参考:http://www.zuidemo.com/filePreview/pdfFilePreview/11202并进行补充
1.新建七个centos7系统的虚拟机,分别命名为cluster1,cluster2等。关闭防火墙。
2.七台主机都修改host文件
vi /etc/hosts
3.集群间做ssh免密设置
vi /etc/ssh/sshd_config添加
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
保存后执行命令
ssh-keygen -t rsa一路回车,然后在~/.ssh/目录下会生成一个保存有公钥的文件:id_rsa.pub
将公钥拷贝到其他机子上
ssh-copy-id [email protected]同理,将cluster1,cluster2公钥分别拷到另外两个主机上。
验证:
ssh cluster2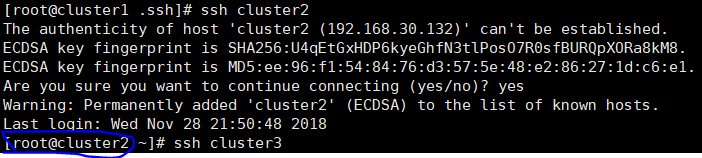
发现cluster1,cluster2可以在三个主机间免密登录,cluster3登录其他主机需要密码 。
4. 配置Hadoop
1.将hadoop压缩包解压
2.修改系统配置文件
vim /etc/profile添加
export HADOOP_HOME=/usr/local/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$PATH
3.修改hadoop配置文件
在/usr/local/hadoop-2.7.3/etc/hadoop目录下修改配置文件
vim hadoop-env.sh添加
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.191.b12-0.el7_5.x86_64/修改hdfs-site.xml
<!-- 指定hdfs的nameservices为mycluster,与core-site.xml保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个namenode,分别为nameNode1,nameNode2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nameNode1,nameNode2</value>
</property>
<!-- nn1 rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nameNode1</name>
<value>cluster1:9000</value>
</property>
<!-- nn1 http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nameNode1</name>
<value>cluster1:50070</value>
</property>
<!-- nn2 rpc通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nameNode2</name>
<value>cluster2:9000</value>
</property>
<!-- nn2 http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nameNode2i</name>
<value>cluster2:50070</value>
</property>
<!-- 指定NameNode元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://cluster4:8485;cluster5:8485;cluster6:8485;cluster7:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/journal</value>
</property>
<!-- 开启nameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservices为mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>cluster1:2181,cluster2:2181,cluster3:2181</value>
</property>
</configuration>
修改mapred-site.xml.template
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 开启RM高可靠 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yarn_cluster</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>cluster2</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>cluster11:2181,cluster12:2181,cluster13:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
将cluster1上的hadoop安装目录复制到其他主机上
scp -r hadoop-2.7.3/ cluster3:/usr/local/5.配置zookeeper
上传zookeeper文件并解压
在conf目录下复制 zoo_sample.cfg
cp zoo_sample.cfg zoo.cfg修改zoo.cfg

在三个主机的/usr/local/data/zookeeper/目录下新建myid文件,并分别填入1,2,3,对应三个server
将zookeeper安装目录复制到其他两个主机上
scp -pr zookeeper-3.4.10 cluster3:/usr/local/在bin目录下启动三个主机的zookeeper服务
./zkServer.sh start查看服务状态
./zkServer.sh status
