在上一篇博客"使用tensorflow object detection API 训练自己的目标检测模型 (一)"中介绍了如何使用LabelImg标记数据集,生成.xml文件,经过个人的手工标注,形成了一个大概有两千张图片的数据集。
但是这仍然不满足tensorflow object detection API对训练数据的格式要求(API要求tfrecord个格式的数据),所以下面将.xml文件转化为tfrecord格式的文件,
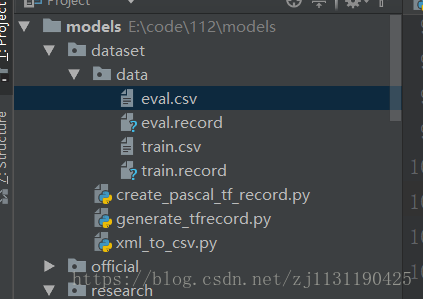
在models工程下新建文件夹dataset,目录结构如图所示:data文件夹用来存放转换的数据。
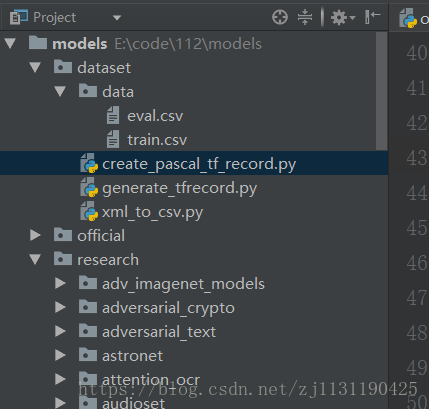
转换过程分为两步:
第一步:将标记生成xml文件转换为csv文件,在dataset下新建xml_to_csv.py文件,代码如下:
import os
import glob
import pandas as pd
import xml.etree.ElementTree as ET
def xml_to_csv(path):
xml_list = []
# 读取注释文件
for xml_file in glob.glob(path + '/*.xml'):
tree = ET.parse(xml_file)
root = tree.getroot()
for member in root.findall('object'):
value = (root.find('filename').text,
int(root.find('size')[0].text),
int(root.find('size')[1].text),
member[0].text,
int(member[4][0].text),
int(member[4][1].text),
int(member[4][2].text),
int(member[4][3].text)
)
xml_list.append(value)
column_name = ['filename', 'width', 'height', 'class', 'xmin', 'ymin', 'xmax', 'ymax']
# 将所有数据分为样本集和验证集,一般按照3:1的比例
train_list = xml_list[0: int(len(xml_list) * 0.67)]
eval_list = xml_list[int(len(xml_list) * 0.67) + 1: ]
# 保存为CSV格式
train_df = pd.DataFrame(train_list, columns=column_name)
eval_df = pd.DataFrame(eval_list, columns=column_name)
train_df.to_csv('data/train.csv', index=None)
eval_df.to_csv('data/eval.csv', index=None)
def main():
# path = 'E:\\\data\\\Images'
path = r'E:\smart city\data_distribution\xml_new' # path参数更具自己xml文件所在的文件夹路径修改
xml_to_csv(path)
print('Successfully converted xml to csv.')
main()
path = r'E:\smart city\data_distribution\xml_new' # path参数更具自己xml文件所在的文件夹路径修改
xml_to_csv(path)
print('Successfully converted xml to csv.')
main()
修改path路径, 运行代码,就可以进行转换:生成两个csv文件
第二步:将生成的csv文件转换为tfrecord格式
在dataset下新建generate_tfrecord.py文件,代码如下:
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
# from object_detection.utils import dataset_util
from research.object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# 将分类名称转成ID号
def class_text_to_int(row_label):
if row_label == 'plate':
return 1
# elif row_label == 'car':
# return 2
# elif row_label == 'person':
# return 3
# elif row_label == 'kite':
# return 4
else:
print('NONE: ' + row_label)
# None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
print(os.path.join(path, '{}'.format(group.filename)))
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = (group.filename + '.jpg').encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(csv_input, output_path, imgPath):
writer = tf.python_io.TFRecordWriter(output_path)
path = imgPath
examples = pd.read_csv(csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
# imgPath = 'E:\data\Images'
imgPath = r'E:\smart city\data_distribution\picyure_new'
# 生成train.record文件
output_path = 'data/train.record'
csv_input = 'data/train.csv'
main(csv_input, output_path, imgPath)
# 生成验证文件 eval.record
output_path = 'data/eval.record'
csv_input = 'data/eval.csv'
main(csv_input, output_path, imgPath)
if row_label == 'plate':
return 1
# elif row_label == 'car':
# return 2
# elif row_label == 'person':
# return 3
# elif row_label == 'kite':
# return 4
else:
print('NONE: ' + row_label)
