一、语义分割前言
1.常见的分割任务
分割的精细程度逐次递增,难度也逐次递增。
| 常见分类任务 | 含义 | 典型网络 |
|---|---|---|
| 语义分割 (semantic segmentation) | 对于每个像素分配一个类别,但是同一类别之间的对象不会区分 | FCN |
| 实例分割(instance segmentation) | 把一个类别里的具体的一个个对象(具体的例子)分割开 | Mask RCNN |
| 全景分割(panoramic segmentation) | 在分割对象的同时对背景进行分割 | Panoptic FPN |
2.常见的数据集格式
PASCAL VOC: 在该数据集中主要包含20个目标类别,另外该数据集是以调色版的模式存储PNG图片(忽略边缘以及忽略像素的损失)。
比如像素0对应的是(0,0,0)黑色;像素1对应的是(127,0,0)深红色;像素255对应的是(224,224,119)
MS COCO: MS COCO是一个非常大型且常用的数据集,其中包括了目标检测,分割,图像描述等;针对图像中的每一个目标都记录了多边形坐标。
3. 语义分割得到结果的具体形式
使用mask蒙板(加上调色板之后的效果)使得每个像素数值对应类别索引,例如背景像素数值为0在调色版后显示为黑色,飞机像素数值为1显示为红色,人的像素数值为15显示为浅红色。
Q: 为什么不直接显示灰度图片?
A: 直接以灰度图片显示,由于像素数值差别较小,不容易观察,所以使用mask蒙板对其进行调色,显示出不同颜色方便观察,可视化预测结果。
4. 常见语义分割评价指标
- Pixel Accuracy(Global Acc): ∑ i n i i ∑ i t i \frac{\sum_{i}n_{ii} }{\sum_{i}t_i } ∑iti∑inii
分子为预测正确像素的总和,分母为目标类别i的总像素个数。
- mean Accuracy: 1 n c l s ∑ i n i i ∑ i t i \frac{1}{n_{cls}} \frac{\sum_{i}n_{ii} }{\sum_{i}t_i } ncls1∑iti∑inii
- mean IoU: 1 n c l s ∑ i n i i t i + ∑ j n j i − n i i \frac{1}{n_{cls}} \sum_{i}\frac{n_{ii}}{t_i+\sum_{j}n_{ji}-n_{ii} } ncls1i∑ti+∑jnji−niinii
其中,
n i j n_{ij} nij:类别 i i i被预测成类别 j j j的像素个数
n c l s n_{cls} ncls:目标类别个数(包含背景)
t i = ∑ j n i j t_i=\sum_{j}n_{ij} ti=∑jnij:目标类别 i i i的总像素个数(真实标签)
pytorch中是通过构建混淆矩阵对mean IoU进行计算
矩阵的行为真实标签,列为预测标签,我们来看下矩阵的第一个元素:真实标签为0,预测也为0的个数为16;依次类推填满整个矩阵。 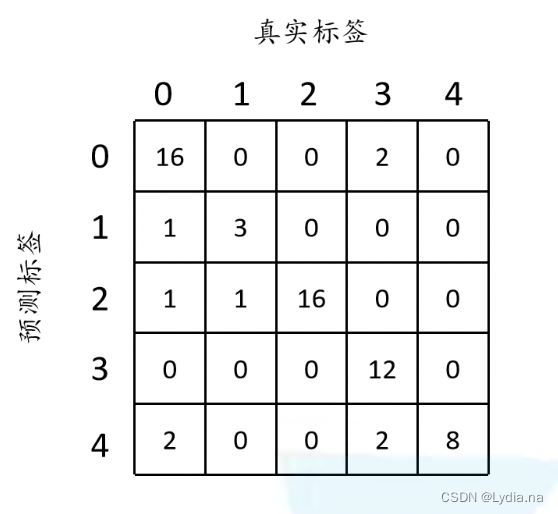
对于整幅图像的accuracy: g l o b a l _ a c c u r a c y = 16 + 3 + 16 + 12 + 8 64 ≈ 0.859 global\_accuracy=\frac{16+3+16+12+8}{64} \approx 0.859 global_accuracy=6416+3+16+12+8≈0.859
分子为矩阵对角线元素(预测正确个数),分母为总像素个数对于每个类别的accuracy
c l s 0 _ a c c c l s 1 _ a c c c l s 2 _ a c c c l s 3 _ a c c c l s 4 _ a c c 16 20 3 4 16 16 12 12 8 8 \begin{matrix} cls0\_acc & cls1\_acc & cls2\_acc & cls3\_acc & cls4\_acc\\ \frac{16}{20} & \frac{3}{4} &\frac{16}{16} & \frac{12}{12}&\frac{8}{8} \end{matrix} cls0_acc2016cls1_acc43cls2_acc1616cls3_acc1212cls4_acc88
