本次hadoop伪分布搭建环境:Windows10_64位+VMware9.0+Centos 6.4(32位)
默认以上环境已经配置好,下面开始进行hadoop伪分布集群安装......
============================================================
内容如下:
一、给主机服务器(Centos 6.4)配置IP地址
二、安装jdk,并配置环境变量
三、安装hadoop
四、ssh免密登录
五、HDFS & MapReduce 运行测试
=======================================================
1、测试HDFS
(1)查看hdfs文件系统
hdfs提供了一个web服务,我们可以通过网页访问hdfs里面的文件
打开浏览器在里面地址栏输入:http://work01:50070即可
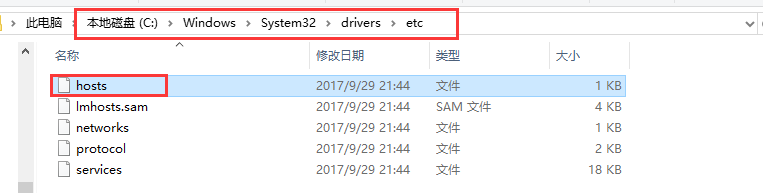
其实这个时候我们的浏览器是不认识work01是什么的,要想让浏览器认识,同样需要我们修改windows里面的hosts文件,位置在C:\Windows\System32\drivers\etc\hosts
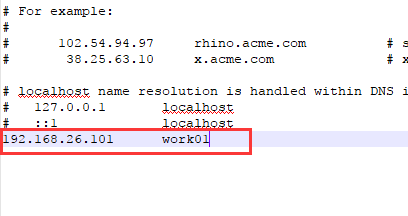
打开在最后一行添加work01及对应的IP地址即可
然后再次刷新浏览器就可以看到如下界面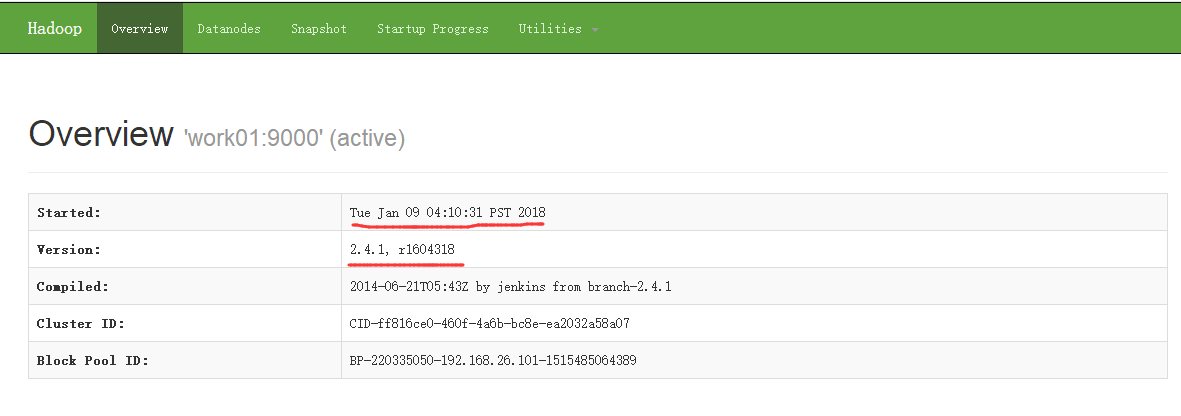
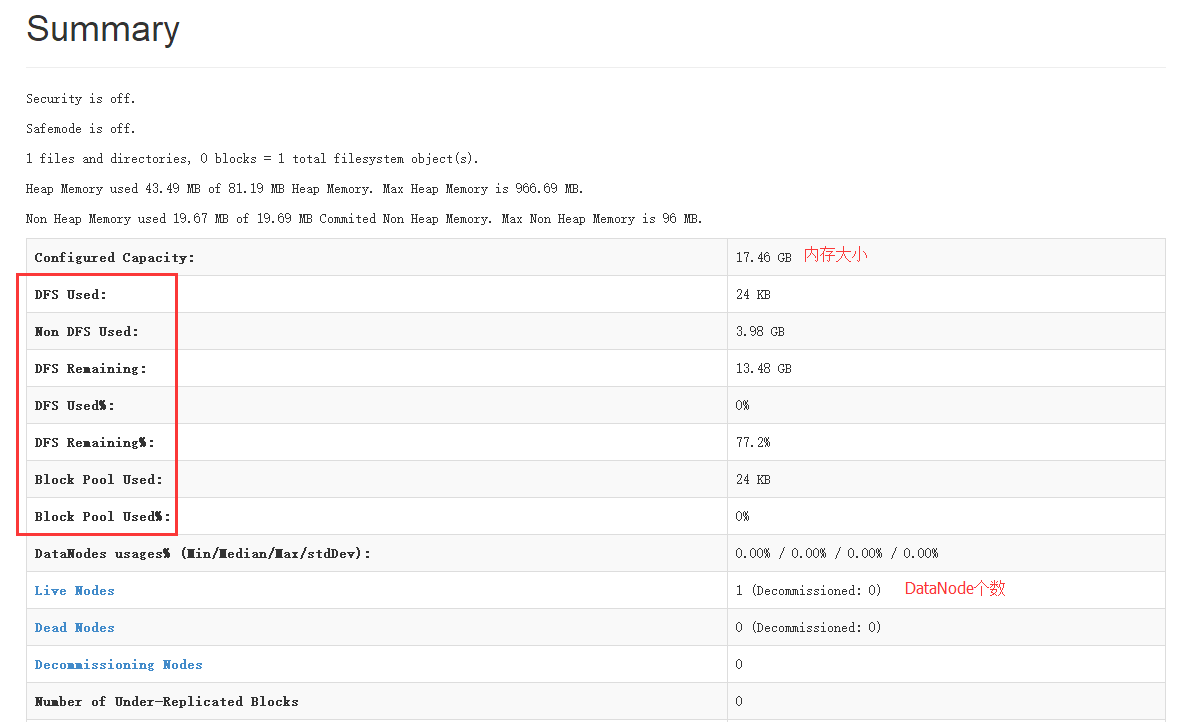
同样hdfs的文件系统也可以通过浏览器进行浏览
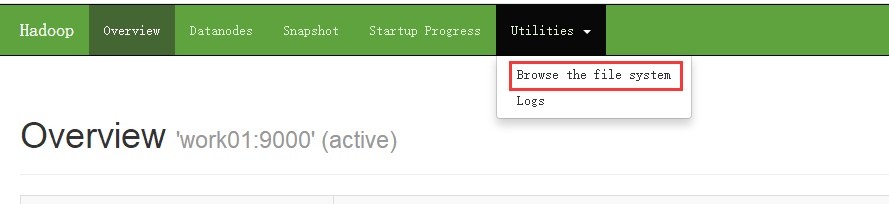
打开之后如下:可以看到此时的根目录下没有任何文件
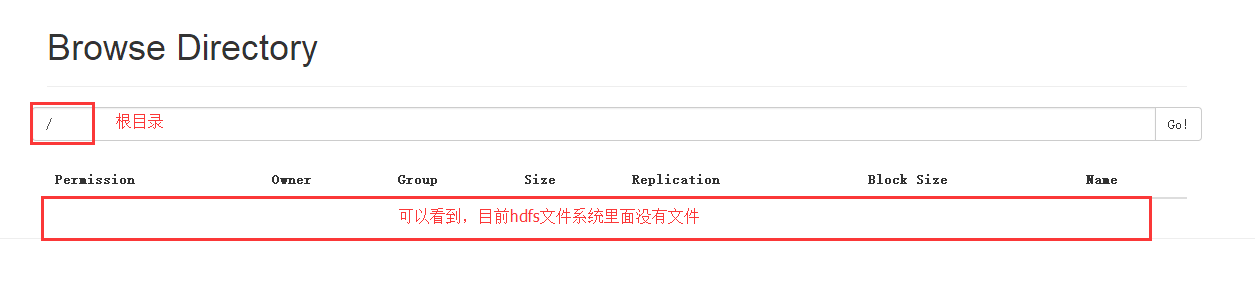
(2)上传文件到hdfs文件系统
接下来我们就上传一个文件到hdfs文件系统里,我们将jdk的安装包上传到hdfs文件系统的根目录下
上传文件的命令为:hadoop fs -put filename hdfspath

再次打开浏览器,刷新可以看到已经上传成功
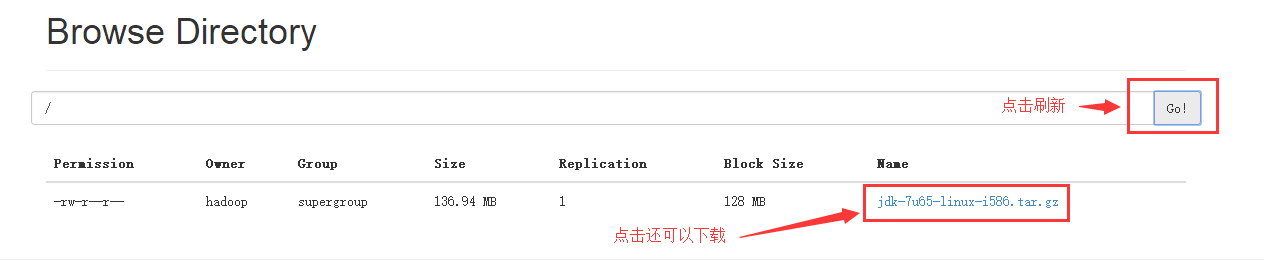
(3)从hdfs文件系统中下载文件到本地
我们首先删除本地的jdk安装包,然后从hdfs文件系统中下载刚才上传上去的jdk安装包
删除文件命令: rm -rf filename
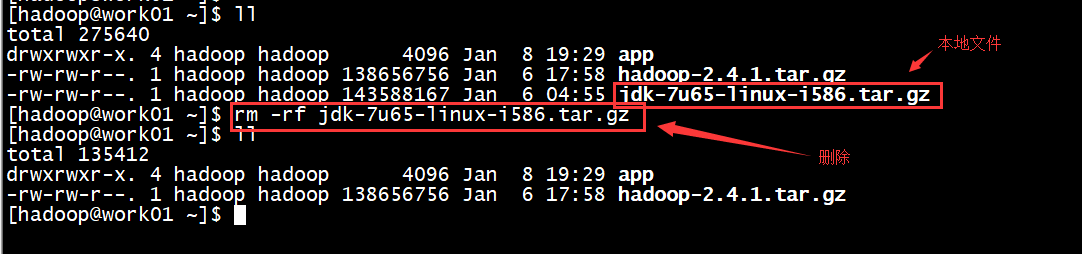
下载hdfs文件系统中的文件命令: hadoop fs -get filepath(此路径是hdfs上的绝对路径)

说明:
其实hdfs文件系统是一个抽象的文件系统,这个系统和我们本地的文件系统不冲突,即使删除了本地的文件,已经上传到hdfs的文件依然存在。上传的文件其实已经不是一个完整的文件了,而是被切分后存储在DataNode所在的机器中,即之前设置的hadoop.tmp.dir对应的路径里面。
至此,hdfs文件系统可以正常运行。
2、测试MapReduce
我们可以利用hadoop安装包里的例子程序来测试MapReduce