# None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
print(os.path.join(path, '{}'.format(group.filename)))
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = (group.filename + '.jpg').encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(csv_input, output_path, imgPath):
writer = tf.python_io.TFRecordWriter(output_path)
path = imgPath
examples = pd.read_csv(csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
# imgPath = 'E:\data\Images'
imgPath = r'E:\smart city\data_distribution\picyure_new'
# 生成train.record文件
output_path = 'data/train.record'
csv_input = 'data/train.csv'
main(csv_input, output_path, imgPath)
# 生成验证文件 eval.record
output_path = 'data/eval.record'
csv_input = 'data/eval.csv'
main(csv_input, output_path, imgPath)
这里有两处需要修改:
第一处:
分类号转换为ID:
# 将分类名称转成ID号
def class_text_to_int(row_label):
if row_label == 'plate':
return 1
# elif row_label == 'car':
# return 2
# elif row_label == 'person':
# return 3
# elif row_label == 'kite':
# return 4
else:
print('NONE: ' + row_label)
# None根据自己在LabelImg中打的标签进行修改, 比如我只有plate标签:
第二处:
# imgPath = 'E:\data\Images'
imgPath = r'E:\smart city\data_distribution\picyure_new'
对图片的路径进行修改, 图片应该要与xml文件一一对应的:
运行generate_tfrecord.py文件,可以看到已经生成了两个tfrecord文件:
现在数据转化完毕,开始训练模型之前。要对API做一些配置:
(1)在data文件夹下创建label_map.pbtxtx文件:
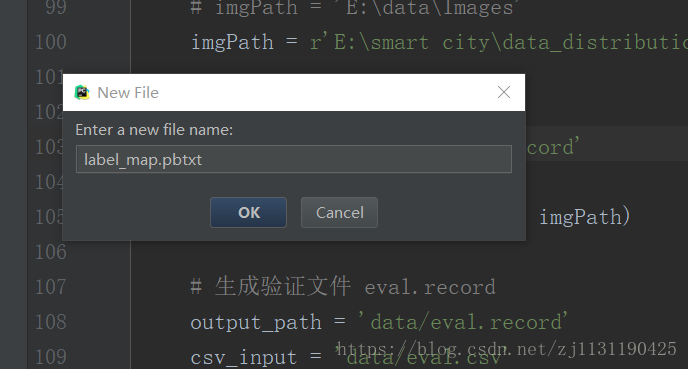
文件内容如下:
item {
id: 1
name: 'plate'
}
item {
id: 2
name: 'xxx'
}
item {
id: 3
name: 'xxx'
}
文件中id 和 name应该和上面修改的函数class_text_to_int()中的相对应:如果有多个检测目标,就继续添加item(我的只有plate一项,后面添加的两个item作为示例,实际运行时会删掉),记得保存pbtxt文件()
(2)下载 需要fine-tune的模型:下载的地址为:https://github.com/tensorflow/models/tree/master/research/slim
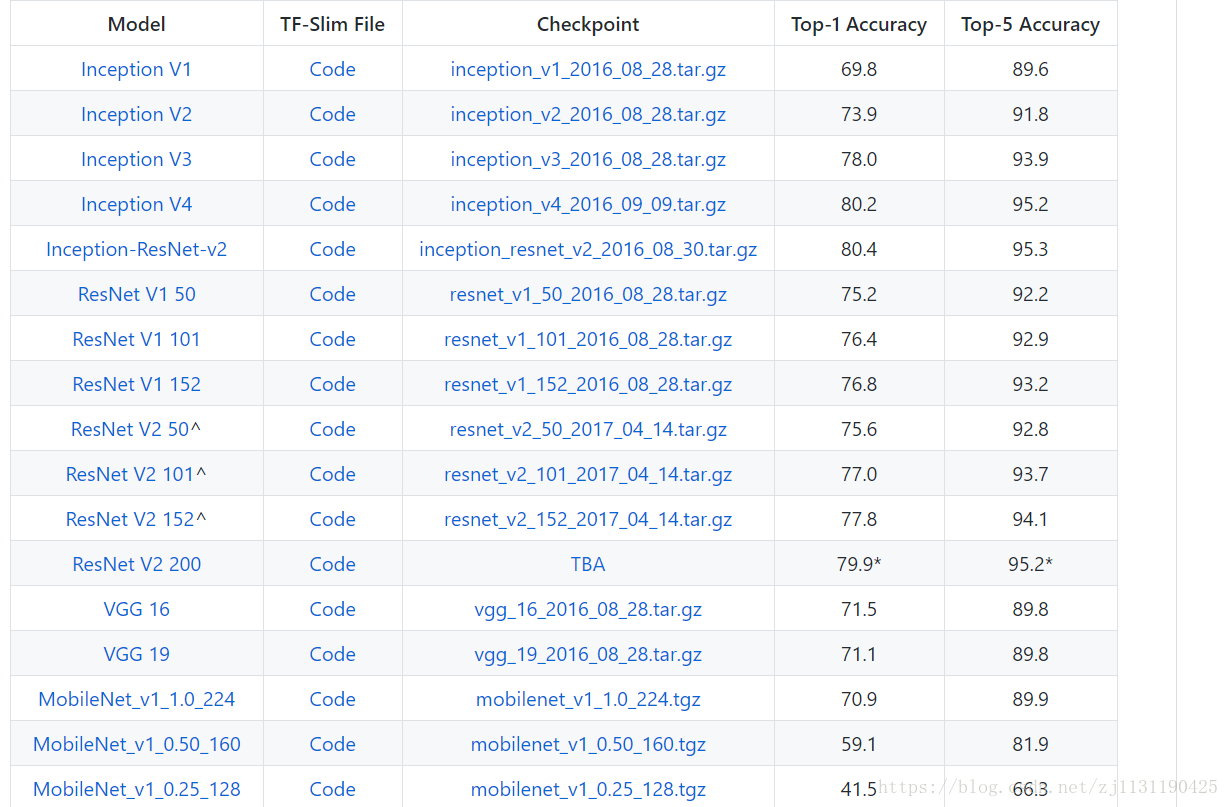
根据需要下载具体的模型,在dataset文件夹下新建fine_tune_model文件夹,将下载的模型解压后,复制三个.ckpt文件放到fine_tune_model文件夹下。
(3)配置管道文件
找到目录research\object_detection\samples\configs\ssd_inception_v2_pets.config文件,将此文件复制到dataset/data文件夹下:
并对以下的地方做出修改:
第一处:第8-9行
ssd {
num_classes: 1 # 贼修改为自己检测的目标的类别数, 例如我的是一个
box_coder {
第二处:151-152行
# 贼修改为自己检测的目标的类别数, 例如我的是一个
box_coder {
第二处:151-152行
fine_tune_checkpoint: "E:/code/112/models/dataset/fine_tune_model/model.ckpt" # 注意修改fine_tune_checkpoint
fine_tune_checkpoint_type: "detection"第三处:169-175行
train_input_reader: {
tf_record_input_reader {
# input_path: "PATH_TO_BE_CONFIGURED/pet_train.record"
input_path: "E:/code/112/models/dataset/data/train.record" # 将 input_path参数改为前面生成train.record文件的路径
}
label_map_path: "E:/code/112/models/dataset/data/label_map.pbtxt" # 同理将这里的路径改为上面生成的label_map.pbtxt文件的路径
}
# 将 input_path参数改为前面生成train.record文件的路径
}
label_map_path: "E:/code/112/models/dataset/data/label_map.pbtxt" # 同理将这里的路径改为上面生成的label_map.pbtxt文件的路径
}
第四处:184-191
eval_input_reader: {
tf_record_input_reader {
input_path: "E:/code/112/models/dataset/data/eval.record" # 将 input_path参数改为前面生成eval.record文件的路径
}
label_map_path: "E:/code/112/models/dataset/data/label_map.pbtxt" # 同理将这里的路径改为上面生成的label_map.pbtxt文件的路径
shuffle: false
num_readers: 1
}# 将 input_path参数改为前面生成eval.record文件的路径
}
label_map_path: "E:/code/112/models/dataset/data/label_map.pbtxt" # 同理将这里的路径改为上面生成的label_map.pbtxt文件的路径
shuffle: false
num_readers: 1
}(4).配置完管道文件后,再到models\research\object_detection\train.py文件,如果遇到train.py文件找不到导入的包,(比如报错 no module named object_detection)