分子为每一类预测正确个数,分母为对应真实标签列元素之和对于每个类别的iou:
c l s 0 _ i o u c l s 1 _ i o u c l s 2 _ i o u c l s 3 _ i o u c l s 4 _ i o u 16 20 + 18 − 16 3 4 + 4 − 3 16 16 + 18 − 16 12 16 + 12 − 12 8 8 + 12 − 8 \begin{matrix} cls0\_iou & cls1\_iou & cls2\_iou & cls3\_iou & cls4\_iou\\ \frac{16}{20+18-16} & \frac{3}{4+4-3} &\frac{16}{16+18-16} & \frac{12}{16+12-12}&\frac{8}{8+12-8} \end{matrix} cls0_iou20+18−1616cls1_iou4+4−33cls2_iou16+18−1616cls3_iou16+12−1212cls4_iou8+12−88
正确个数/(列总数+行总数-正确个数)
5. 语义分割标注工具
Labelme: 手工标注;
EISeg: 百度开源的半自动标注工具,Paddle框架。
二、目标检测两种卷积
在目标检测中通常会使用区别于传统卷积的的方式:转置卷积 和 膨胀卷积。
1.转置卷积
转置卷积Transposed Convolution,又名fractionally-strided convolution、deconvolution.另外转置卷积起到上采样的作用。
首先明确两点:
- 转置卷积不是卷积的逆运算
- 转置卷积也是卷积
转置卷积运算步骤:
- 在输入特征图元素间填充 s − 1 s-1 s−1行、列0
- 在输入特征图四周填充 k − p − 1 k-p-1 k−p−1行、列0
- 将卷积核参数上下、左右翻转
- 做正常卷积运算(填充0,步距1)
k : k: k:为卷积核大小
s : s: s:为转置步长,并不是正常卷积的步长
p : p: p:padding
H o u t = ( H i n − 1 ) × s t r i d e [ 0 ] − 2 × p a d d i n g [ 0 ] + k e r n e l s i z e [ 0 ] W o u t = ( W i n − 1 ) × s t r i d e [ 1 ] − 2 × p a d d i n g [ 1 ] + k e r n e l s i z e [ 1 ] \begin{matrix} H_{out}=(H_{in}-1)\times stride[0]-2\times padding[0]+kernel_size[0]\\ W_{out}=(W_{in}-1)\times stride[1]-2\times padding[1]+kernel_size[1] \end{matrix} Hout=(Hin−1)×stride[0]−2×padding[0]+kernelsize[0]Wout=(Win−1)×stride[1]−2×padding[1]+kernelsize[1]
若要仔细理解转置卷积,我们先来看看普通卷积的计算过程。
普通卷积
通常理解卷积的时候,都会将其理解为卷积核在原图像上一个位置一个位置进行滑动计算,但是在实际计算过程中,并不是这样的,因为这样的效率很低。计算机会将卷积核转化为等效的矩阵,将输入转化为向量。通过输入向量和卷积核矩阵相乘得到输出向量,再将输出向量经过整合输出二维特征。具体操作步骤如下图所示:
- 将卷积核转化为输入图像的等效矩阵(构建稀疏矩阵)




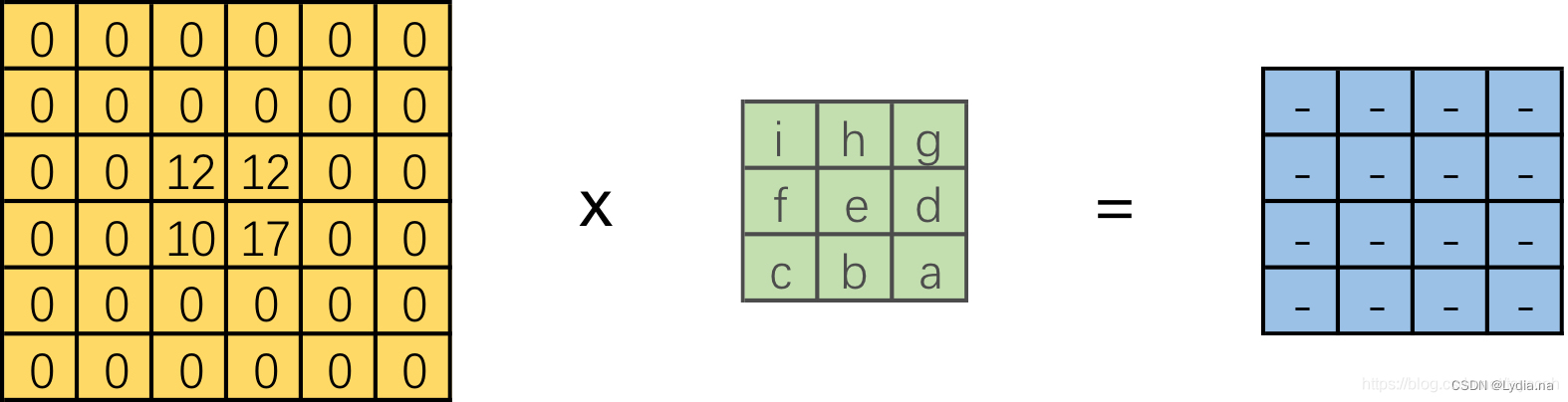
我们将 1 ∗ 16 1*16 1∗16的行向量乘以 16 ∗ 4 16*4 16∗4的矩阵,得到了 1 ∗ 4 1*4 1∗4的行向量。
若反过来将一个 1 ∗ 4 1*4 1∗4的向量✖️一个 4 ∗ 16 4*16 4∗16的矩阵是不是就能得到一个 1 ∗ 16 1*16 1∗16的行向量呢? 这便是转置卷积的思想!
转置卷积
对应上面的普通卷积,可以得到转置卷积公式:
O T × C T = I T O^{T}\times C^{T} = I^{T} OT×CT=IT
如下图所示:

对照着普通的卷积,我们将这个矩阵分解,更形象地理解一下:
- 将输入还原为 2 ∗ 2 2*2 2∗2的张量,同时将得到的 4 ∗ 16 4*16 4∗16矩阵的每个列向量转化为16个卷积核,分别做卷积;
- 单个卷积操作:

- 得到的全部结果:

- 结合整体看可以发现仿佛有一个更大的卷积核在 2 ∗ 2 2*2 2∗2大小的输入滑动,每次卷积对应一部分,我们将其补全:
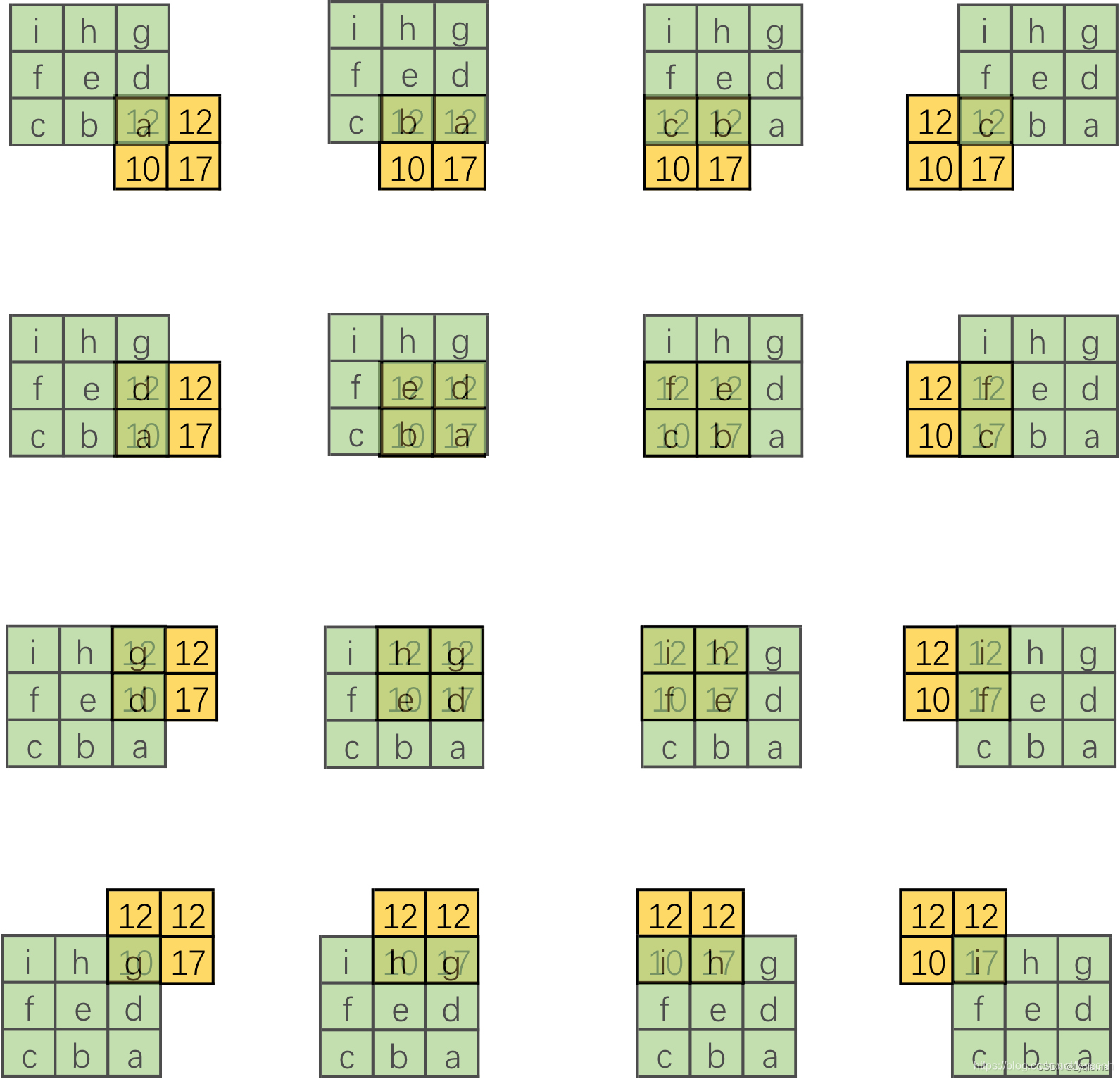
- 可发现大卷积核是原卷积核旋转得到,所以我们在可视化转置卷积中,将卷积核旋转180度再进行卷积:
2.膨胀卷积
膨胀卷积(Dilated convolution)又名空洞卷积,该卷积方法的提出是由于在图像分割领域中,图像输入到CNN中,FCN先像传统CNN那样对图像做卷积再pooling,降低图像尺寸的同时增大感受野,但是由于图像分割预测是pixel-wise的输出,所以要将pooling后较小的图像尺寸上采样upsampling到原始的图像尺寸进行预测,之前的pooling操作使得每个pixel预测都能看到较大的感受野信息。因此图像分割FCN有两个关键点,一是pooling减小图像尺寸增大感受野,另一个是upsampling扩大图像尺寸。在先减小后增大尺寸的过程中,肯定有一部分信息因此损失,那么有没有一种操作不通过pooling也能有较大的感受野看到更多信息呢?答案就是dilated conv。

其作用主要是可以:
- 增大感受野: 所谓增大感受野,我们可以通过感受野的计算公式实际计算下,感受野计算公式如下: r l = r l − 1 + ( k l − 1 ) × j l − 1 r_l=r_{l-1}+(k_l-1)\times j_{l-1} rl=rl−1+(kl−1)×jl−1,其中 r l r_l rl为第 l l l层感受野, k l k_l kl为第 l l l层卷积大小, j l j_l jl为第 l l l层卷积步长;一般第一层的感受野大小就是
Conv1的卷积核大小。
以下表的网络结构为例,我们计算一下感受野:
| No. | Layers | Kernel Size | Stride |
|---|---|---|---|
| 1 | Conv1 | 3 × 3 3\times3 3×3 | 1 |
| 3 | Conv2 | 3 × 3 3\times3 3×3 | 1 |
| 3 | Conv3 | 3 × 3 3\times3 3×3 | 1 |
感受野初始值 l 0 = 1 l_0=1 l0=1,每层感受野计算过程如下:
l 0 = 1 l_0=1 l0=1
l 1 = 1 + ( 3 − 1 ) = 3 l_1=1+(3-1)=3 l1=1+(3−1)=3
l 2 = 3 + ( 3 − 1 ) × 1 = 5 l_2=3+(3-1)\times1=5 l2=3+(3−1)×1=5
l 3 = 5 + ( 3 − 1 ) × 1 = 7 l_3=5+(3-1)\times1=7 l3=5+(3−1)×1=7
- 保持原输入特征图的宽高: 使用空洞卷积,在不使用Max Pooling层改变特征图大小的前提下增加感受野。
Gridding effect:
在实现空洞卷积的过程中常出现如下图所示的Gridding effect 的问题,

