基于对比学习的目标检测预训练方法
本文主要记录以下几片论文:
1、DenseCL(CVPR21 oral)
2、DetCo(ICCV21)
3、InstanceLoc(CVPR21)
4、self-EMD
核心就是:patch的切分策略(更好的学习局部信息)、正负样本对的匹配(更高质量的对比pair)
1、(DenseCL) Dense Contrastive Learning for Self-Supervised Visual Pre-Training (CVPR 21 oral)
代码链接
论文链接

local对比损失:
同一张图进行数据增强后得到M1和M2,经过backbone之后得到F1和F2,经过空间分块得到7*7=49,每一个分块经过dense projection head(MLP)后分别得到R(49个特征表示)、T(49个特征表示)。然后对2个矩阵进行cosine距离相似度计算,为每个ri选择最相似的tj(选择最优的positive),进行对比学习。
最终结合global+local对比损失进行训练。

可见,在目标检测任务中,DenseCL比MoCov2预训练更优,比有监督训练更优。
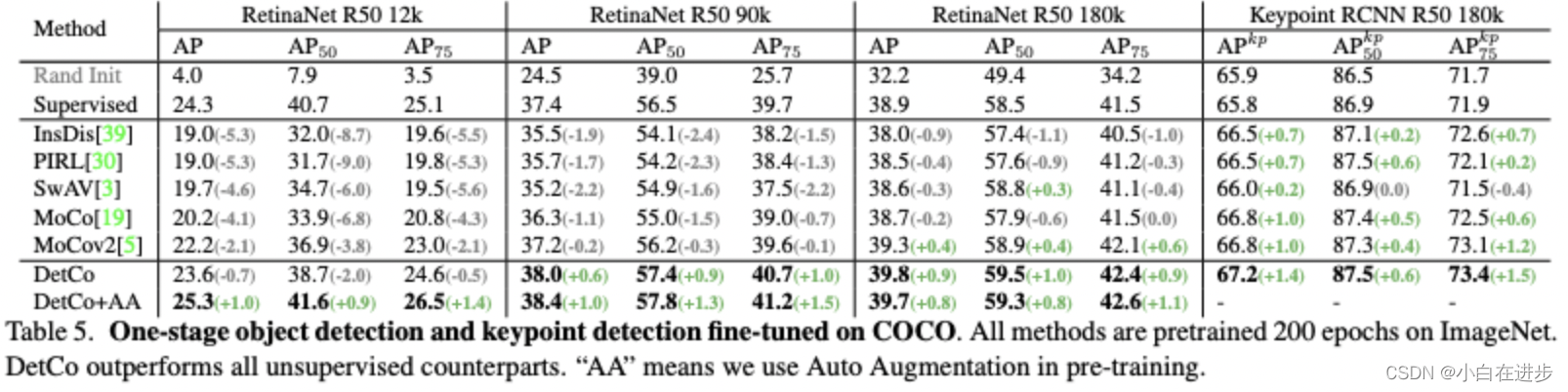
2、DetCO (ICCV 21)

与Dense CL的最大不同是,上文是将不同的patch根据相似矩阵进行最优positive选择,本文是直接将patch进行concatenate进行对比学习
提出3原则:1)基于对比学习比监督/聚类好。2)同时保持低层+高层特征有利于检测。3)local特征很重要。
提出的方法:
1)低层+高层特征结合:从res50的stage2、3、4、5获取4个层级的特征,分别通过MLP后获取4组k、q,Loss(G-G)是这4组kq之间的信息交互.
2)local feature:从原图中选取9个patch,不同的排列形成2张图M1、M2,9个patch通过encoder+MLP得到9个patch的局部特征表示,将其concatenate后,计算Loss(L-L).
3)global+local:将global的特征表示,与concate后的local表示,也进行对比学习。
疑问:
1)如何选取9个patch,是不是重新排列?
2)9个patch的特征,跟全图的特征要一样?为什么?
3、InstanceLoc (CVPR 21)


具体做法:
1)同一张图像的2个random crop(构成正样本对)paste到不同的背景图像上,RoIAlign根据边界框位置提取RoI特征进行对比学习。(引导表示在空间上忽略背景并获得定位能力)
2)边界框增强:随机选择1个与边界框的IOU<0.5的anchor,其region对应的feature就是负样本。
4、self-EMD
可以直接采用COCO进行训练,不用在imagenet上预训练。


动机:
1)现有自监督训练的先验条件是different views/crops of the same image correspond to the same object ,不然随机crop的图就会导致语义上noise。imagente这样的object-centric可以满足,但coco这种多目标的就无法满足。(使用EMD进行最佳patch匹配)
2)全局pooling破坏了空间结构信息且丢失了局部信息,影响定位精度。(不实用MLP,使用卷积神经网络)
做法:随机crop后,使用SPP crop获取不同范围的patch feature,并使用EMD来计算不同patch之间的相似性(代替L2)
EMD 堆土距离(从一个土堆转换成另一个土堆的最小工作量)