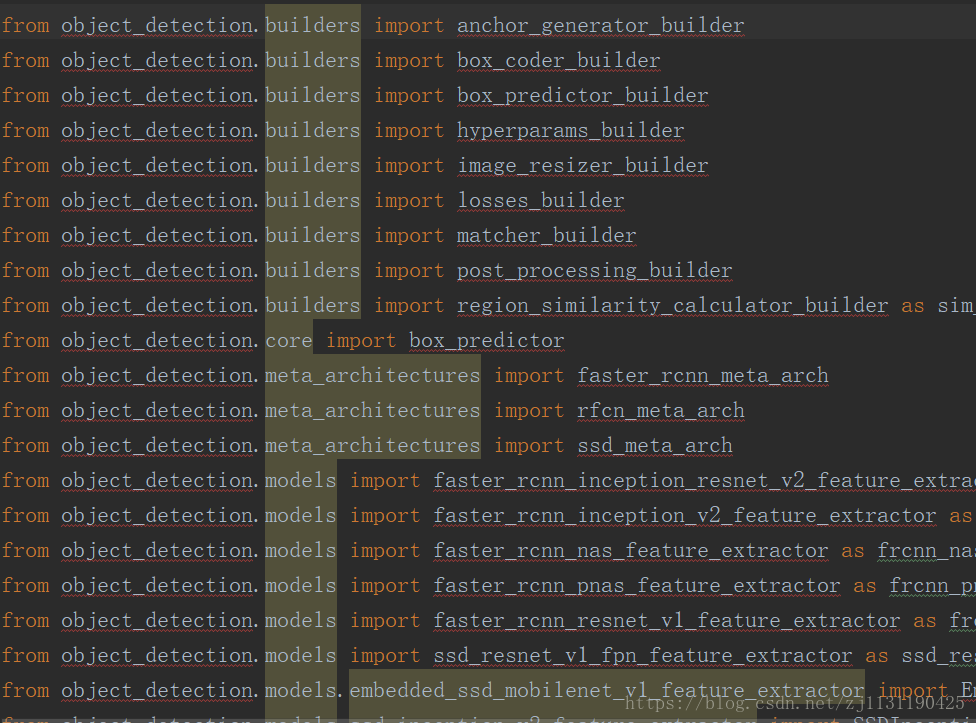

按如下方式修改
# from object_detection import trainer
from research.object_detection import trainer
# from object_detection.builders import dataset_builder
from research.object_detection.builders import dataset_builder
# from object_detection.builders import graph_rewriter_builder
from research.object_detection.builders import graph_rewriter_builder
# from object_detection.builders import model_builder
from research.object_detection.builders import model_builder
# from object_detection.utils import config_util
from research.object_detection.utils import config_util
# from object_detection.utils import dataset_util
from research.object_detection.utils import dataset_util导入他们的完整路径就不会报错了, 对应的models\research\object_detection\trainer.py也要修改:
# from object_detection.builders import optimizer_builder
from research.object_detection.builders import optimizer_builder
# from object_detection.builders import preprocessor_builder
from research.object_detection.builders import preprocessor_builder
# from object_detection.core import batcher
from research.object_detection.core import batcher
# from object_detection.core import preprocessor
from research.object_detection.core import preprocessor
# from object_detection.core import standard_fields as fields
from research.object_detection.core import standard_fields as fields
# from object_detection.utils import ops as util_ops
from research.object_detection.utils import ops as util_ops
# from object_detection.utils import variables_helper
from research.object_detection.utils import variables_helper
# from deployment import model_deploy
from research.slim.deployment import model_deploy
除此之外,运行train.py文件时,还会有大量的no module named object_detection错误,我是一一手动修改导入完整路径,这种方法很不好, 可以通过sys.path.append('上层目录路径')引入上一层的目录:
同时还有找不到no module named net之类的错误, net文件在research/object_detection/slim文件夹下,导入完整的路径就可以解决。
到models\research\object_detection\train.py文件下,在文件中做一些修改:
flags.DEFINE_string('train_dir', r'E:\code\112\models\dataset\training', # 指定模型的输出路径
'Directory to save the checkpoints and training summaries.')
flags.DEFINE_string('pipeline_config_path', r'E:\code\112\models\dataset\data\ssd_mobilenet_v2_coco_self.config', # 配置文件路径
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file. If provided, other configs are ignored')运行train.py文件就可以开始训练了。。。。
训练结果:
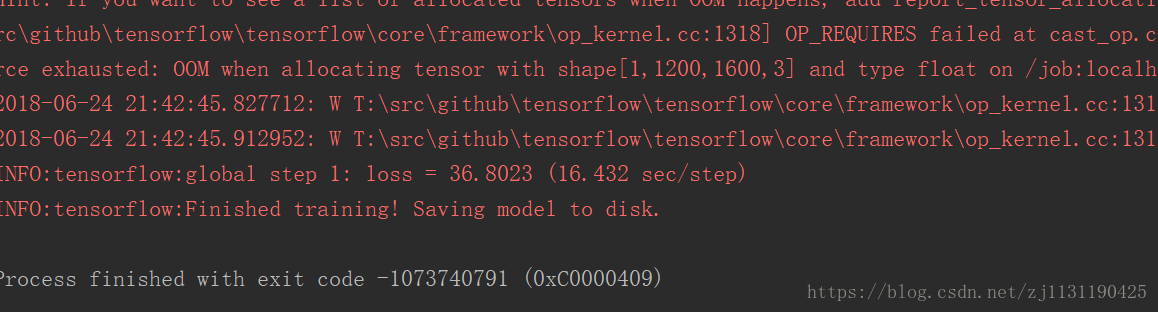
运行代码后发现出现异常:报错的信息为:
INFO:tensorflow:Error reported to Coordinator: <class 'tensorflow.python.framework.errors_impl.ResourceExhaustedError'>, OOM when allocating tensor with shape[1200,1600,3] and type float on /job:localhost/replica:0/task:0/device:CPU:0 by allocator cpu
[[Node: RandomHorizontalFlip/cond/flip_left_right/ReverseV2 = ReverseV2[T=DT_FLOAT, Tidx=DT_INT32, _device="/job:localhost/replica:0/task:0/device:CPU:0"](RandomHorizontalFlip/cond/Switch_1:1, RandomHorizontalFlip/cond/flip_left_right/ReverseV2/axis, ^RandomHorizontalFlip/cond/flip_left_right/assert_positive/assert_less/Assert/Assert)]]
Hint: If you want to see a list of allocated tensors when OOM happens, add report_tensor_allocations_upon_oom to RunOptions for current allocation info.
