原创不易,转载前请注明博主的链接地址:Blessy_Zhu https://blog.csdn.net/weixin_42555080
本次代码的环境:
运行平台: Windows
Python版本: Python3.x
IDE: PyCharm
一、 前言
微博是中国最早兴起的自媒体平台,人人都可以在上面发表自己的观点。到现在微博已经成为了官方,明星等“新闻发布“的第一阵地。更为重要的是:微博不同于QQ空间、微信朋友圈,不需要对方加你,也不需要你关注对方,你就可以看到对方的全部动态,个人信息。所以,微博变成了唯一可以爬的社交媒体平台。
文章AJAX数据爬取基本认识及原理中已经介绍了,Ajax数据的爬取过程。同时作为引论,提出了 爬取微博数据时,滚动滑条就会加载很多内容,而这些内容就是通过Ajax将xhr文件从主服务器异步加载到客户端并进行渲染显示的。但是作为爬虫小白来说,还是比较喜欢爬取常规的一次加载完的页面。这篇文章,来介绍一个简单的爬取微博评论的方法。
二、 准备工作
首先找到一个待爬取的微博,需要注意的是,微博分为:微博网页端(http://weibo.com)如图1,微博手机端(http://m.weibo.cn)如图2以及微博移动端(http://weibo.cn)如图3。
图1
图2
图3
看了上面的内容,需要总结的是:最难看的微博端就是最好爬的微博端!(划重点!!!)
难度程度排序如下:网页端>手机端>移动端,作为入门级玩家,接下,毫不犹豫的选择最难得(对不起我认怂)------移动端来练手。
好了,接下来真是开始爬虫。我们要爬取的是翟天临同学的博客,这篇致歉信内容的博客(个人观点:知错能改,善莫大焉。给他个机会,让他为社会做更多贡献吧,他还年轻)。微博页面是张这样的,如图4:。
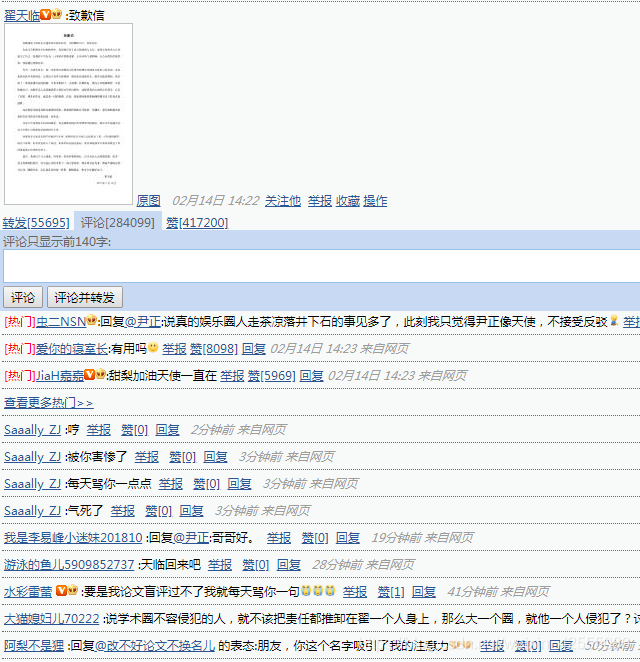
图4
通过点击下一页可以注意到每页评论的url
https://weibo.cn/comment/HgCfidCUs?uid=1343887012&rl=0&page=1
https://weibo.cn/comment/HgCfidCUs?uid=1343887012&rl=0&page=2
https://weibo.cn/comment/HgCfidCUs?uid=1343887012&rl=0&page=3
0.......
最后有page= ,第一页是1,第二页会变为2。
找到了这个突破口后面的就可以真正爬虫了
三 代码实现
import requests
import re
import time
def get_one_page(url):#请求函数:获取某一网页上的所有内容
headers = {
'User-agent' : 'your User-agent',
'Host' : 'weibo.cn',
'Accept' : 'application/json, text/plain, */*',
'Accept-Language' : 'zh-CN,zh;q=0.9',
'Accept-Encoding' : 'gzip, deflate, br',
'Cookie' : 'your Cookie!!!!',
'DNT' : '1',
'Connection' : 'keep-alive'
}#请求头的书写,包括User-agent,Cookie等
response = requests.get(url,headers = headers,verify=False)#利用requests.get命令获取网页html
if response.status_code == 200:#状态为200即为爬取成功
return response.text#返回值为html文档,传入到解析函数当中
return None
def parse_one_page(html):#解析html并存入到文档result.txt中
pattern = re.compile('<span class="ctt">.*?</span>', re.S)
items = re.findall(pattern,html)
result = str(items)
with open('test.txt','a',encoding='utf-8') as fp:
fp.write(result)
for i in range(28412):
url = "https://weibo.cn/comment/HgCfidCUs?uid=1343887012&rl=0&oid=4345701393410667&page="+str(i)
html = get_one_page(url)
print(html)
print('正在爬取第 %d 页评论' % (i+1))
parse_one_page(html)
time.sleep(3)
经过上面的代码后,结果如图5是控制台的内容:

图5
输出到test.txt文件的内容如图6所示。

图6
这样的数据还不能用,接下来要对数据进行处理,代码如下:
# -*- coding: utf-8 -*
import re
content = '''
爬取的test.txt文件
'''
rawResults = re.findall(">.*?<",content,re.S)
firstStepResults = []
for result in rawResults:
#print(result)
if ">\'][\'<" in result:
continue
if ">:<" in result:
continue
if ">回复<" in result:
continue
if "><" in result:
continue
if ">\', \'<" in result:
continue
if "@" in result:
continue
if "> <" in result:
continue
else:
firstStepResults.append(result)
subTextHead = re.compile(">")
subTextFoot = re.compile("<")
i = 6593
for lastResult in firstStepResults:
resultExcel1 = re.sub(subTextHead, '', lastResult)
resultExcel = re.sub(subTextFoot, '', resultExcel1)
print(i,resultExcel)
i+=1
处理完的内容打印到控制台,如图7所示:

图7
四、总结
这样数据就全部获取到了,接下里有了数据可以继续对数据进行情感分析,当然也可以将数据装到MongoDB或者MySQL数据库中,你想怎么处理都是可以的。相应的处理方法在其他博客上都是讲解过的。 这篇博文主要介绍了如何爬取手机端的微博评论数据,有一定基础的和爬虫经验的人来说,相对容易上手。 这篇文章就到这里了,欢迎大佬们多批评指正,也欢迎大家积极评论多多交流。