- (a) 中从左到右分别使用 3 × 3 3\times3 3×3的卷积,膨胀因子固定为2的三个卷积叠加使用后的对感受野的印象,从结果看会发现这样的卷积对感受野的提取并不是连续的,只是一部分像素的离散值。
- (b)同样是三个 3 × 3 3\times3 3×3卷积,但是膨胀因此依次设置为 1 , 2 , 3 1,2,3 1,2,3,在这种情况下的感受野大小与第一种情况相同但是覆盖了感受野中所有的像素值。
Hybrid Dilated Convolution(HDC):
在《Understanding Convolution for Semantic Segmentation》中提出一系列方法避免Gridding effect :
- 提出卷积中两个非零元素的最大距离计算公式,通过计算公式选择膨胀因子;
- 膨胀因子设置为锯齿状分布;
- 膨胀系数公约数不能大于1;
三、FCN网络
FCN全称为(Fully Convolutional Networks for Semantic Segmentation),作为首个端对端的针对像素级别预测的全卷积网络,将全连接层全部替换为卷积层。是经典的目标检测网络,简单又有效。
网络结构:
FCN网络结构如下所示,是通过将VGG16网络最后三层的全连接网络替换为全卷积网络, 输出结果也变为一张热力图,而该热力图通过上采样最终就能获得我们所需要的分割结果:
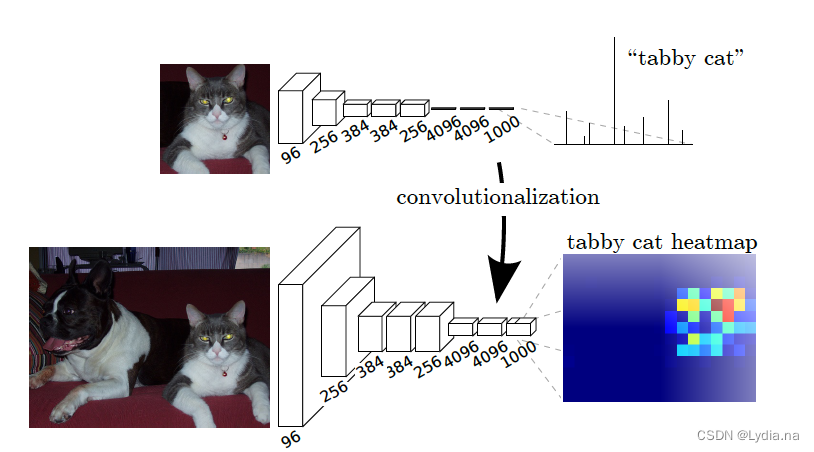
Convolutionalization
-
在原始VGG网络中使用3个全连接层,最后得到1000个类别的预测值,通过softMax可知对于每一个类别的概率,针对1000个数值可视化得到柱状图的图片,若概率越大,柱状图高度越高。
-
在传统网络若输入图像的尺寸是固定的(在没有全局池化层的时候),如果我们将全连接层换成卷积层,输入尺寸就不受限制,Convolutionalization就是这样实现的。如果我们的输入大于 224 × 224 224 \times 224 224×224的话,那么得到的输出宽高肯定是大于1的,此时得到的输出是一个2D的数据,将其可视化为一个热力图形式。
-
VGG16后三层为全连接时,输入 7 × 7 × 512 7\times7\times512 7×7×512的特征图,经过
flatten之后包含 25088 25088 25088个参数,由于每个节点都要与输出的一个节点连接,所以经过FC1的参数量为 25088 × 4096 = 102760448 25088\times4096=102760448 25088×4096=102760448(在忽略偏执的情况下) -
VGG16后三层为卷积层时,经过
Conv(7*7,s1,4096)(padding可调),Conv参数量为 7 × 7 × 512 × 4096 = 102760448 7\times7\times512\times4096=102760448 7×7×512×4096=102760448。两者得到的参数量是一样的,但是通过卷积处理可以保留高度和宽度信息,而flatten已经失去了高宽信息。
Cross Entropy Loss
对于每个像素计算交叉熵损失,再对所有像素的交叉熵求平均的操作得到最终的损失。
1. FCN-32s

- VGG16 backbone对应的是三个全连接层之前的部分。通过backbone得到的图像下采样了32倍,得到的输出为 h 32 × w 32 × 512 \frac{h}{32} \times \frac{w}{32} \times512 32h×32w×512;由于在卷积过程中设置的 p a d d i n g = 3 padding=3 padding=3所以经过
fc6得到的尺寸为 h 32 × w 32 × 512 \frac{h}{32} \times \frac{w}{32} \times512 32h×32w×512;由于fc7为 1 × 1 1\times 1 1×1步长为1的卷积所有输出图片尺寸也不发生变化;fc8得到的输出是由分类的类别所决定为 h 32 × w 32 × n u m _ c l s \frac{h}{32} \times \frac{w}{32} \times num\_cls 32h×32w×num_cls;最后再经过转置卷积将其上采样32倍恢复到原图大小 h × w × n u m _ c l s h \times w \times num\_cls h×w×num_cls(由于上采样方法的学习参数被冻结住了可参考双线性插值的方法)。
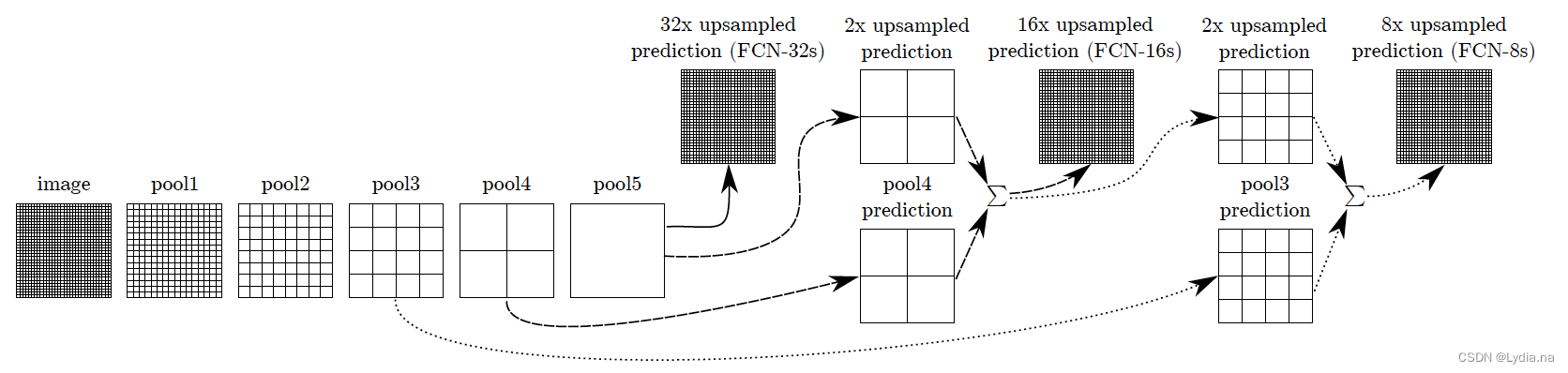
2. FCN-16s
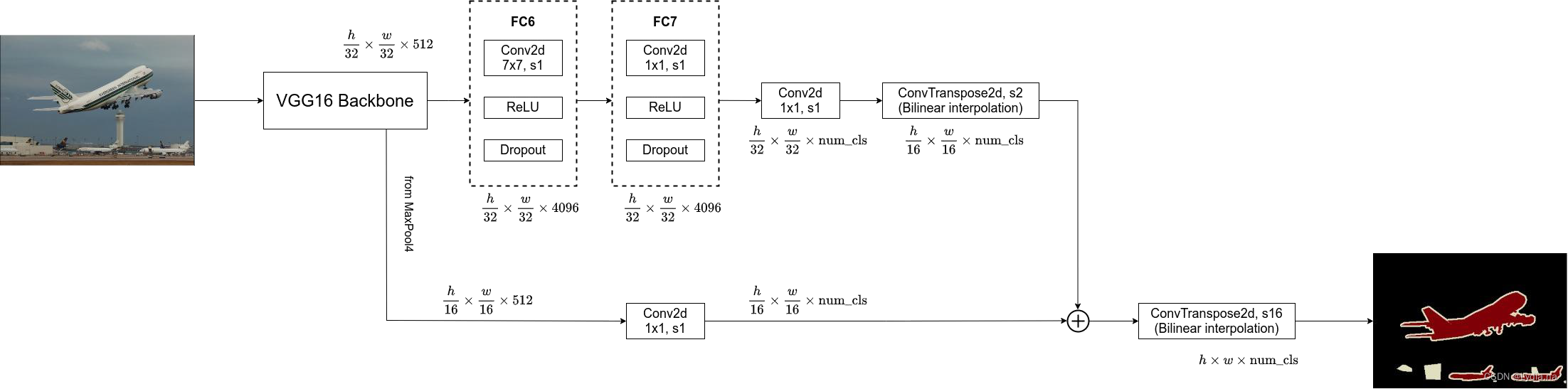
- FCN-16s网络的
Backbone,fc6,fc7和Conv2d部分和FCN-32s的相同,在Conv2d后的转置卷积的时候不再是32倍,而是上采样了2倍,得到的输出是 h 16 × w 16 × n u m _ c l s \frac{h}{16} \times \frac{w}{16} \times num\_cls 16h×16w×num_cls;在VGG-16网络中Max pooling4中的输出是 h 16 × w 16 × 512 \frac{h}{16} \times \frac{w}{16} \times 512 16h×16w×512,再经过一层Conv2得到 h 16 × w 16 × n u m _ c l s \frac{h}{16} \times \frac{w}{16} \times num\_cls 16h×16w×num_cls的输出,然后再将二者相加(矩阵加法),再将其进行上采样16倍得到 h × w × n u m _ c l s h \times w \times num\_cls h×w×num_cls的分割图。
3. FCN-8s
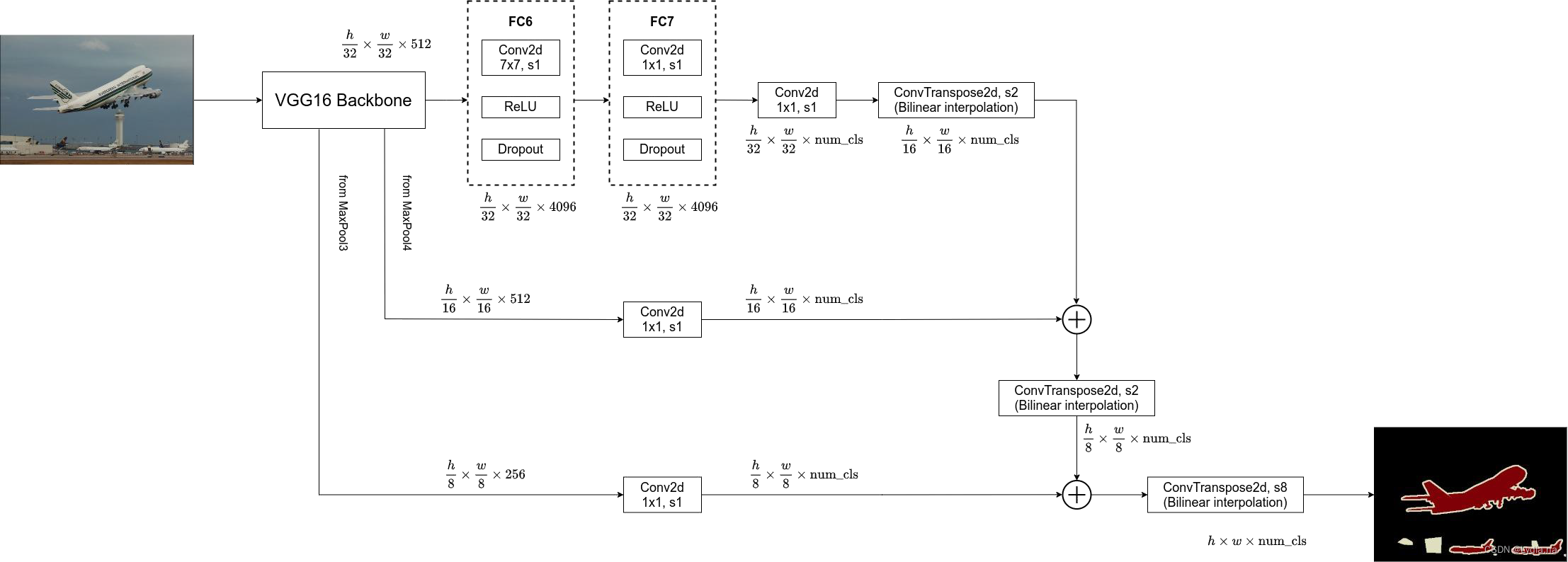
- 在FCN-16s的基础上再加上VGG-16来自
Max pooling3的输出 h 8 × w 8 × 256 \frac{h}{8} \times \frac{w}{8} \times 256 8h×8w×256,再经过一层Conv2得到 h 8 × w 8 × n u m _ c l s \frac{h}{8} \times \frac{w}{8} \times num\_cls 8h×8w×num_cls的输出,然后将来自FCN-16的下采样八倍的特征图于其相加,最后上采样8倍得到 h × w × n u m _ c l s h \times w \times num\_cls h×w×num_cls的分割图。
四、DeepLab
DeepLab有三个系列,分别是V1,V2,V3现在1,2版本不主流,常用3版本,所以简单介绍1和2,着重介绍3版本。
1. DeepLab V1
DeepLab v1论文提出两个难点分别是Signal Sampling和Spatial Insensitivity.