经过查找,错误的原因应该是显卡内存溢出,我的笔记本跑不了这个模型。
借用了一台1070 16G显卡的游戏本跑一波:
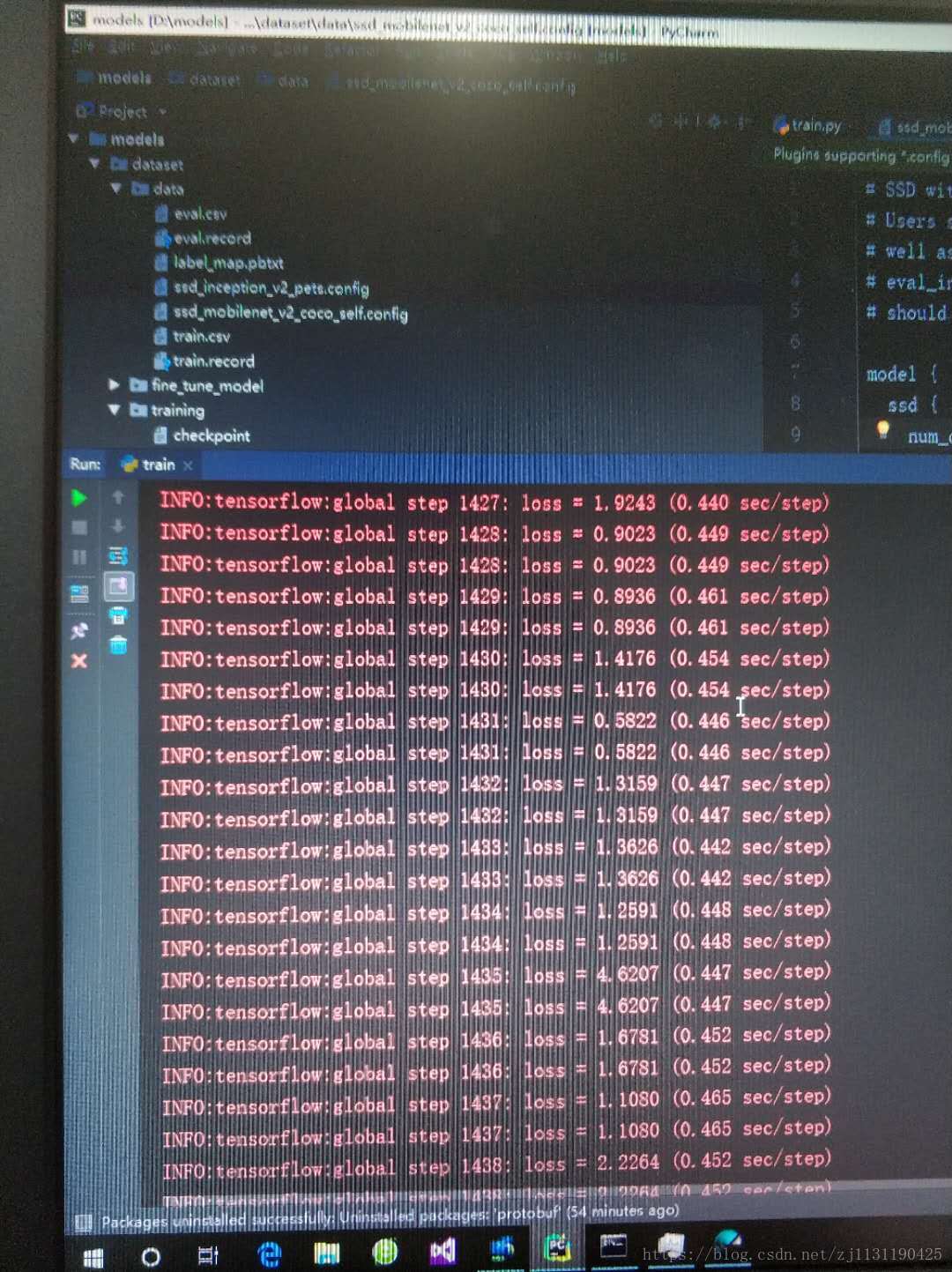
生成的training文件下的模型文件:
(4)导出训练的结果,生成pb文件:
将export_inference_graph.py文件复制到dataset文件夹下,文件的具体内容为:
# Copyright 2017 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
r"""Tool to export an object detection model for inference.
Prepares an object detection tensorflow graph for inference using model
configuration and an optional trained checkpoint. Outputs inference
graph, associated checkpoint files, a frozen inference graph and a
SavedModel (https://tensorflow.github.io/serving/serving_basic.html).
The inference graph contains one of three input nodes depending on the user
specified option.
* `image_tensor`: Accepts a uint8 4-D tensor of shape [None, None, None, 3]
* `encoded_image_string_tensor`: Accepts a 1-D string tensor of shape [None]
containing encoded PNG or JPEG images. Image resolutions are expected to be
the same if more than 1 image is provided.
* `tf_example`: Accepts a 1-D string tensor of shape [None] containing
serialized TFExample protos. Image resolutions are expected to be the same
if more than 1 image is provided.
and the following output nodes returned by the model.postprocess(..):
* `num_detections`: Outputs float32 tensors of the form [batch]
that specifies the number of valid boxes per image in the batch.
* `detection_boxes`: Outputs float32 tensors of the form
[batch, num_boxes, 4] containing detected boxes.
* `detection_scores`: Outputs float32 tensors of the form
[batch, num_boxes] containing class scores for the detections.
* `detection_classes`: Outputs float32 tensors of the form
[batch, num_boxes] containing classes for the detections.
* `detection_masks`: Outputs float32 tensors of the form
[batch, num_boxes, mask_height, mask_width] containing predicted instance
masks for each box if its present in the dictionary of postprocessed
tensors returned by the model.
