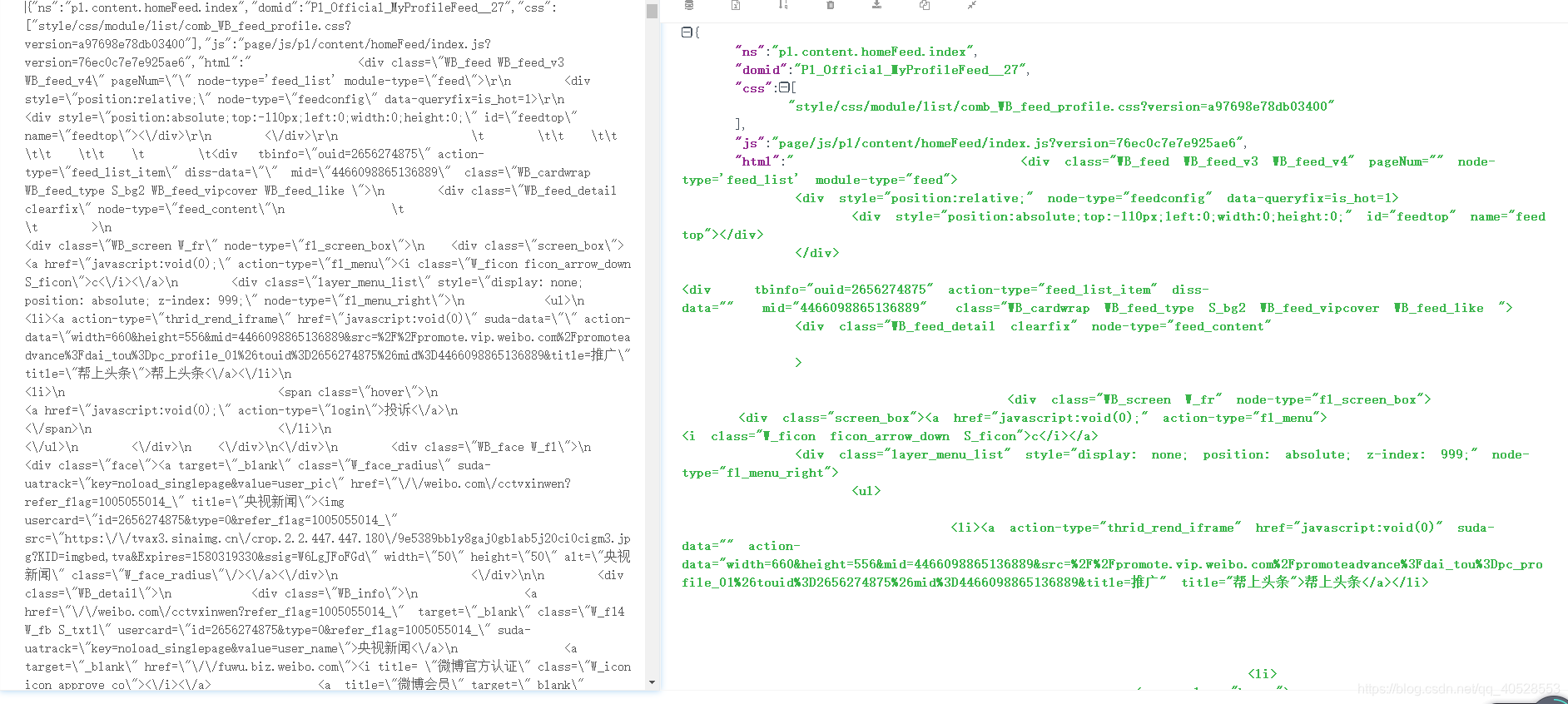
第一部分的代码为:
import requests
import json
from urllib import parse
from lxml import etree
requests.packages.urllib3.disable_warnings()
session = requests.session()
session.verify = False
session.timeout = 20
name = "cctvxinwen"
home_url = 'https://weibo.com/' + name
url1 = "https://passport.weibo.com/visitor/genvisitor"
urljs='https://weibo.com/aj/v6/comment/small?mid='
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36"
}
data = "cb=gen_callback&fp=%7B%22os%22%3A%221%22%2C%22browser%22%3A%22Chrome80%2C0%2C3970%2C5%22%2C%22fonts%22%3A%22undefined%22%2C%22screenInfo%22%3A%221920*1080*24%22%2C%22plugins%22%3A%22Portable%20Document%20Format%3A%3Ainternal-pdf-viewer%3A%3AChrome%20PDF%20Plugin%7C%3A%3Amhjfbmdgcfjbbpaeojofohoefgiehjai%3A%3AChrome%20PDF%20Viewer%7C%3A%3Ainternal-nacl-plugin%3A%3ANative%20Client%22%7D"
# 获取tid
headers.update({'Content-Type': 'application/x-www-form-urlencoded'})
tid = json.loads(session.post(url=url1, headers=headers, data=data).content.decode('utf-8')[36:-2])['data']['tid']
del headers['Content-Type']
# 获取访客cookie
url2 = "https://passport.weibo.com/visitor/visitor?a=incarnate&t=" + parse.quote(
tid) + "&w=2&c=095&gc=&cb=cross_domain&from=weibo"
session.get(url=url2.encode('utf-8'), headers=headers)
# 访问微博主页,解析获取评论页面
res = session.get(url=home_url, headers=headers)
html = etree.HTML(res.content.decode('utf-8', "ignore"))
# 含有mid的html代码被隐藏在这一个json中
mid_json = json.loads(html.xpath("//script")[38].text[8:-1])
