首先,奉上女神微博词云一张:


在此之前,我一直以为新浪微博的爬取,需要模拟登录等等
偶然之间,在小歪哥那里得知,有一个网站可以免登录爬取:https://m.weibo.cn/u/+oid,这个oid可以从普通新浪微博那里得到。
点击一个关注用户首页,查看其网页源码,源码页搜索用户名,就会看到如下的内容:
<script type="text/javascript">
var $CONFIG = {};
$CONFIG['islogin']='1';
$CONFIG['oid']='1280761142';
$CONFIG['page_id']='1003061280761142';
$CONFIG['onick']='刘雯';
这个oid就是url里面需要的那个,根据url打开微博链接:
打开开发者工具,这个类似于今日头条的页面,具体可参见今日头条的写作过程。
发现请求网页实际是:

打开上述链接,会发现网页内容并非常见的格式,需要来解析一下,推荐一个json格式在线解析网站:http://www.json.cn/,利用这个就可以看到json格式的网页内容:
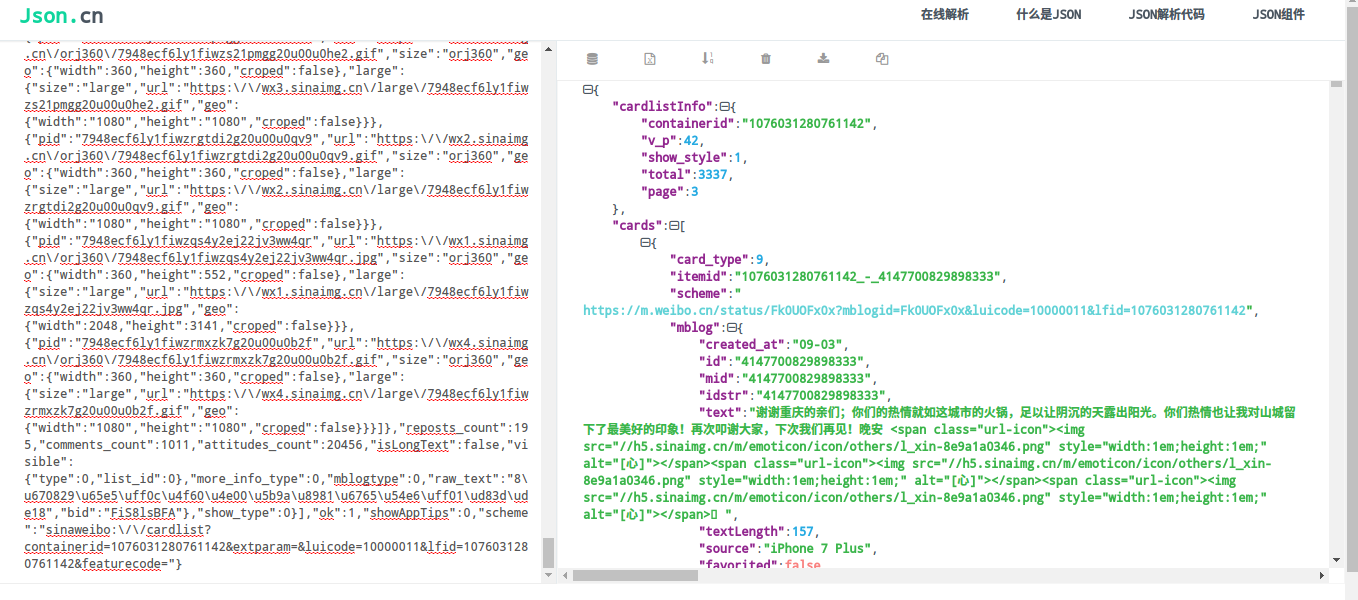
import json,用来解析网页内容。接下来可以访问一个页面,看看我们的思路是否正确。
打开URl
https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1005051280761142
在XHR里面发现:
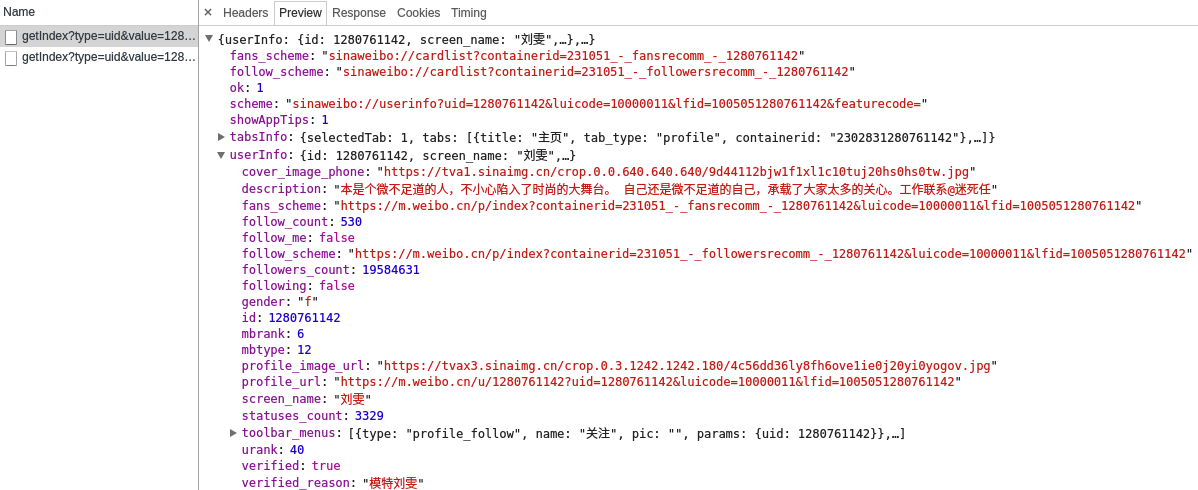
通过对该网页的json格式转换找到微博总数量和微博名称:
#!/usr/bin/env python
# coding=utf-8
import requests
import bs4
import json
import re
import random
import csv
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'}
total_number = 0
#https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1076031280761142
#url = 'http://m.weibo.cn/u/1280761142'
num = 0
ip_list = []
save_list =[]
url_list = []
oid = '1280761142'
weibo_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+oid
weibo_list = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+oid+'&containerid=1076031280761142'
def get_html(url):
try:
r= requests.get(url,timeout=30,headers=headers)
#如果状态码不是200,发出HTTOERROR
r.raise_for_status()
#设置正确的编码方式
r.encoding = r.apparent_encoding#r.encoding = 'utf-8'
return r.json()
except:
return "Something Wrong!"
def get_content(url):
resp_data = get_html(url)
userInfo = resp_data['userInfo']
total_number=userInfo['statuses_count']
name = userInfo['screen_name']
print(total_number)
print(name)
def main():
get_content(weibo_url)
if __name__ == '__main__':
main()
$ python 123sina\(副本\).py
3329
刘雯
然后,对于微博博文页进行访问,
https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1076031280761142&page=3
观察发现,其中多了一串数字containerid,然后我们改变page数字,查看是否能够获得微博列表。
答案是可以的,
然后改变页码,遍历微博博文:
texts_url = []
max_num = (int)(total_number/10)
for i in range(1,max_num+1):
temp = weibo_list+'&page=' + str(i)
texts_url.append(temp) 进行获取,由于存在有的链接并非博文,非博文的text_type不是9,进行判断后再进行获取;存在博文中@对象以及相关网页链接的存在,进行正则匹配后剔除:
text_cards = text_data['cards']
for text_info in text_cards:
text={}
#print(text_info)
text_type = text_info["card_type"]
if text_type != 9:
continue
text['博文链接'] = text_info['scheme']
text_mblog = text_info['mblog']
#print(text_mblog)
num=num+1
#处理博文
text_dirty = text_mblog['text']
try:
clean1 = re.sub(r"<span.*?</span>",'',text_dirty)
text_dirty = re.sub(r'<a.*?</a>','',clean1)
except:
#print("无span链接")
text_dirty = re.sub(r'<a.?*</a>','',text_dirty)
pat=re.compile(r'[^\u4e00-\u9fa5]')#删除非中文字符 括号之类的
text_dirty = pat.sub('',text_dirty)
text['博文'] = text_dirty.strip()
# 获取时间
text['发表时间'] = text_mblog['created_at']
text['转发'] = text_mblog['reposts_count']
text['评论'] = text_mblog['comments_count']
text['点赞'] = text_mblog['attitudes_count']由于重复频率的获取博文,避免IP被封,通过对西刺代理的获取进行,随机更换IP进行访问:
def get_ip_list(url):
global ip_list
web_data = requests.get(url, headers=headers)
soup = bs4.BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
def get_random_ip():
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies将获取到的信息,进行csv存储:
def save_weibo(text):
title_csv = ['发表时间','博文','点赞数量','评论数量','转发数量','博文链接']
with open("weibo_liuwen.csv","w+") as csvfile:
weibo_csv = csv.writer(csvfile)
weibo_csv.writerow(title_csv)
for weibo in save_list:
text=[]
text.append(weibo['发表时间'])
text.append(weibo['博文'])
text.append(weibo['点赞'])
text.append(weibo['评论'])
text.append(weibo['转发'])
text.append(weibo['博文链接'])
weibo_csv.writerow(text)也可以对微博内容进行词云分析。
完整代码如下:
#!/usr/bin/env python
# coding=utf-8
import requests
import bs4
import json
import re
import random
import csv
# 设置等待时间,避免爬取太快
import time
# 用于在超时的时候抛出异常,便于捕获重连
import socket
headers = {'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'}
total_number = 0
#https://m.weibo.cn/api/container/getIndex?type=uid&value=1280761142&containerid=1076031280761142
#url = 'http://m.weibo.cn/u/1280761142'
num = 0
ip_list = []
save_list =[]
url_list = []
oid = '1280761142'
weibo_url = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+oid
weibo_list = 'https://m.weibo.cn/api/container/getIndex?type=uid&value='+oid+'&containerid=1076031280761142'
def get_ip_list(url):
global ip_list
web_data = requests.get(url, headers=headers)
soup = bs4.BeautifulSoup(web_data.text, 'lxml')
ips = soup.find_all('tr')
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
def get_random_ip():
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
# selenium
def get_html(url):
try:
r= requests.get(url,headers=headers)
#如果状态码不是200,发出HTTOERROR
r.raise_for_status()
#设置正确的编码方式
r.encoding = r.apparent_encoding#r.encoding = 'utf-8'
return r.json()
except:
return "Something Wrong!"
def save_weibo(text):
title_csv = ['发表时间','博文','点赞数量','评论数量','转发数量','博文链接']
with open("weibo_liuwen.csv","w+") as csvfile:
weibo_csv = csv.writer(csvfile)
weibo_csv.writerow(title_csv)
for weibo in save_list:
text=[]
text.append(weibo['发表时间'])
text.append(weibo['博文'])
text.append(weibo['点赞'])
text.append(weibo['评论'])
text.append(weibo['转发'])
text.append(weibo['博文链接'])
weibo_csv.writerow(text)
'''
with open('刘雯weibo.txt','a') as f:
for txt in text:
f.write(txt)
f.close()
'''
def get_content(url):
global total_number,num,save_list
resp_data = get_html(url)
userInfo = resp_data['userInfo']
total_number=userInfo['statuses_count']
name = userInfo['screen_name']
print(total_number)
print(name)
texts_url = []
max_num = (int)(total_number/10)
for i in range(1,max_num+1):
temp = weibo_list+'&page=' + str(i)
texts_url.append(temp)
data = {
'Referer':'https://m.weibo.cn/u/'+oid,
}
for text_url in texts_url:
print(text_url)
proxies = get_random_ip()
print(proxies)
# 超时重连
state = False
timeout = 3
socket.setdefaulttimeout(timeout)
while not state:
try:
r = requests.get(text_url,headers=headers,data=data,proxies=proxies)
state = True
except socket.timeout:
print("超时重连")
state = False
proxies = get_random_ip()
print(proxies)
text_data = r.json()
text_cards = text_data['cards']
for text_info in text_cards:
text={}
#print(text_info)
text_type = text_info["card_type"]
if text_type != 9:
continue
text['博文链接'] = text_info['scheme']
text_mblog = text_info['mblog']
#print(text_mblog)
num=num+1
#处理博文
text_dirty = text_mblog['text']
try:
clean1 = re.sub(r"<span.*?</span>",'',text_dirty)
text_dirty = re.sub(r'<a.*?</a>','',clean1)
except:
#print("无span链接")
text_dirty = re.sub(r'<a.?*</a>','',text_dirty)
pat=re.compile(r'[^\u4e00-\u9fa5]')#删除非中文字符 括号之类的
text_dirty = pat.sub('',text_dirty)
text['博文'] = text_dirty.strip()
# 获取时间
text['发表时间'] = text_mblog['created_at']
text['转发'] = text_mblog['reposts_count']
text['评论'] = text_mblog['comments_count']
text['点赞'] = text_mblog['attitudes_count']
# 博文是否有图片
print(text['博文'],end='\t')
print(text['发表时间'])
save_list.append(text)
save_weibo(text['博文'])
#save_list.append(text['博文'])
print("获取"+str(num)+"条博文...")
# print(text_data)
def main():
get_ip_list('http://www.xicidaili.com/nn/')
#print(proxies)
get_content(weibo_url)
save_weibo(text)
if __name__ == '__main__':
main()