Notes:
* This tool uses `use_moving_averages` from eval_config to decide which
weights to freeze.
Example Usage:
--------------
python export_inference_graph \
--input_type image_tensor \
--pipeline_config_path path/to/ssd_inception_v2.config \
--trained_checkpoint_prefix path/to/model.ckpt \
--output_directory path/to/exported_model_directory
The expected output would be in the directory
path/to/exported_model_directory (which is created if it does not exist)
with contents:
- graph.pbtxt
- model.ckpt.data-00000-of-00001
- model.ckpt.info
- model.ckpt.meta
- frozen_inference_graph.pb
+ saved_model (a directory)
Config overrides (see the `config_override` flag) are text protobufs
(also of type pipeline_pb2.TrainEvalPipelineConfig) which are used to override
certain fields in the provided pipeline_config_path. These are useful for
making small changes to the inference graph that differ from the training or
eval config.
Example Usage (in which we change the second stage post-processing score
threshold to be 0.5):
python export_inference_graph \
--input_type image_tensor \
--pipeline_config_path path/to/ssd_inception_v2.config \
--trained_checkpoint_prefix path/to/model.ckpt \
--output_directory path/to/exported_model_directory \
--config_override " \
model{ \
faster_rcnn { \
second_stage_post_processing { \
batch_non_max_suppression { \
score_threshold: 0.5 \
} \
} \
} \
}"
"""
import tensorflow as tf
from google.protobuf import text_format
from research.object_detection import exporter
from research.object_detection.protos import pipeline_pb2
slim = tf.contrib.slim
flags = tf.app.flags
flags.DEFINE_string('input_type', 'image_tensor', 'Type of input node. Can be '
'one of [`image_tensor`, `encoded_image_string_tensor`, '
'`tf_example`]')
flags.DEFINE_string('input_shape', None,
'If input_type is `image_tensor`, this can explicitly set '
'the shape of this input tensor to a fixed size. The '
'dimensions are to be provided as a comma-separated list '
'of integers. A value of -1 can be used for unknown '
'dimensions. If not specified, for an `image_tensor, the '
'default shape will be partially specified as '
'`[None, None, None, 3]`.')
flags.DEFINE_string('pipeline_config_path', r'E:\code\112\models\dataset\data\ssd_mobilenet_v2_coco_self.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file.')
flags.DEFINE_string('trained_checkpoint_prefix', r'E:\code\112\models\dataset\training\model.ckpt-1500',
'Path to trained checkpoint, typically of the form '
'path/to/model.ckpt')
flags.DEFINE_string('output_directory', r'E:\code\112\models\dataset\data\frozen_inference_graph.pb', 'Path to write outputs.')
flags.DEFINE_string('config_override', '',
'pipeline_pb2.TrainEvalPipelineConfig '
'text proto to override pipeline_config_path.')
tf.app.flags.mark_flag_as_required('pipeline_config_path')
tf.app.flags.mark_flag_as_required('trained_checkpoint_prefix')
tf.app.flags.mark_flag_as_required('output_directory')
FLAGS = flags.FLAGS
def main(_):
pipeline_config = pipeline_pb2.TrainEvalPipelineConfig()
with tf.gfile.GFile(FLAGS.pipeline_config_path, 'r') as f:
text_format.Merge(f.read(), pipeline_config)
text_format.Merge(FLAGS.config_override, pipeline_config)
if FLAGS.input_shape:
input_shape = [
int(dim) if dim != '-1' else None
for dim in FLAGS.input_shape.split(',')
]
else:
input_shape = None
exporter.export_inference_graph(FLAGS.input_type, pipeline_config,
FLAGS.trained_checkpoint_prefix,
FLAGS.output_directory, input_shape)
if __name__ == '__main__':
tf.app.run()
flags.DEFINE_string('input_type', 'image_tensor', 'Type of input node. Can be '
'one of [`image_tensor`, `encoded_image_string_tensor`, '
'`tf_example`]')
flags.DEFINE_string('input_shape', None,
'If input_type is `image_tensor`, this can explicitly set '
'the shape of this input tensor to a fixed size. The '
'dimensions are to be provided as a comma-separated list '
'of integers. A value of -1 can be used for unknown '
'dimensions. If not specified, for an `image_tensor, the '
'default shape will be partially specified as '
'`[None, None, None, 3]`.')
flags.DEFINE_string('pipeline_config_path', r'E:\code\112\models\dataset\data\ssd_mobilenet_v2_coco_self.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file.')
flags.DEFINE_string('trained_checkpoint_prefix', r'E:\code\112\models\dataset\training\model.ckpt-1500',
'Path to trained checkpoint, typically of the form '
'path/to/model.ckpt')
flags.DEFINE_string('output_directory', r'E:\code\112\models\dataset\data\frozen_inference_graph.pb', 'Path to write outputs.')
flags.DEFINE_string('config_override', '',
'pipeline_pb2.TrainEvalPipelineConfig '
'text proto to override pipeline_config_path.')