mid_html=etree.HTML(mid_json['html'])
mids=mid_html.xpath("//div/@mid")
# 获取第一条微博的js包地址
urljs=urljs+str(mids[0])
res=session.get(url=urljs, headers=headers)
js_json_html=json.loads(res.content)['data']['html']
print(js_json_html)
print("该微博当前评论数为:"+str(json.loads(res.content)['data']['count']))
# 解析获取评论页地址
js_html=etree.HTML(js_json_html)
url_remark=js_html.xpath("//a[@target='_blank']/@href")[-1]
url_remark="https:"+url_remark
(2) 获取并评论
获取评论页后,我们非常容易的就能找到评论数据的json包,如图所示:
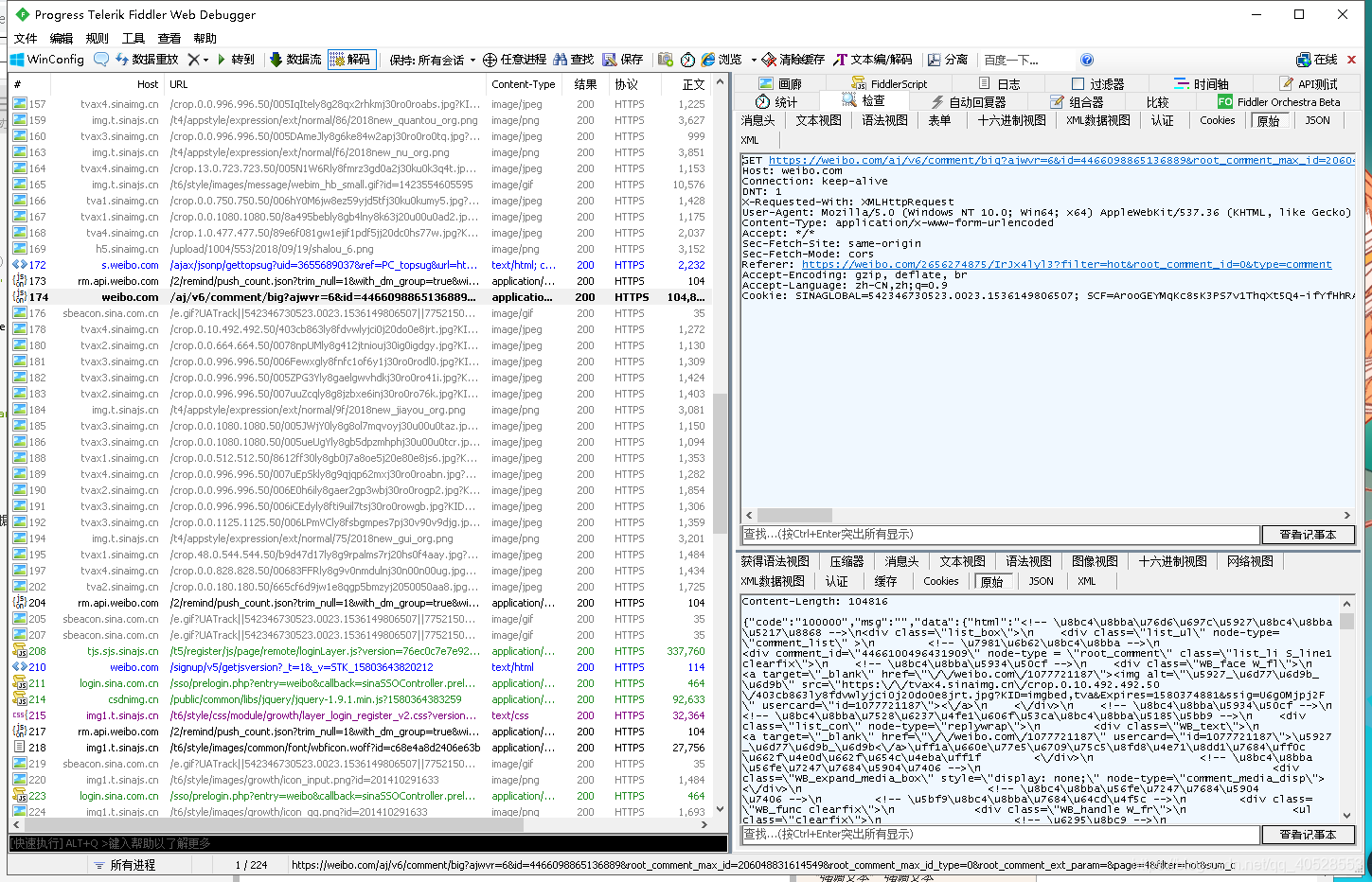
该json包的链接为:“https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4466098865136889&root_comment_max_id=206048831614549&root_comment_max_id_type=0&root_comment_ext_param=&page=4&filter=hot&sum_comment_number=13481&filter_tips_before=1&from=singleWeiBo&__rnd=1580364082863”
其中,有效json包链接为:“https://weibo.com/aj/v6/comment/big?ajwvr=6&id=4466098865136889&page=1&from=singleWeiBo”。获取json包之后,既可以提取出评论数据,其代码如下 (由于该json包不需要其他参数,需要额外提供mid和sum_comment_number参数即可,因此我们在获取mid后可以直接跳到这一步) :,经过测试,若不提供sum_comment_number参数只能提取前几页的微博评论。
爬取评论如下:
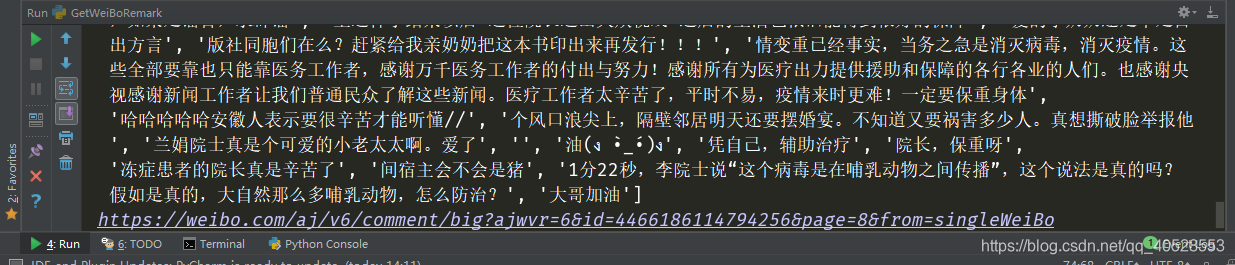
2、 GetWeiBoRemark.py
import requests
import json
from urllib import parse
from lxml import etree
# 预设
requests.packages.urllib3.disable_warnings()
session = requests.session()
session.verify = False
session.timeout = 20
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3970.5 Safari/537.36"
}
def getweiboremark(name, index=1, num=-1):
# name参数代表微博主页的名称
# index参数代表目标微博的序号
# num代表要爬的评论数,-1代表所有评论
# 返回结果为评论列表
home_url = 'https://weibo.com/' + name
tid = get_tid()
get_cookie(tid=tid)
mids = get_mids(home_url=home_url)
remark_data = get_remarkdata(num=num, mids=mids, index=index)
return remark_data
def get_tid():
# 获取tid
url1 = "https://passport.weibo.com/visitor/genvisitor"
data = "cb=gen_callback&fp=%7B%22os%22%3A%221%22%2C%22browser%22%3A%22Chrome80%2C0%2C3970%2C5%22%2C%22fonts%22%3A%22undefined%22%2C%22screenInfo%22%3A%221920*1080*24%22%2C%22plugins%22%3A%22Portable%20Document%20Format%3A%3Ainternal-pdf-viewer%3A%3AChrome%20PDF%20Plugin%7C%3A%3Amhjfbmdgcfjbbpaeojofohoefgiehjai%3A%3AChrome%20PDF%20Viewer%7C%3A%3Ainternal-nacl-plugin%3A%3ANative%20Client%22%7D"
headers.update({'Content-Type': 'application/x-www-form-urlencoded'})
res=session.post(url=url1, headers=headers, data=data).content.decode('utf-8')[36:-2]
tid = json.loads(res)['data']['tid']
del headers['Content-Type']
return tid
def get_cookie(tid, session=session):
# 获取访客cookie
url2 = "https://passport.weibo.com/visitor/visitor?a=incarnate&t=" + parse.quote(
tid) + "&w=2&c=095&gc=&cb=cross_domain&from=weibo"
session.get(url=url2.encode('utf-8'), headers=headers)
def get_mids(home_url, session=session,try_num=0):
# 访问微博主页,解析获取评论页面
# 要想获取mids,必须先获取cookie
res = session.get(url=home_url, headers=headers).content.decode('utf-8', "ignore")
html = etree.HTML(res)
try:
# 含有mid的html代码被隐藏在这一个json中
# 38是企业微博
mid_json = json.loads(html.xpath("//script")[38].text[8:-1])
mid_html = etree.HTML(mid_json['html'])
mids = mid_html.xpath("//@mid")
mids[0]
except Exception as e:
print(e)
try:
# 32是个人微博
mid_json = json.loads(html.xpath("//script")[32].text[8:-1])
mid_html = etree.HTML(mid_json['html'])
mids = mid_html.xpath("//@mid")
mids[0]
except Exception as e:
print(e)
if try_num<2:
mids=get_mids(home_url, session=session, try_num=try_num+1)
if len(mids)==0:
print("多次获取mid失败!程序暂停运行!")
quit()
return mids
def get_remarkdata(num, mids, index=1):
# 获取评论数据
url_remarkdata = 'https://weibo.com/aj/v6/comment/big?ajwvr=6&id={mid}&page={page}&sum_comment_number={comment_number}&from=singleWeiBo'
page = 1
remark_data_new = []
current_num = 0
while True:
print("-" * 50)
url_remarkdata_new = url_remarkdata.format(mid=str(mids[index]),comment_number=str(current_num),page=str(page))
page = page + 1
print("正在采集第 " + str(page - 1) + " 页评论!")
res = session.get(url=url_remarkdata_new, headers=headers)
remark_html = etree.HTML(json.loads(res.content.decode(encoding='utf-8'))['data']['html'])
remark_data = remark_html.xpath("//div[@class='list_con']/div[1]/text()")
remark_num = json.loads(res.content.decode(encoding='utf-8'))['data']['count']
if page == 2:
print("本条微博共有 "+str(remark_num)+' 个评论!')
if num == -1:
num = remark_num
elif num > remark_num:
num = remark_num
for i in remark_data:
if i[0:1] == ':':
i = i[1:]
remark_data_new.append(i.strip())
current_num = len(remark_data_new)
print("当前已采集:" + str(current_num) + " 个评论,剩余:" + str(num - current_num) + "个待采集!")
if (num <= current_num):
break
return remark_data_new
def save_remarkdata(name,data):
with open(name,'w',encoding='utf-8') as fp:
fp.write(data)
fp.flush()
fp.close()
结果展示:
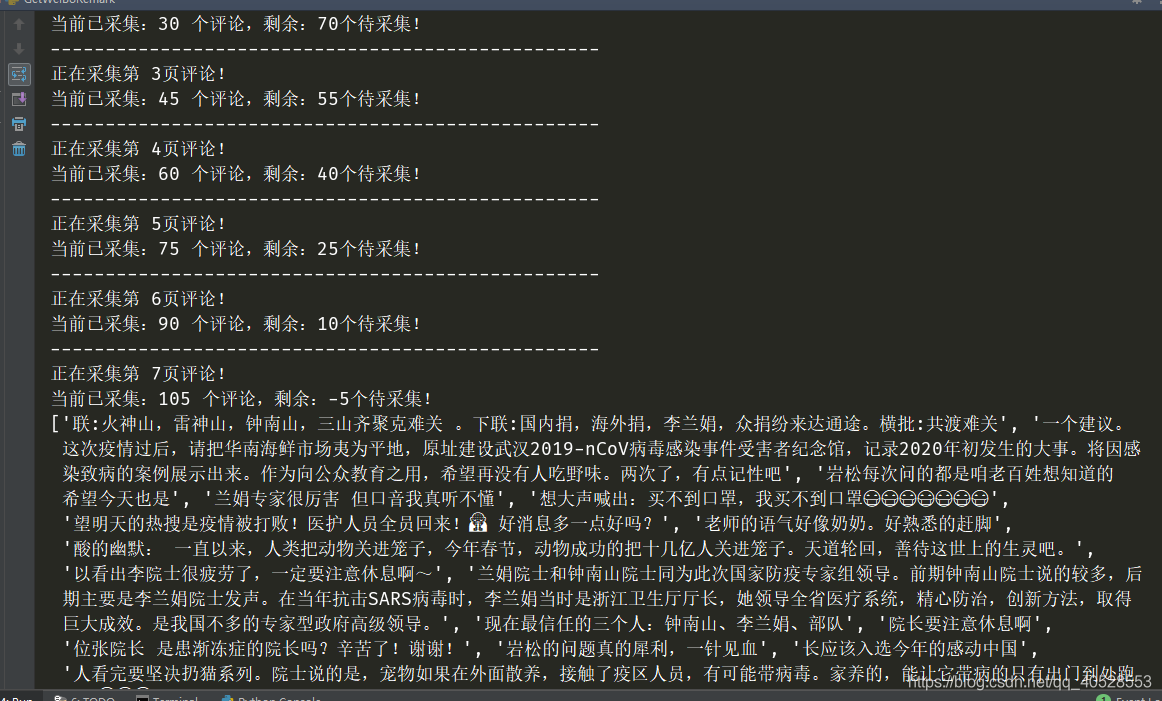
3、生成词云
代码如下:
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import jieba
import GetWeiBoRemark
def producewordcloud(data,mask=None):
word_cloud=WordCloud(background_color="white",font_path='msyh.ttc',mask=mask,max_words=200,max_font_size=100,width=1000,height=860).generate(' '.join(jieba.cut(data,cut_all=False)))
plt.figure()
plt.imshow(word_cloud, interpolation='bilinear')
plt.axis("off") # 不显示坐标轴
plt.show()
if __name__ == '__main__':
# cctvxinwen
remark_data=GetWeiBoRemark.getweiboremark(name="cctvxinwen",index=2,num=100)
str_remark_data=''
for i in remark_data:
str_remark_data=str_remark_data+str(i)
GetWeiBoRemark.save_remarkdata(name='cctvxinwen.txt',data=str_remark_data)
producewordcloud(str_remark_data)
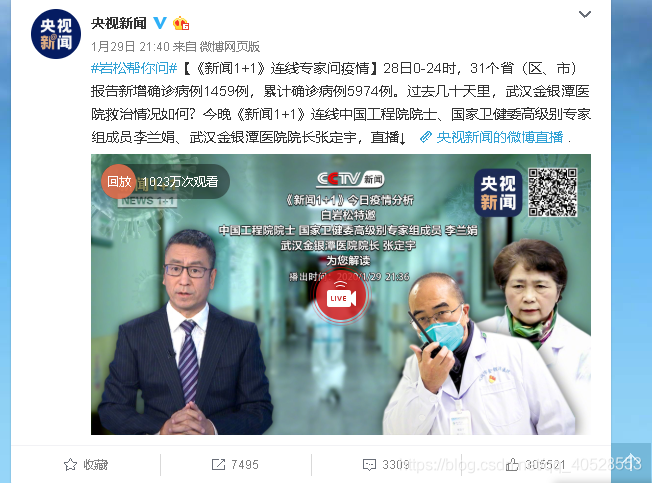
目标微博
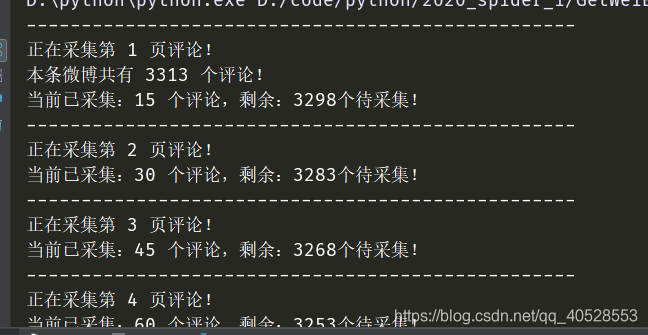
下面是爬3000条数据做出的词云:

微信公众号:

