一、tensorflow提供的evaluation
Inference and evaluation on the Open Images dataset:https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/oid_inference_and_evaluation.md
该链接中详细介绍了如何针对Open Images dataset数据集进行inference和evaluation,按照此教程,在models/research目录下新建oid文件夹,并将数据集以及验证集下载并放在此文件夹下。后续可能不会用到,待删除。
tensorflow提供的官方detection demo可参考:https://github.com/tensorflow/models/blob/master/research/object_detection/object_detection_tutorial.ipynb
但是后来发现在~/rdshare/detection/detection/py的脚本中,检测结果中有类别,目标框的位置等,可据此计算map,recall等,所以没有继续根据上边的链接继续做。
二、自主计算
在~/rdshare/detection/detection/py脚本中,通过 boxes = detection_graph.get_tensor_by_name('detection_boxes:0') 可获得目标框的坐标。print之后结果如下
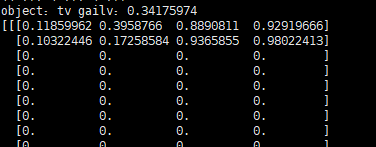
结果中应该是两个物体的坐标。
然后参考https://blog.csdn.net/qq_17550379/article/details/79875784 中的代码,可以计算map


def voc_ap(rec, prec, use_07_metric=False): if use_07_metric: # 11 point metric ap = 0. for t in np.arange(0., 1.1, 0.1): if np.sum(rec >= t) == 0: p = 0 else: p = np.max(prec[rec >= t]) ap = ap + p / 11. else: mrec = np.concatenate(([0.], rec, [1.])) mpre = np.concatenate(([0.], prec, [0.])) for i in range(mpre.size - 1, 0, -1): mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i]) i = np.where(mrec[1:] != mrec[:-1])[0] ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1]) return ap
另外可参考的链接
https://blog.csdn.net/ziliwangmoe/article/details/81415943
https://zhuanlan.zhihu.com/p/37910324
本论文中可考虑不用maP,只计算目标是否出现等方式,或者用yolo做ground truth。