tf.app.flags.mark_flag_as_required('pipeline_config_path')
tf.app.flags.mark_flag_as_required('trained_checkpoint_prefix')
tf.app.flags.mark_flag_as_required('output_directory')
FLAGS = flags.FLAGS
def main(_):
pipeline_config = pipeline_pb2.TrainEvalPipelineConfig()
with tf.gfile.GFile(FLAGS.pipeline_config_path, 'r') as f:
text_format.Merge(f.read(), pipeline_config)
text_format.Merge(FLAGS.config_override, pipeline_config)
if FLAGS.input_shape:
input_shape = [
int(dim) if dim != '-1' else None
for dim in FLAGS.input_shape.split(',')
]
else:
input_shape = None
exporter.export_inference_graph(FLAGS.input_type, pipeline_config,
FLAGS.trained_checkpoint_prefix,
FLAGS.output_directory, input_shape)
if __name__ == '__main__':
tf.app.run()
需要对以下标记为红色的地方做一些修改:
input_ypye : image_tensor
flags.DEFINE_string('input_type', 'image_tensor', 'Type of input node. Can be '
'one of [`image_tensor`, `encoded_image_string_tensor`, '
'`tf_example`]')'input_type', 'image_tensor', 'Type of input node. Can be '
'one of [`image_tensor`, `encoded_image_string_tensor`, '
'`tf_example`]')pipeline_config_path: models\dataset\data\ssd_inception_v2_pets.config # 上面配置的管道文件的路径
flags.DEFINE_string('pipeline_config_path', r'E:\code\112\models\dataset\data\ssd_inception_v2_pets.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file.')'pipeline_config_path', r'E:\code\112\models\dataset\data\ssd_inception_v2_pets.config',
'Path to a pipeline_pb2.TrainEvalPipelineConfig config '
'file.')trained_checkpoint_prefix: training 文件夹中生成的模型文件。
flags.DEFINE_string('trained_checkpoint_prefix', r'E:\code\112\models\dataset\training\model.ckpt-1500',
'Path to trained checkpoint, typically of the form '
'path/to/model.ckpt')trained_checkpoint_prefix', r'E:\code\112\models\dataset\training\model.ckpt-1500',
'Path to trained checkpoint, typically of the form '
'path/to/model.ckpt')output_directory: 生成pb文件的存放路径
flags.DEFINE_string('output_directory', r'E:\code\112\models\dataset\data\frozen_inference_graph.pb', 'Path to write outputs.')y', r'E:\code\112\models\dataset\data\frozen_inference_graph.pb', 'Path to write outputs.')接下来运行export_inference_graph.py文件:
最后可以训练的模型进行测试了:
将上一片中配置完object detection API 的测试文件object_detection_tutorial.py复制到dataset文件夹下,并在dataset文件夹新建tesi_image文件夹, 用于存放测试图片,并且对object_detection_tutorial.py文件完整代码:
import numpy as np
import os
import six.moves.urllib as urllib
import sys
import tarfile
import tensorflow as tf
import zipfile
from collections import defaultdict
from io import StringIO
from matplotlib import pyplot as plt
from PIL import Image
# # This is needed to display the images.
# %matplotlib inline
# This is needed since the notebook is stored in the object_detection folder.
sys.path.append("..")
# from utils import label_map_util
# from utils import visualization_utils as vis_util
from research.object_detection.utils import label_map_util
from research.object_detection.utils import visualization_utils as vis_util
# What model to download.
# MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017' # 这部分为下载模型的,现在我们不用再下载模型了,所以注释掉
# MODEL_FILE = MODEL_NAME + '.tar.gz'
# DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = r'E:\code\112\models\dataset\data\frozen_inference_graph.pb\frozen_inference_graph.pb' #上一步生成的.pb文件的路径
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = r'E:\code\112\models\dataset\data\label_map.pbtxt' #添加pbtxt文件的路径
NUM_CLASSES = 1 #我的类别数为1, 这里根据自己的类别数修改
# download model # 这部分也是下载模型的,注释掉即可
# opener = urllib.request.URLopener()
# 下载模型,如果已经下载好了下面这句代码可以注释掉
# opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
# tar_file = tarfile.open(MODEL_FILE)
# for file in tar_file.getmembers():
# file_name = os.path.basename(file.name)
# if 'frozen_inference_graph.pb' in file_name:
# tar_file.extract(file, os.getcwd())
# Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES,
use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images: # 这里说明测试图片的命名规则为imagen.jpg, 遵守规则即可
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = r'E:\code\112\models\dataset\tesi_images' # 存放测试图片的路径
TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 22)] # 修改测试图片的张数range(1, n + 1), 为测试图片的张数
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()
# MODEL_NAME = 'ssd_mobilenet_v1_coco_11_06_2017' # 这部分为下载模型的,现在我们不用再下载模型了,所以注释掉
# MODEL_FILE = MODEL_NAME + '.tar.gz'
# DOWNLOAD_BASE = 'http://download.tensorflow.org/models/object_detection/'
# Path to frozen detection graph. This is the actual model that is used for the object detection.
PATH_TO_CKPT = r'E:\code\112\models\dataset\data\frozen_inference_graph.pb\frozen_inference_graph.pb' #上一步生成的.pb文件的路径
# List of the strings that is used to add correct label for each box.
PATH_TO_LABELS = r'E:\code\112\models\dataset\data\label_map.pbtxt' #添加pbtxt文件的路径
NUM_CLASSES = 1 #我的类别数为1, 这里根据自己的类别数修改
# download model # 这部分也是下载模型的,注释掉即可
# opener = urllib.request.URLopener()
# 下载模型,如果已经下载好了下面这句代码可以注释掉
# opener.retrieve(DOWNLOAD_BASE + MODEL_FILE, MODEL_FILE)
# tar_file = tarfile.open(MODEL_FILE)
# for file in tar_file.getmembers():
# file_name = os.path.basename(file.name)
# if 'frozen_inference_graph.pb' in file_name:
# tar_file.extract(file, os.getcwd())
# Load a (frozen) Tensorflow model into memory.
detection_graph = tf.Graph()
with detection_graph.as_default():
od_graph_def = tf.GraphDef()
with tf.gfile.GFile(PATH_TO_CKPT, 'rb') as fid:
serialized_graph = fid.read()
od_graph_def.ParseFromString(serialized_graph)
tf.import_graph_def(od_graph_def, name='')
# Loading label map
label_map = label_map_util.load_labelmap(PATH_TO_LABELS)
categories = label_map_util.convert_label_map_to_categories(label_map, max_num_classes=NUM_CLASSES,
use_display_name=True)
category_index = label_map_util.create_category_index(categories)
# Helper code
def load_image_into_numpy_array(image):
(im_width, im_height) = image.size
return np.array(image.getdata()).reshape(
(im_height, im_width, 3)).astype(np.uint8)
# For the sake of simplicity we will use only 2 images: # 这里说明测试图片的命名规则为imagen.jpg, 遵守规则即可
# image1.jpg
# image2.jpg
# If you want to test the code with your images, just add path to the images to the TEST_IMAGE_PATHS.
PATH_TO_TEST_IMAGES_DIR = r'E:\code\112\models\dataset\tesi_images' # 存放测试图片的路径
TEST_IMAGE_PATHS = [os.path.join(PATH_TO_TEST_IMAGES_DIR, 'image{}.jpg'.format(i)) for i in range(1, 22)] # 修改测试图片的张数range(1, n + 1), 为测试图片的张数