首先找到例子程序所在的位置 /app/hadoop-2.4.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar
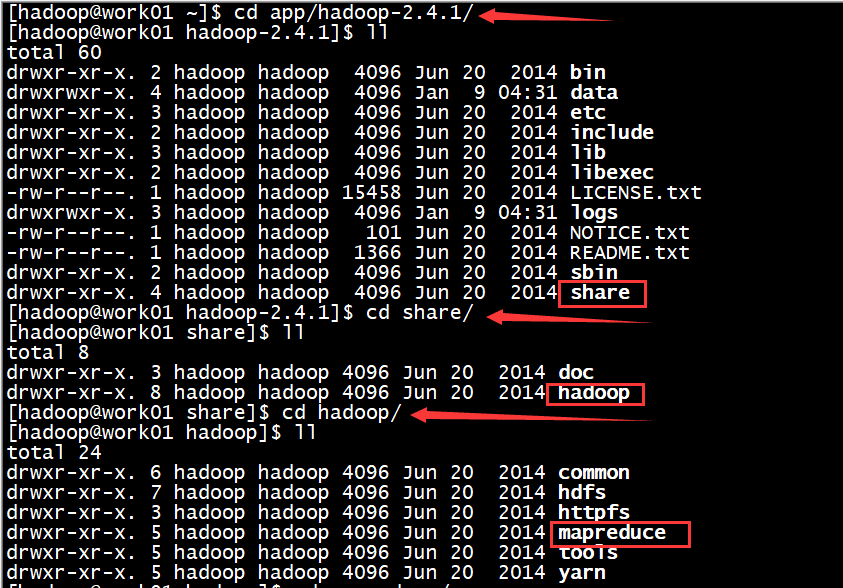
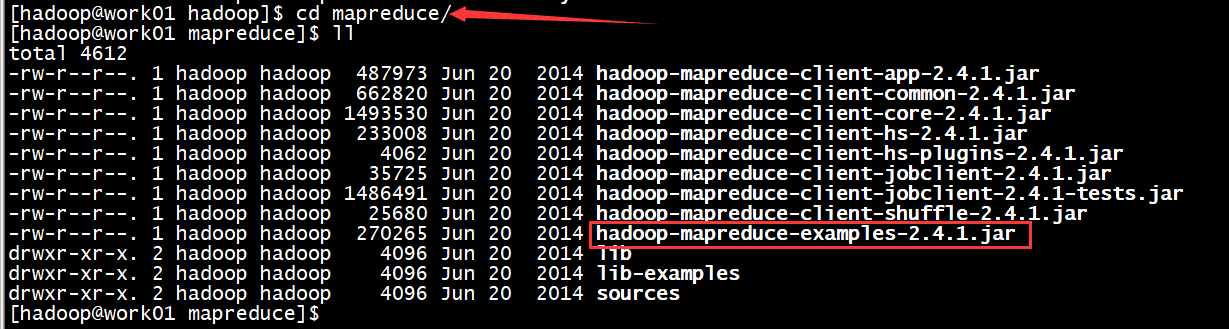
hadoop-mapreduce-examples-2.4.1.jar 这个里面包含了好多MapReduce测试程序,我们只需要给定一些参数,就可以运行指定的MapReduce程序
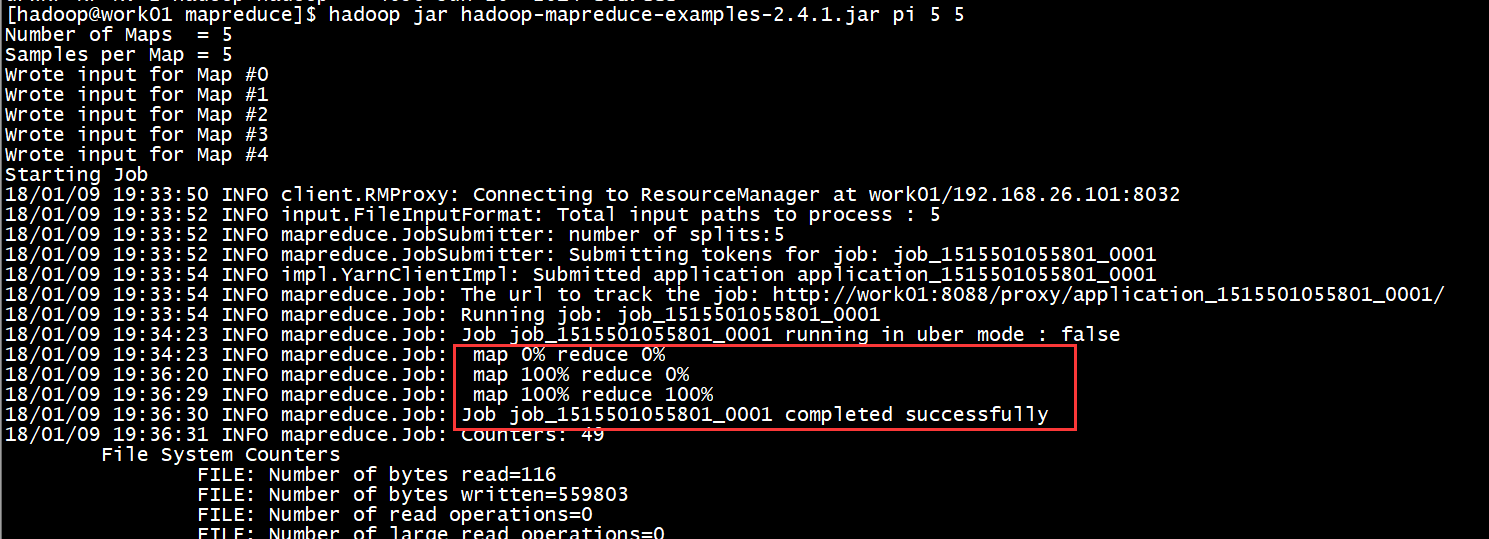
- 我们运行一下一个计算圆周率PI的MapReduce程序
命令是: hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5

其中 pi 指定运行哪个程序,第一个5指定map的个数,第二个5指定map的采样数,这个数越大,pi越接近真实的。
运行结束结果如下:
....
最后的结果直接打印出来了,3.68,与真实值差的有点远(本次只是为了测试),其实给定的参数越大最后的结果越接近真实值。
- 我们再运行一下另一个测试,WordCount程序,该程序是统计文件中单词的个数
首先我们建一个文本文件命令:vi test.txt
输入内容:
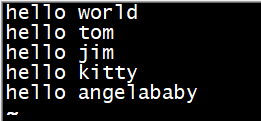
既然MapReduce是在集群上运行的,那么我们要把文件上传到hdfs集群上去,
首先在根目录下建一个文件夹目录 /wordcount/input(注意,hdfs不支持多级文件夹的建立,如果上级文件夹不存在,则必须先建立上级文件夹才行)
建完之后可以通过浏览器打开查看,文件夹已经存在
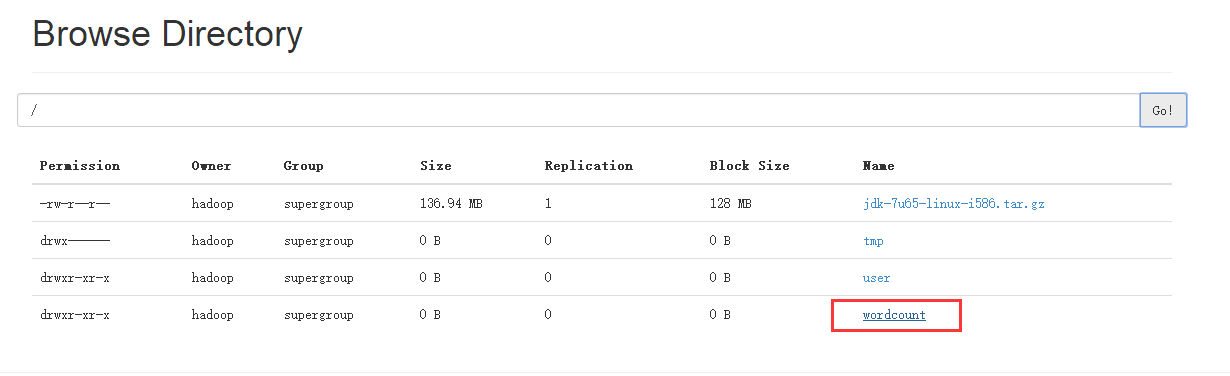
然后将文件上传到input文件夹中,命令:hadoop fs -put test.txt /wordcount/input
可以查看一下已经上传成功
现在我们统计test.txt文件中的单词个数
命令:hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount /wordcount/input /wordcount/output
运行完以后,我们可以查看输出结果
文件part-r-00000里面存放的就是刚才的输出结果,
当然,也可以通过浏览器下载文件查看
-------------------------------------------------------------------------------------------
至此,我们的hadoop伪分布集群就已经搭建完成(虽然只有一个节点),其实真实的集群和伪分布集群的搭建方式是一样的,只不过是多了很多DataNode节点,只需要在Slaves文件中添加相应的机器名,修改相应的配置文件即可。