- Signal Sampling指的是网络进行下采样时会使图片的分辨率降低,针对这个问题作者提出膨胀卷积;
- Spatial Insensitivity指的是空间不敏感问题(又指空间不变形),语义分割是需要空间敏感的,对于同一物体的不同观察需要结果不同。
DeepLab v1的网络结构主要是由VGG-16改进升级而来,在全连接层之前的网络结构差不多,额外多了三个模块CRF模块、MSc模块、Large FOV模块。
1.1 膨胀卷积
针对下采样时分辨率变低作者提出膨胀卷积,从而获得更大的感受野。
1.2 FC-CRF(Conditional Random Field)
全连接CRF。DeepLab V1最后使用全连接CRF后处理来进一步修正分割分割掩膜。CRF是一种概率模型,在给定周围像素的条件下预测目标像素,将一张图像的所以像素作为条件输入。这对于分割掩膜边界的优化十分有用,利用像素之间的相关性。
1.3 MSc(Multi-Sclae):
多尺度特征聚合。将输入以及前四层Max pooling后的特征层通过两层多层感知机和网络的最后输出聚合到一起,该模块能稍微提高mean IoU指标但参数量增大,作者不推荐使用。
1.4 LargeFOV(Large field of view):
更大的特征尺寸。DeepLab网络与FCN网络一样是在VGG的基础上将全连接层转化为卷积层,最大下采样率为8倍。fc6原本使用的是4096个 7 × 7 7 \times 7 7×7的卷积核,但是这成了网络的瓶颈,作者将其改为卷积核大小为 3 × 3 3 \times 3 3×3,膨胀因子为12的膨胀卷积,这使得网络的参数量降低,mean IoU为 67.64 67.64% 67.64,训练速度提升。
DeepLab-LargeFOV结构如下表所示:

与VGG16的不同点:
- 第一个Maxpool层由卷积核大小为 2 × 2 2 \times 2 2×2改为 3 × 3 3 \times 3 3×3;
- 第四个Maxpool层的步长改为1,使得该网络最大下采样率为8倍;
Conv5改为 3 × 3 3 \times 3 3×3的膨胀卷积,膨胀因子为2;fc6改为 3 × 3 3 \times 3 3×3的膨胀卷积,膨胀因子为12;- 其余的全卷积层和FCN类似
特点:
- maxpool改成了有重叠的
- 无效化了两个下采样层
- 采用了空洞卷积
2. DeepLab V2
DeepLab V2提出的问题及解决方案:
- 分辨率被降低 :将最后的几个Max Pooling层stride设置为1(分辨率不变),配合使用膨胀卷积;
- 目标的多尺度问题: 将图像缩放到多个尺度分别通过网络进行推荐,然后将多个结构进行融合,这样做计算量较大,为解决该问题提出ASPP模块
- DCNN的不变性会降低定位精度: 和DeepLab V1类似使用CRFs解决,不过V2使用的是fully connected pairwise CRF,相比V1中的fully connected CRF要更高效。
DeepLab V2除了上述优化方法外,还将BackBone更换为ResNet,使得网络速度更快、准确率更高、模型结构简单(通过DCNN和CRF级联)。
2.1 ASPP(Atrous Spatial Pyramid Pooling):
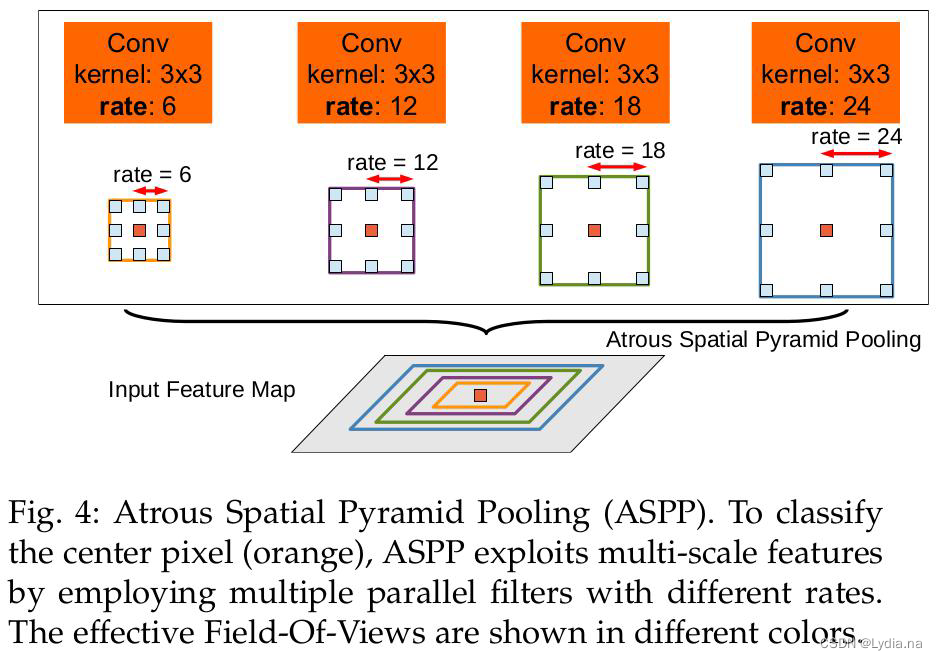
DeepLab-LargeFOV和DeepLab-ASPP网络结构对比如下图所示:
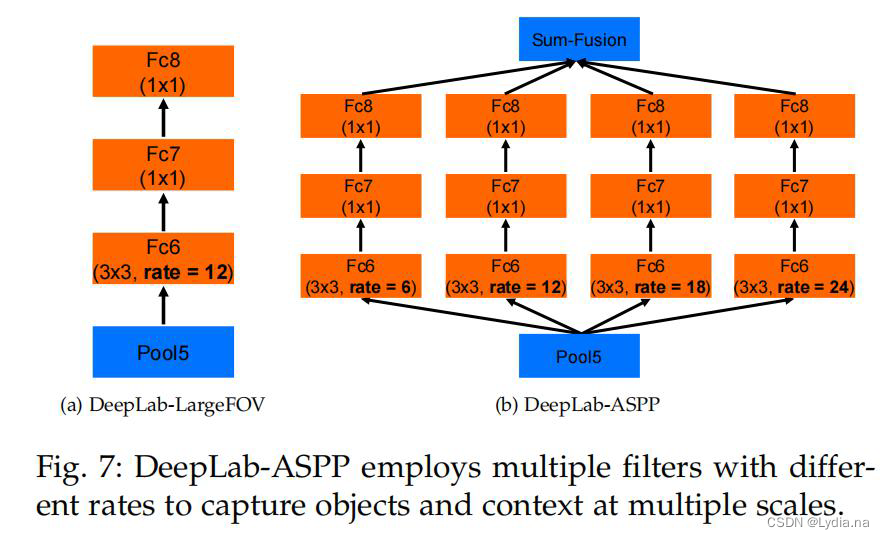
2.2 网络结构
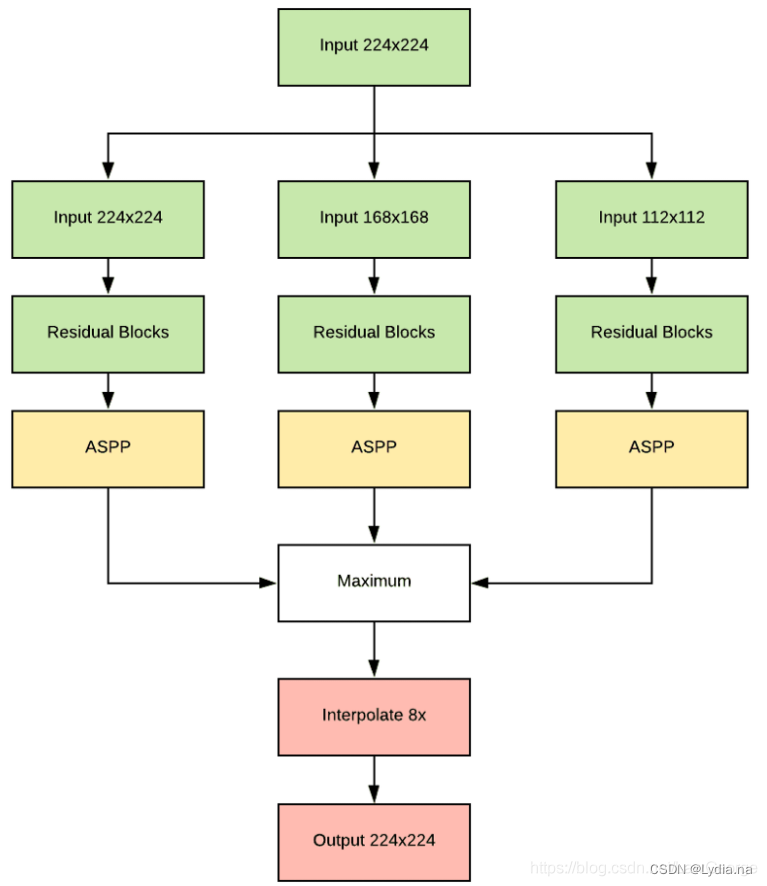
DeepLab V2的输出也是多尺度的:1.0、0.75、0.5,以实现更多种尺度的特征学习和聚合。此外,它还将ResNet作为基础特征提取网络,提升了网络性能和收敛速度。
3. DeepLab V3
DeepLab V3相较于DeepLab V2不同点有:
- 改进ASPP模块
- 引入Cascaded模块
- 引入Multi-Grid
- 取消CRF
3.1 改进ASPP
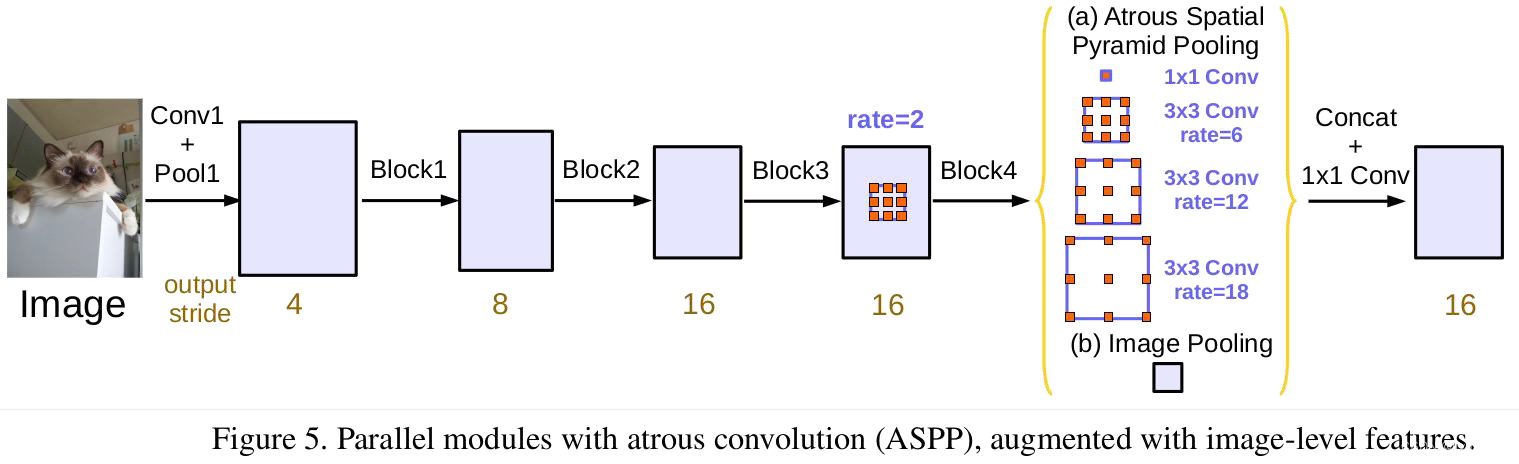
相较于DeepLab V2中的ASPP模块,这里的ASPP模块中添加了一个全局池化(Image Pooling),除此之外,后面添加了 1 × 1 1\times1 1×1的卷积层(包括BN层和ReLu)进行进一步融合。
3.2 Cascaded模块

其中Block1-Block3位原始ResNet网络中的结构,而Block4-Blcok7与ResNet的Block结构相同,但是卷积均为膨胀卷积,每一层的膨胀系数还不一样,这就是Multi-Grid结构,我们还注意到图中由rate这个参数,这里的rate与每一层膨胀卷积的膨胀系数相乘后的值才是该卷积层最后的膨胀系数,我们可以看到在Block4-Blcok7中rate是2,4,6,16依次递增的。
3.3 Multi-Grid
V3中引入一个新的超参数Multi-grid (MG),用于调整空洞卷积的rate。例如,当MG={1,2,4},base rate=2时,一个block中的三层卷积层的rate就会被设置为{2,4,8}。
3.4 取消CRF
最新的分割网络已经足够强大,使用CRF已经不能带来任何性能提升,而且它不能进行端到端的学习以及计算耗时较长。
五、U-Net网络
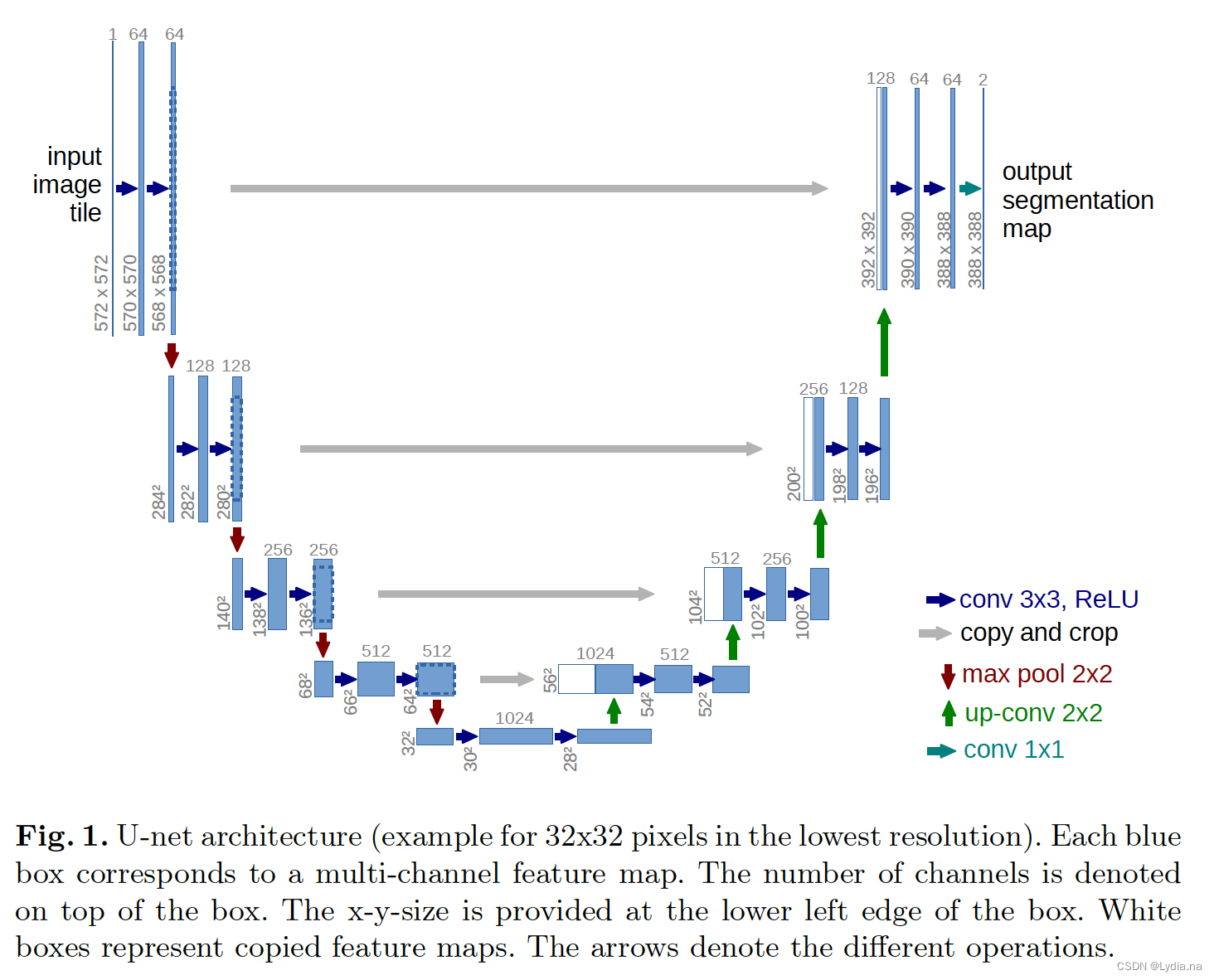
U-Net
UNet发表于2015年的MICCAI,原论文名为《U-Net: Convolutional Networks for Biomedical Image Segmentation》,UNet主要应用与医学影像领域。
参考文章
本文是根据B站up主霹雳吧啦写的记录文章,图侵删
https://blog.csdn.net/tsyccnh/article/details/87357447
https://blog.csdn.net/qq_27586341/article/details/103131674
https://blog.csdn.net/u012862372/article/details/81045593
https://blog.csdn.net/LawGeorge/article/details/111655984
https://towardsdatascience.com/witnessing-the-progression-in-semantic-segmentation-deeplab-series-from-v1-to-v3-4f1dd0899e6e
https://zhuanlan.zhihu.com/p/75333140