文章目录
1.Hadoop-HDFS
存储模型:字节
- 文件线性切割成块(Block):偏移量 offset(byte)
- Block分散存储在集群节点中
- 单一文件Block大小一致,文件与文件可以不一致
- Block可以设置副本数,副本无序的分散在不同节点(注意,副本数不要超过节点个数,否则会出现数据重叠在一个节点上的情况,造成资源浪费)
- 文件上传可以设置Block大小和副本数(资源不够开辟的进程)
- 已上传的文件Block副本数可以调整,大小改变
- 只支持一次写入多次对去,同一时刻只有一个写入者
- 可以通过append追加数据
最重要的是hadoop的文件存储是通过分块来存储的
1.1 Hadoop文件块放置的策略
Hadoop文件块放置的策略:
第一个副本:放置在上传文件的DN(Data Node);如果是集群外提交,则随机挑选一台磁盘不太满,CPU不太忙的节点放置。
第二个副本:放置在与第一个副本不同的机架的节点上。
第三个副本:与第二个副本相同机架的节点。
更多副本:选择随机节点。
1.2 Hadoop的架构模型
文件元数据:metadata,文件数据
- 元数据
- 数据本身
Hadoop中的数据存储依靠主从节点来存储,主节点表示存储元数据的节点,从节点表示存储数据本身的节点。
主:NameNode节点保存元数据:单节点,posix(Portable Operating System Interface of UNIX)可移植操作系统接口。
从:DataNode节点保存文件Block数据:多节点。
NameNode与DataNode之间保持心跳机制,以此来判断节点的健康状态,DataNode向NameNode提交Block列表。
HdfsClient与NameNode交互元数据信息
HsfsClient与DataNode交互文件Block信息
DataNode的存储是利用服务器本地的文件系统存储数据。
1.3 Hadoop3新特征
- Classpath isolation(路径隔离)防止不同版本的jar包冲突
- Shell重写
- 支持HDFS中的擦除编码Erasure Encoding
- 默认的EC策略可以节省50%的存储空间,同时还可以承受更多的存储故障
- DataNode内部添加了负载均衡Disk Balancer,有效的防止数据倾斜现象的发生,指代磁盘之间的负载均衡
- MapReduce任务级本地优化
- MapReduce内存参数自动推断(相比之前的默认配置要好很多)
- 基于cgroup的内存隔离和IO Disk隔离
- 支持更改分配容器的资源Container Resizing
- 官方文档说了,需要使用jdk1.8以上版本
- 与2.X版本相比,端口号变化差异比较大

2. 配置hadoop

官方原话:All Hadoop JARs are now compiled targeting a runtime version of Java 8. Users still using Java 7 or below must upgrade to Java 8.
首先需要将我们本地安装好的jdk替换为1.8版本。然后从hadoop官网下载hadoop的压缩包。通过filezilla传到linux上去,执行解压即可。

需要配置的为下图所示:

hadoop-env.sh:在文件末尾加上java的路径以及NameNode+DataNode+SecondaryNameNode的用户即可。

export JAVA_HOME=/usr/local/tmp/jdk1.8.0_201
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name> // 文件系统,默认的文件系统
<value>hdfs://node01:9820</value> // 配置node01,端口号9820
</property>
<property>
<name>hadoop.tmp.dir</name> // hadoop的临时目录地址
// 自己随意配置,不需要存在,执行的时候hadoop会自动创建
<value>/var/sxt/hadoop/peseudo</value>
</property>
</configuration>
hdfs-site.xml:
<configuration>
<property>
// 表示DataNode的副本数,最好不要大于1
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
// secondaryNameNode的配置,起到文件合并的作用
<name>dfs.namenode.secondary.http-address</name>
<value>node01:9868</value>
</property>
</configuration>
workers:workers表示工作者,之前使用的是slave,注意此node01需要在/etc/hosts中配置192.168.87.101 node01,否则无法识别
node01
配置好之后,可以开始执行hadoop的启动步骤了
// 进入hadoop-3.1.2的目录下
./bin/hdfs namenode -format // 对文件系统的格式化
./sbin/start-dfs.sh // 启动文件系统
启动完毕输入jps

