本次集群的搭建是在之前的伪分布集群的基础上实现的,如果没有搭建好伪分布集群,可参看之前的详细教程:
如果按照以上的步骤成功搭建了hadoop伪分布集群,那么实现真正的集群搭建就很简单了。本次是在虚拟机下搭建了1个NameNode节点和3个DataNode节点的集群(NameNode节点也作为一个DataNode节点)。
----------------------------------------------------------------------------------------------------
hadoop集群搭建
1、克隆之前搭建好的伪分布集群系统,创建另外两个节点作为DataNode节点work02、work03(或者按照同样的步骤单独创建也可以)。
2、配置IP地址
按照之前的配置方式配置即可(注意,要使三台机器在同一个网段里)。
将work01机器的IP地址配置为192.168.26.101
将work02机器的IP地址配置为192.168.26.102
将work03机器的IP地址配置为192.168.26.103
3、修改机器名
利用命令sudo vi /etc/sysconfig/network
work02机器修改为work02

将work03机器修改为work03
4、配置相应的IP地址映射
使用命令sudo vi /etc/hosts
在work01、work02、work03上均配置如下内容

4、配置ssh免密登录(关键步骤)
(1)首先利用命令ssh-keygen -t rsa 在每台机器上生成密钥对(work01已经有了,就不要再生成了),如果是克隆的系统,这时候生成会提示已经存在,直接覆盖即可
(2)然后利用命令 cat id_rsa.pub >> authorized_keys 将各自对应的密钥公钥添加到自己的authorized_keys中(详细步骤可参看之间的教程)
(3)最后将其他机器的id_rsa.pub也添加到当前的authorized_keys中
完成以上步骤后,每台机器的authorized_keys的内容大致如下:
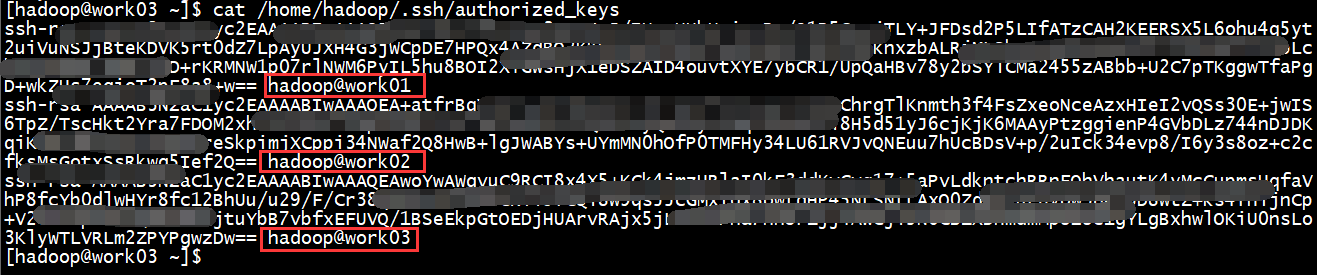
配置完成后,可以work01机器上使用命令 ssh work02 远程登录work02机器,使用exit退出登录。如果不需要密码登录成功,这说明ssh免密登录成功
5、修改相关配置文件
(1)hdfs-site.xml文件
将其内容修改为3,我们之前伪分布集群配置的是1。现在我们有三台DataNode节点,这时候就可以设置副本数为3了。
<configuration>
<property>
<value>dfs.replication</value>
<name>3</name>
</property>
</configuration>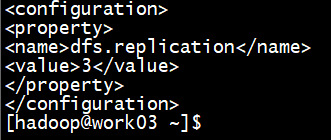
(2)slaves文件
在该文件中添加另外两个DataNode机器名,之前伪分布只添加了work01(为防止出错,每台机器都修改吧)

(3)其他文件保持和work01的配置相同即可。
6、找到每天机器上配置的hadoop.tmp.dir路径下的data文件夹,将其删除。我这里是/home/hadoop/app/hadoop-2.4.1/data
然后使用命令hadoop namenode -format初始化集群
---------------------------------------------------------------------------------------------------------------------
至此,hadoop集群已经配置成功,可以使用命令start-dfs.sh和start-yarn.sh启动集群,或者start-all.sh启动也可以(不推荐)。
启动完毕,可以通过以下方式查看集群是否启动成功
1、查看启动的进程
在NameNode节点机器上(work01),可以看到如下进程
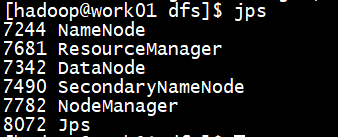
而DataNode节点机器上(work02、work03),可以看到如下进程

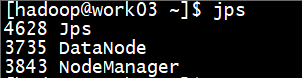
2、通过web服务查看
浏览器输入http://work01:50070
查看DataNode节点个数
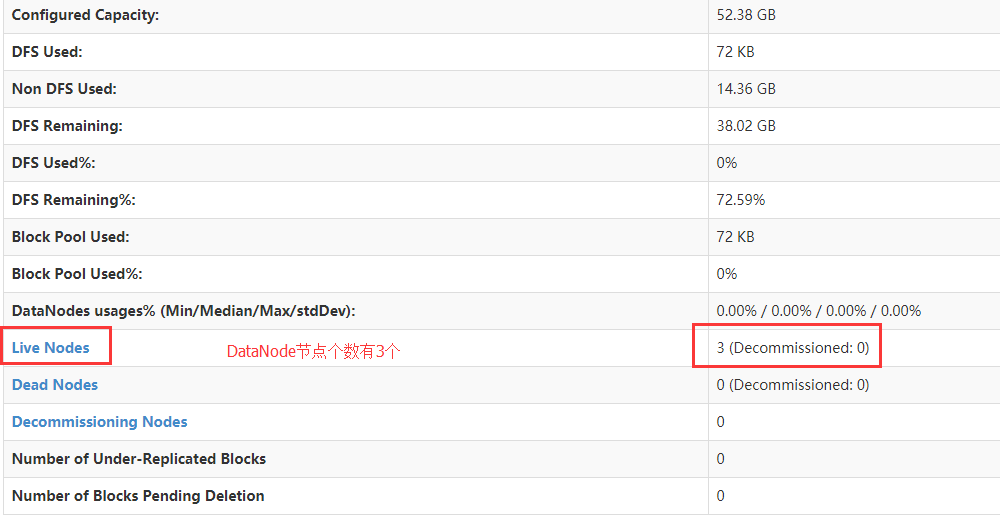
还可以查看详细的DataNode节点信息
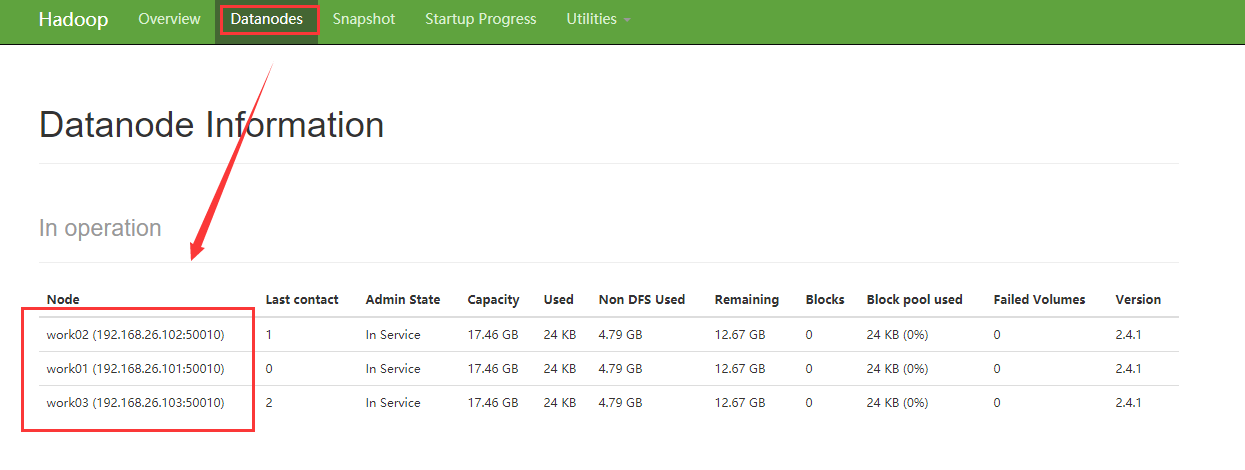
===========================================================
可能会出现DataNode启动不了的问题
原因可能是NameNode和DataNode的clusterID不一致,造成不一致的原因可能是多次使用hadoop namenode -format 。因为每次初始化的时候,NameNode都会重新生成clusterID,而DataNode却只是在最初的时候生成,之后便不再更新
