Hadoop集群搭建一:Single node cluster
本文主要介绍在单个ubantu机器上搭建hadoop集群。
1.ubuntu虚拟机安装
采用Vmware workstation10工具来安装ubuntu系统,ubuntu使用的是64位的18.04-desktop版本,具体安装过程可自行Google,此处不再详细说明。
给出资源下载链接:
ubuntu-18.04-desktop-amd64.iso(密码:qpkx)
2.使用XShell连接ubuntu虚拟机
(1) 在连接之前需要查看虚拟机的ip地址,使用命令:ifconfig -a,但系统刚安装好会提示系统没有该命令,需要通过sudo apt install net-tools来安装,于是执行命令:sudo apt install net-tools,但之后系统会提示“无法定位到net-tools软件包”,这是因为没有更新软件源,此时更新软件源:sudo apt-get update,更新完成之后,再次执行:sudo apt install net-tools,即可正常执行,此时查看ip:ifconfig -a。(红框所示即为本机ip地址)

(2) 此时我们需要继续设置sshd服务,因为XShell软件是基于这个sshd服务的22端口进行连接的。
首先需要安装该服务:sudo apt-get install openssh-server,安装完成之后,查看该服务是否安装:ps -e|grep ssh,,若显示的信息中有ssh而没有sshd,则需要开启该服务:sudo service ssh start。
设置完之后,既可以通过XShell连接ubuntu虚拟机了,Happy!(以下执行的操作即可在windows环境运行,不用在切换系统)
3.在ubuntu机器中安装Java
因为整个hadoop环境是基于Java开发的,所以必须安装Java基础环境。
执行命令:sudo apt-get install default-jdk,网速给力的话几分钟就可以执行完毕!
安装完查看Java版本:java -version
查看Java存放的文件夹:update-alternatives --display java
4.建立ssh无密码登录本机
使用“stephen”账户登录系统,安装SSH:sudo apt-get install ssh
安装rsync:sudo apt-get install rsync
生成SSH密钥,执行命令:ssh-keygen -t dsa -P ' ' -f ~/.ssh/id_dsa
查看密钥:ll ~/.ssh
将生成的密钥文件追加到验证文件:cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
此时登录本机:ssh localhost
5.hadoop环境文件配置
(1) 下载hadoop-2.6.0包
通过xftp工具将这个hadoop包传送到ubuntu虚拟机中。,使用:sudo tar -zxvf hadoop-2.6.0.tar.gz解压,然后移动:sudo mv hadoop-2.6.0 /usr/local/hadoop
然后进入配置文件的路径:cd /usr/local/hadoop/etc/hadoop(再次强调,使用自己的路径)
(2)配置环境配置文件(红框所示):

各文件配置内容:
1.修改~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
保存,
执行 source ~/.bashrc
2.hadoop-env.sh文件
将JAVA_HOME文件配置为本机JAVA_HOME路径
3.修改core-site.xml:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
4.修改yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5.修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6.修改hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value> file:/usr/local/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value> file:/usr/local/hadoop/hadoop_data/hdfs/datanode</value>
</property>
</configuration>
6.初始化环境
(1) 在配置完文件后,创建namenode和datanode两个文件夹:
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/datanode
sudo mkdir -p /usr/local/hadoop/hadoop_data/hdfs/namenode
修改所有权:sudo chown -R stephen:stephen /usr/local/hadoop
(2) hadoop格式化
hdfs namenode -format
7.启动hdfs
有两种启动方式:
方式1: 执行:start-dfs.sh ; 然后执行:start-yarn.sh
方式2:start-all.sh
中间过程中会要求输入yes/no,以及用户密码
启动成功后,可以通过jps命令各个工作的节点。
8.查看ResourceManager和datanode相关信息
打开ubuntu系统中的火狐浏览器,在地址栏输入:http://localhost:8088,即可进入ResourceManager界面,查看namenode节点信息。

在地址栏输入:http://localhost:50070,即可查看当前HDFS与datanode节点信息。

PS:问题记录
1.Linux文件夹权限
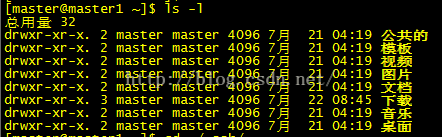
第一列共有十位
第一位,d:表示是一个目录,-:表示一个普通的文件
第2-4位:rwx:分别表示读,写,执行,这里显示为rwx表示文件所有者对该文件拥有读写执行的权利(补充一点,rwx用数字表示为4,2,1)
第5-7位:r-x:表示与该文件所有者的同组用户拥有该文件的读和执行的权限
第8-10位:r-x:表示其他组的用户对该文件拥有读和执行的权利
2:linux基本命令
查看用户所属用户组 id hostname / groups hostname
vim命令: 查找:/xxxx
清空: gg dG