表名启动成功,此时浏览器访问node01:9870,可以看到如下界面:

此时可以看到配置的hadoop文件系统的详细信息,具体操作文件系统,需要使用的命令是./bin/hdfs dfs,输入这句命令,系统会给句具体操作的命令提示符。跟linux基本操作符很类似。

在我们浏览器页面中

可以看到对我们的文件系统有一个可视化的操作。

通过这句命令,我们可以完成文件的上传,此时可视化页面可以看见我们上传的文件具体信息。

在我们的linux下也可以找到具体3块文件所在的信息,目录比较深,文件存储在我们之前设置的/var/sxt/hadoop/peseudo下面

上述的都是建立一台虚拟机上的,真实的生产环境都是建立在多个服务器上,文件的存储可以依据上面介绍的文件副本的放置来。
3. Hadoop集群的搭建
首先来说说对于集群的理解,在hadoop集群搭建成功之前,我一直以为的集群就是我是老大,几个小弟,跟着我混日子,但是经历了几个小时的搭建,我深深地意识到,自己实在是太蠢了,怎么能使这样,动用了百度的资源,却忘记去看下集群的概念,最后还是明白了,也就成功了。
集群技术的特点:
- 通过多台计算机完成同一个工作,达到更高的效率。
- 两机或多机内容、工作过程等完全一样。如果一台死机,另一台可以起作用。
看见没,内容完全一样,工作过程等完全一样,这是什么,这是小弟吗,这是跟你一样的复制版本而已。后面解决了,对于集群的理解也就更加的深入,发现集群主要配置一个,其余设置的工作节点也在3.x版本中称为workers,在2.x版本中称为slaves,都是通过主节点分发配置部署内容到从节点中,然后产生的集群效果。
先上完成的效果图:

开始了:
需要四台虚拟机,一台主三台从,配置如下:
node01 192.168.87.101
node02 192.168.87.102
node03 192.168.87.103
node04 192.168.87.104
只需要配置第一台的信息即可。
进入hadoop解压缩包,进入/etc/hadoop中
hadoop-env.sh:配置所需的环境与进程角色
export JAVA_HOME=/usr/local/tmp/jdk1.8.0_201
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
core-site.xml:
<configuration>
<property>
// 默认的文件系统
<name>fs.defaultFS</name>
<value>hdfs://node01:9820</value>
</property>
<property>
// 文件路径
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/peseudo</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
// 副本
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
// 用于合并文件的设置
<name>dfs.namenode.secondary.http-address</name>
<value>node02:9868</value>
</property>
</configuration>
workers:配置的是从节点的别名,注意在hosts文件中需要给出对应的ip地址,否则会识别不了
node02
node03
node04
配置好之后,可以通过分发的方式发给3个从节点。
免秘钥登录操作:
可以使用ssh 192.168.87.101,如果需要登录密码,则可以知道没有配免秘钥。则进行下面的操作:
经过琢磨,秘钥就是你的信息别人有没有,别人如果有你的信息,表明你们是认识的,所以可以直接登录。这里可以参照官方文档来配置秘钥。
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 0600 ~/.ssh/authorized_keys
对于所有的节点都需要这样操作,生成秘钥。
然后只需要将主节点的公钥添加到各个从节点的authorized_keys中即可
操作如下:
// 在node1中
scp ~/.ssh/id_rsa.pub [email protected]:~/ // 传输到node02上
// 在node02上
cat id_rsa.pub >> ~/.ssh/authorized_keys // 这是秘钥追加
所有的从节点如上,此时使用ssh验证都会直接免秘钥。
将配置好的hadoop文件夹分发到几个从节点。
然后使用hdfs namenode -format可以先对文件系统做一个格式化,对于从节点中还没有初始化日志记录的目录会执行一个创建的过程
使用start-dfs.sh可以启动。
启动完毕使用jps可以看到具体的节点运行信息。
node01:9870可以看到可视化页面,如果此时显示的数据都为0,表名操作失败,还需要继续检查,如果验证成功,则大功告成。
注意上述命令可以直接使用hdfs/start-dfs是需要配置的,需要在/etc/profile中配置hadoop路径信息。
配置文件如下:
export HADOOP_HOME=/usr/local/tmp/hadoop-3.1.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

4. Hadoop高可用集群的搭建
Hadoop的高可用是为了避免单个NameNode的宕机造成这个分布式系统无法使用的情况。从Hadoop 3.x开始,加入了高可用。
HDFS 3.0 HA (Hign Availabile)
特点:
- 主备NameNode
- 解决单点故障(属性、位置)
- 主NameNode对外提供服务,备NameNode同步主NameNode元数据,以待切换
- 所有的DataNode同时向连个NameNode会报数据块信息(位置)
- JNN:集群(属性)
- standby:备节点,完成了edits.log文件的合并和产生新的image,推送回ActiveNameNode
- 两种切换选择:
- 手动切换:通过命令实现主备之间的切换,可以用与HDFS升级等场合
- 自动切换,基于zookeeper实现
- 基于Zookeeper自动切换方案:
- Zookeeper Failover Controller:监控NameNode健康状态
- 并向Zookeeper注册NameNode
- NameNode节点挂掉以后,ZKFC成为NameNode竞争锁,获取到ZKFC锁的节点变为Active状态
4.1 高可用的hadoop的配置:
首先看下我们的配置分布图,来决定不同类别的Node以及zookeeper安装的节点。

首选是NameNode的分布,放在node01与node02上面。
DataNode的分布,放在Node02/Node03/Node04上面
Zookeeper安装在Node02/Node03/Node04上面,
ZKFC安装在Node01与Node02上面
JournalNode安装在Node01、Node02、Node03上面
首先配置hdfs-site.xml,配置文件如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node02:9868</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- 配置NameNode的进程 下面两个类似于java中的rmi服务配置 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<!-- 配置失败转移 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置防护隔离 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置一个存储的路径,启动时自动创建 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/sxt/hadoop/ha/journal</value>
</property>
<!-- 配置自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
core-site.xml配置文件:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 配置文件存储的路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/ha</value>
</property>
<!-- 配置zookeeper的端口和地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
</configuration>
配置完之后使用分发的命令,scp分发到几台工作节点上去即可。
4.2 Zookeeper安装及配置
此时需要安装我们的zookeeper软件,可以从apache-zookeeper官网下载,下载路径点击即可下载,注意下载那个大的,小的只是一个骨架,没有lib中的jar包,启动zookeeper的时候会报依赖缺失异常。
解压即可安装完毕,需要启动的话需要修改zookeeper的配置文件。
进入到conf目录下,将zoosample.cfg修改为zoo.cfg文件,否则会发现启动不了。
这个配置文件中主要是添加几个配置项即可:如下
// 数据存储的位置,不修改的话是临时存储位置,文件数据不安全
dataDir=/var/sxt/zk
// 客户端口号,前面在core-site.xml文件中配置了的
clientPort=2181
// 配置的在node02/node03/node04上指定
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
还需要配置的是一个id号,因为涉及到zookeeper的leader选举,所以需要创建一个文件将我们的id放入,一般来说,同时启动,id越大,被选举为leader的可能性也就越大。
只需要在三个点上执行下面的语句即可:
echo 1>> /var/sxt/zk/myid、echo 2>> /var/sxt/zk/myid、echo 3>> /var/sxt/zk/myid
需要在我们的profile中配置一下zookeeper的环境变量。启动zookeeper:zkServer.sh start 如果启动失败,请查看日志,或者百度一下启动日志的启动命令查看错误,如果前面下载zookeeper包没有问题的话,这里一般不会有问题,如果缺少包的话,请下载新的zookeeper,将lib包拷贝到zookeeper的解压缩目录下即可。
出现上图,表明zookeeper安装成功。
此时需要启动我们的journalnode,使用命令hdfs --daemon start journalnode,即可启动,此时使用jps可以看见本地运行的java程序,并显示他们的进程号。
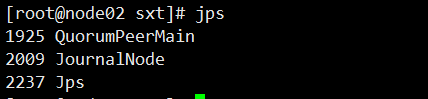
表明启动成功,此时需要进行一个文件的格式化,我们需要在我们设置的namenode中的任意一台上面执行文件的格式化。选在在node01上执行。