# Size, in inches, of the output images.
IMAGE_SIZE = (12, 8)
with detection_graph.as_default():
with tf.Session(graph=detection_graph) as sess:
# Definite input and output Tensors for detection_graph
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
detection_boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
detection_scores = detection_graph.get_tensor_by_name('detection_scores:0')
detection_classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
for image_path in TEST_IMAGE_PATHS:
image = Image.open(image_path)
# the array based representation of the image will be used later in order to prepare the
# result image with boxes and labels on it.
image_np = load_image_into_numpy_array(image)
# Expand dimensions since the model expects images to have shape: [1, None, None, 3]
image_np_expanded = np.expand_dims(image_np, axis=0)
image_tensor = detection_graph.get_tensor_by_name('image_tensor:0')
# Each box represents a part of the image where a particular object was detected.
boxes = detection_graph.get_tensor_by_name('detection_boxes:0')
# Each score represent how level of confidence for each of the objects.
# Score is shown on the result image, together with the class label.
scores = detection_graph.get_tensor_by_name('detection_scores:0')
classes = detection_graph.get_tensor_by_name('detection_classes:0')
num_detections = detection_graph.get_tensor_by_name('num_detections:0')
# Actual detection.
(boxes, scores, classes, num_detections) = sess.run(
[boxes, scores, classes, num_detections],
feed_dict={image_tensor: image_np_expanded})
# Visualization of the results of a detection.
vis_util.visualize_boxes_and_labels_on_image_array(
image_np,
np.squeeze(boxes),
np.squeeze(classes).astype(np.int32),
np.squeeze(scores),
category_index,
use_normalized_coordinates=True,
line_thickness=8)
plt.figure(figsize=IMAGE_SIZE)
plt.imshow(image_np)
plt.show()
对以上标记为红色代码的部分进行修改即可:运行object_detection_tutorial.py文件,我的测试结果:(贴几张图)
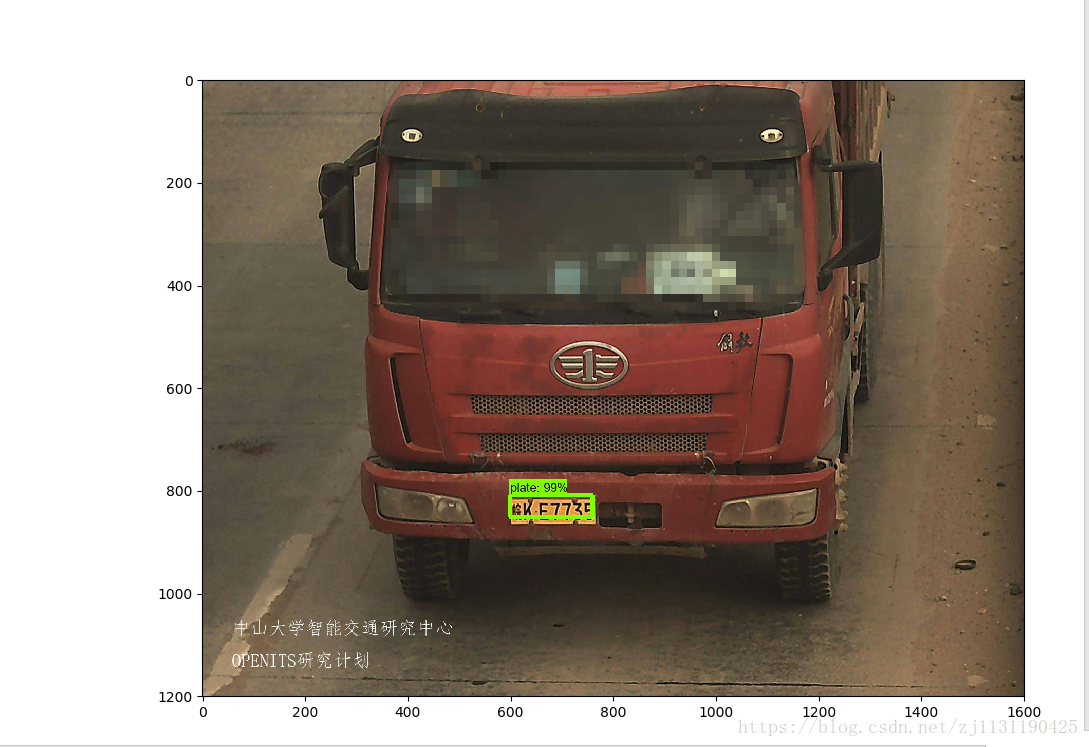
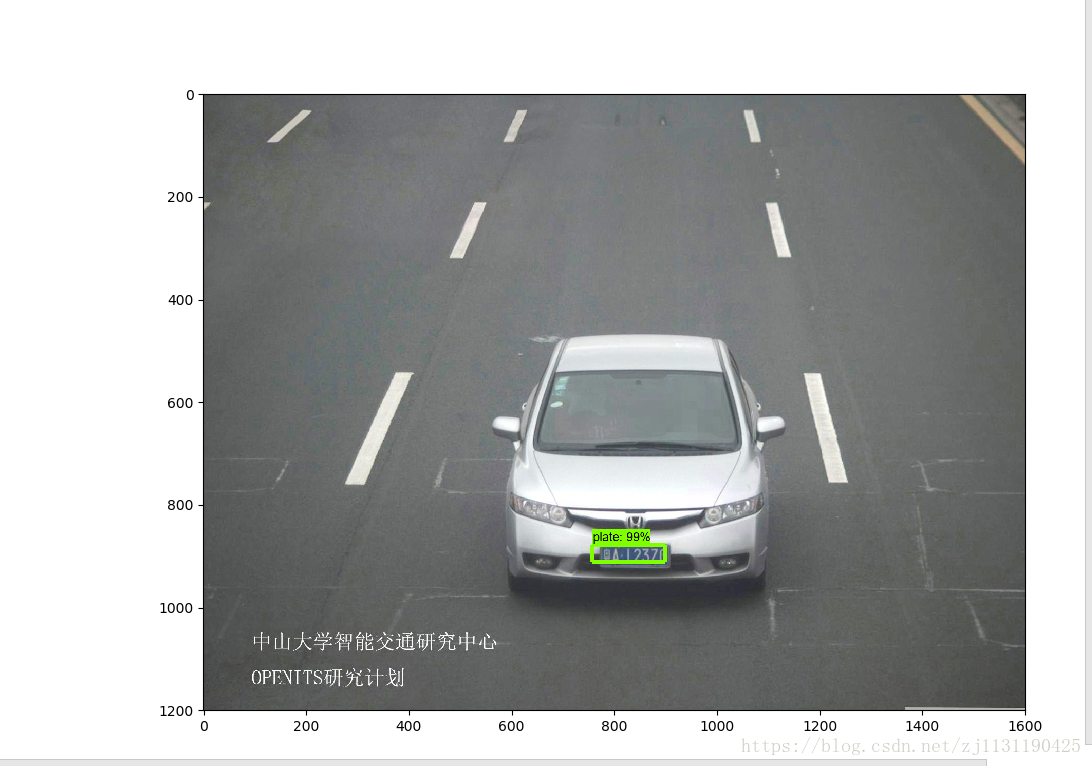
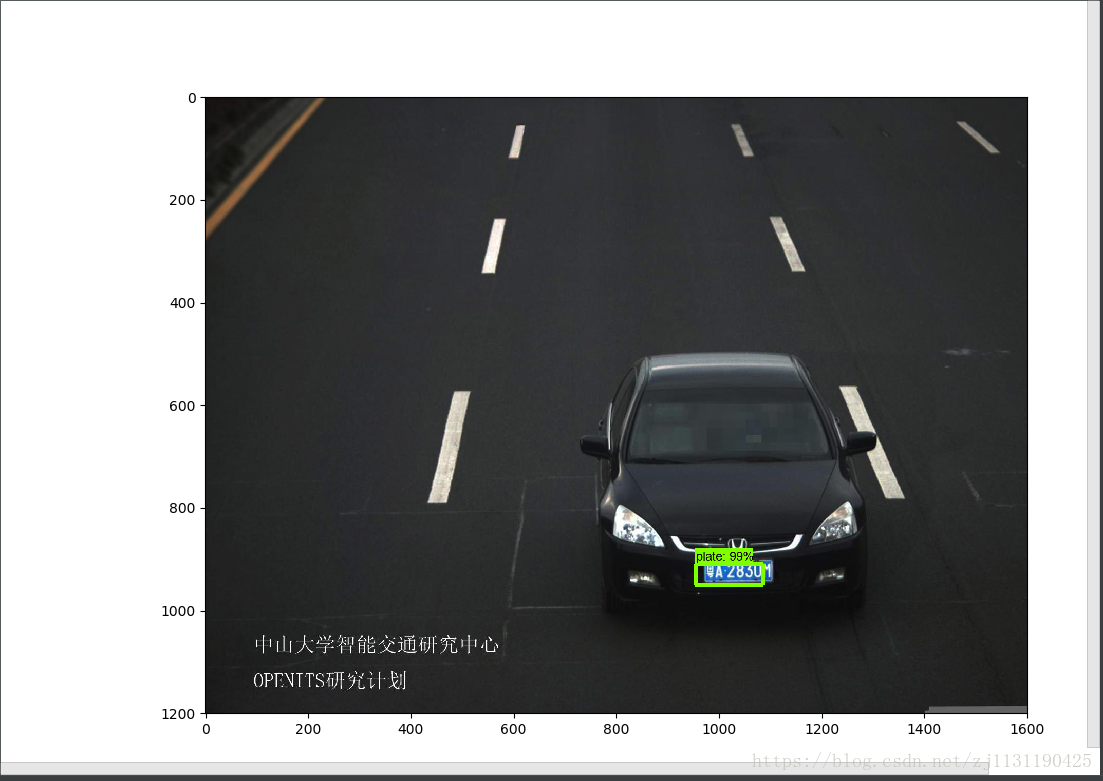
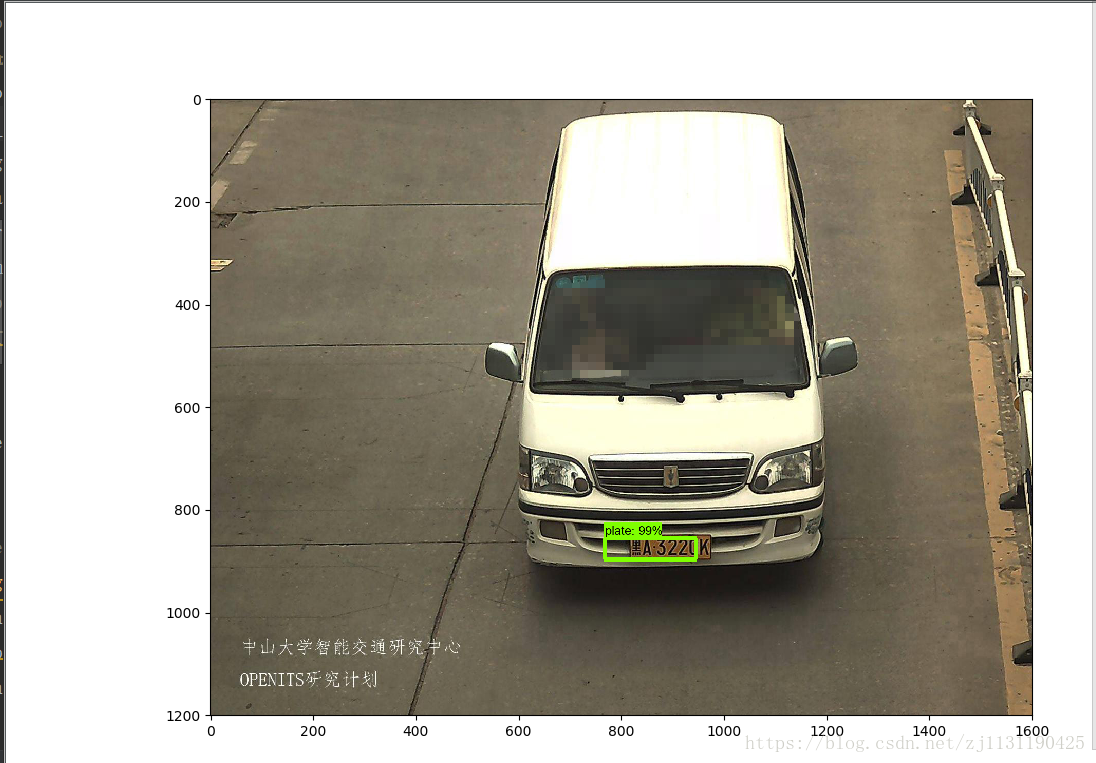
效果还是可以的,关于使用tensorflow object detection API 训练自己的目标检测模型 先介绍到这里
附上完整的项目目录: