Fully Convolutional Networks for Semantic Segmentation
语义分割意味着将图片的每一个像素点进行分类。
本论文采用一种端到端的全卷积神经网络来实现语义分割。
文章主要内容:
- 从图像分类到语义分割
- 上采样
- 输出融合
- Fine-tuning
- 结果
从图像分类到语义分割
在解决分类问题的时候,简单来说,我们的输入经过卷积层和全连接层后输出一个预测的标签。如下图所示:
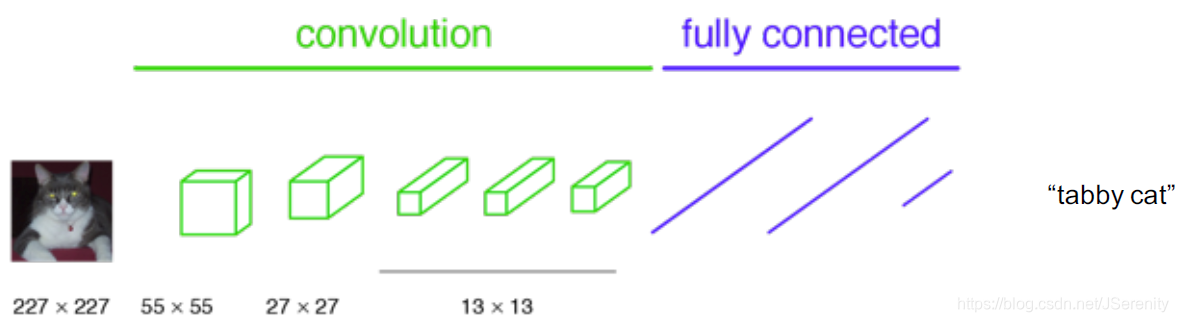
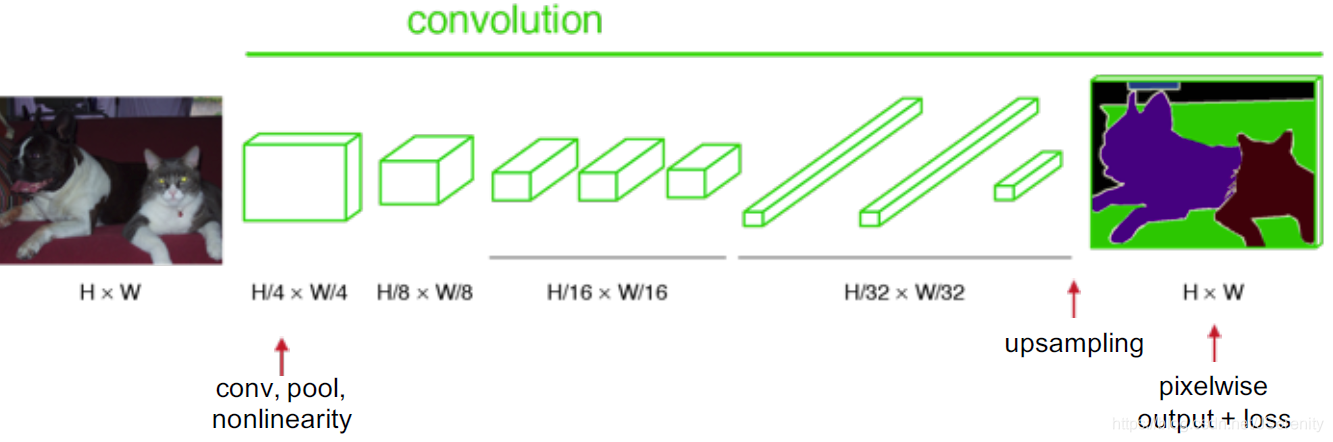
将用于分类网络最后几个全连接层取掉,用1x1的卷积层代替。将输出上采样操作,我们可以得到pixelwise的输出:
上采样
卷积是是输出大小变小的过程。因此,上采样可以是输出的大小变大。下图蓝色块是输入,绿色块为输出。
(具体上采样的细节需要补充)
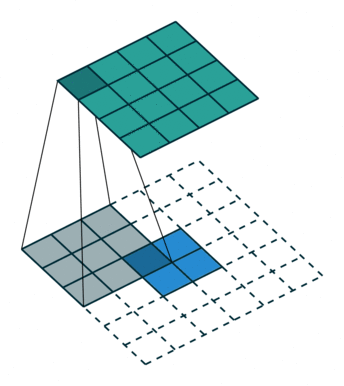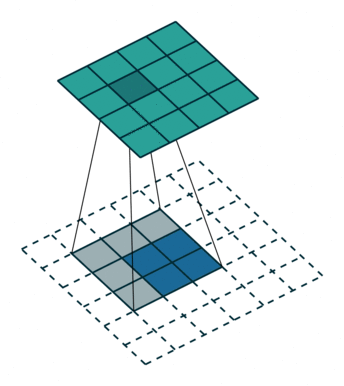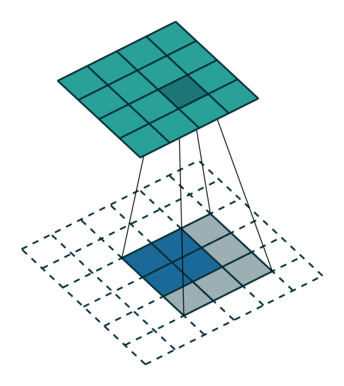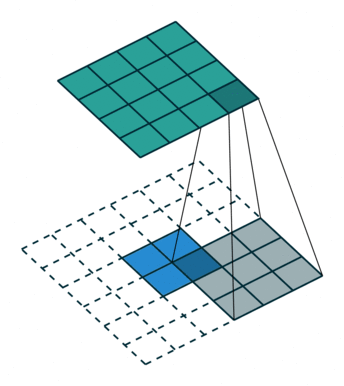
输入融合
(具体融合的细节需要补充)
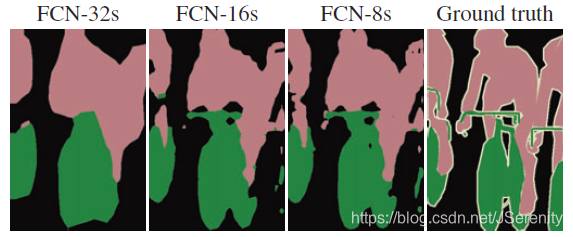
经过卷积层7后,这时候的输出很小,32倍的上采样使输出的大小和输入的大小相同。但是这样输出的结果比较粗糙。把它称为FCN-32s。这是因为,在深层卷积层,很多位置信息丢失了。这同时意味着,浅层的卷积层包含更多的位置信息。将浅层的输出和深层输出结合起来,可以使模型做出局部精细的预测,而又能兼顾全局结构。
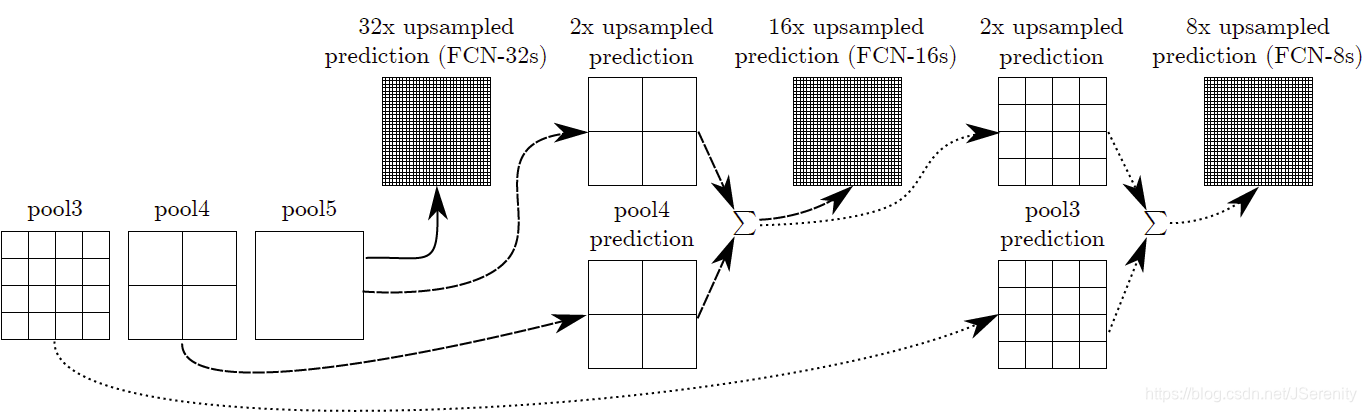
最后Chanel为21,代表20个类别+1个背景。
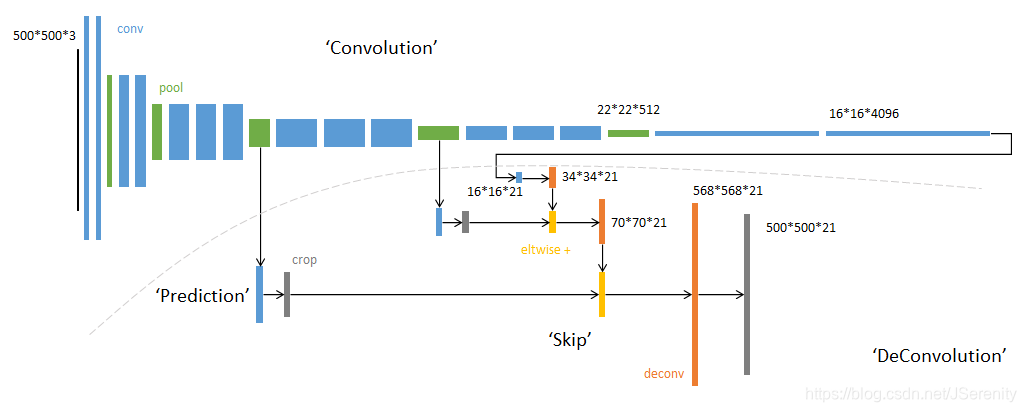
将pool5的结果2倍上采样后和poo4加起来,然后进行16倍的上采样得到结果称为FCN-16s。如上图所示,同样的原理得到FCN-8s。可以看出结果越来越精细。
融合的操作实际上就像AlexNet, VGGnet和GoogLeNet用到的boosting/ensemble技术。将不同模型的结果加在一起使得预测更准确。
Fine-tuning
因为训练时间的原因,从头训练整个网络是不可取的。作者发现fine-tune所有的网络层效果最好。训练过程分为三个阶段:
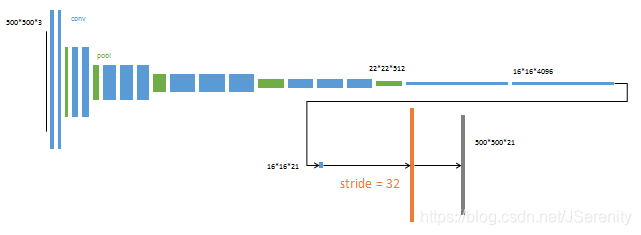
- 以完整的VGG16网络为初始化。从特征小图(16164096)预测分割小图(161621),之后直接32倍上采样得到与输入图像大小相同的结果。 把这个网络称为FCN-32s。这个fine-tune过程在单GPU上花费了三天时间,后面两个阶段各花费一天时间。
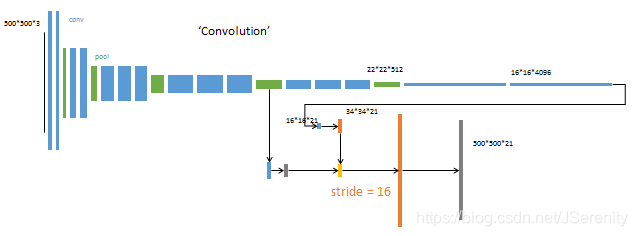
- 先将卷积层的输出2倍上采样,然后和pool4的结果相融合。最后进行16倍的上采样得到输出结果。把这个网络称为FCN-16s。
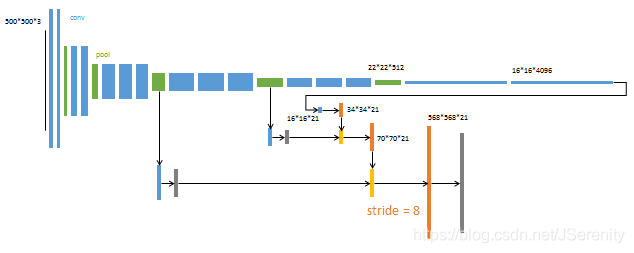
- 同理,上一步融合后再进行一个2倍的上采样,再与pool3的结果相融合。最后进行8倍的上采样得到输出结果。把这个网络称为FCN-8s。
结果


论文:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf
参考:
https://towardsdatascience.com/review-fcn-semantic-segmentation-eb8c9b50d2d1