注意:此处的异常,一般是报连接异常,需要调整一下启动的顺序,按照先启动zookeeper–>journalnode–>格式化,此时就不会出问题。上面格式化成功以后,我们就可以看到在上面展示的目录下创建了在配置文件中配置的文件夹,启动含有。

此时表名本地的数据格式化成功,此时需要做一个高可用的试验,看看数据能否转移到node02上去。此时的node02相关路径下是没有任何数据的,需要从node01上将此数据转移到node02中去。
步骤:
启动node01上的namenode,hdfs --daemon start namenode,jps显示namenode启动成功以后,在node02上使用hdfs namenode -bootstrapStandby表示将NameNode元数据目录下的内容复制到其他未格式化的NameNode上去。

去到相同目录下可以看到元数据信息的拷贝。表明数据的转移成功。
4.3 试验高可用的可用性(自动故障转移)
测试高可用与失败转移的可用性:
首先需要在Zookeeper中初始化所需要的状态,使用hdfs zkfc -formatZK即可完成初始化,选择的执行节点只需要在NameNode中之一即可。这一步操作的作用:将在zookeeper中创建一个znode,自动故障转移系统将在其中存储其数据。
然后需要启动集群,使用start-dfs.sh可以启动集群,由于已经在配置中启动了自动故障转移,所以start-dfs.sh脚本将在任意运行NameNode计算机上自动启动zkfc守护程序,ZKFC启动时,它将自动给选择一个NameNode并激活。
此时jps,node01上:
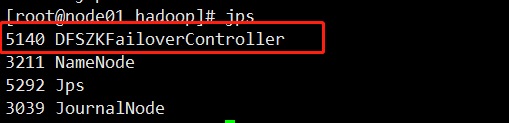
node02上:

此时可以在安装有ZKFC的机器上开启一个新的窗口,连接zookeeper客户端 ,连接node02zkCli.sh -server node02:2181,ls / 可以看见根目录下的内容,使用get /zookeeper可以获取到此目录下的内容。
此时可以看见根目录下,相比于之前(未启动zkfc和集群之前)多了hadoop-ha

此时获取的两个目录中的内容都为node01.

下面试验ha中的自动故障转移,此时在浏览器访问http://node01:9870 、http://node02:9870可以看到可视化界面。


试验1:主节点宕机,等待节点从standby变为active状态。使用hdfs --daemon stop namenode停止namenode
此时node01:9870已经不可访问,而node02节点状态转换变为active,在我们的zookeeper客户端中,此时再次获取内容。


试验2:模拟网络通信中的通信中断问题,也就是中断zkfc与zookeeper之间的通信中断。使用hdfs --daemon stop zkfc
此时的现象是node01会从standby切换到active状态,而node02变为standby状态。
注意,所有的节点启动都是会生成日志的,如果发现启动不成功的话,看看日志记录报错信息,根据信息查找,一般是配置文件错了,可以将配置文件拷贝到nodepad++中查看,有很多就是因为一个符号,或者空格导致配置文件报错,一切皆错
5. 总结
大数据学习的核心就是hadoop,本次学习了hadoop的文件系统,对于文件系统中的知识有所了解,主从节点之间的交互,以及DataNode与journalNode之间,NameNode之间的交互,两个NameNode为了数据同步,会通过一组称作JournalNodes的独立进程进行相互通信,DataNode在NameNode上注册以后,一段时间向NameNode报告所有的块信息。后面在Hadoop 3.x中引入了HA高可用,使用主备节点,利用zookeeper和ZKFC的之间的通信来实现宕机或者通信中断等情况的自动故障转移,保证系统的高可用性。最大的重点在于集群,集群的每台机器配置都是相同的,只是ip地址不同罢了,学习hadoop主要的配置文件就是hadoop-env.sh、hdfs-site.xml、core-site.xml等文件。继续加油!
