文章目录
本文的样本图像、标注文件及训练结果的ckpt已上传至 https://download.csdn.net/download/botao_li/10860369
1. 功能描述
用TensorFlow实现视频内的目标检测,识别并且标示位置:
- 用OpenCV从视频中取出视频帧图像(后续用LabelImg进行手动标注)
- 将标注数据转化成TFRecord格式
- TensorFlow建立深度网络使用TFRecord数据进行训练
2. 总体设计
硬件环境(小米游戏本):
- Intel Core i7-8750H CPU
- 16 GB RAM
- NVidia GeForce GTX 1060 6GB
软件环境:
- Windows 10
- Visual Studio 2015 update 3
- CUDA 9.0
- Python 3.6
- PyCharm Community 2018.3
- TensorFlow-GPU 1.11
- OpenCV-Python 3.4.3
- LabelImg 1.8.1
- Pandas 0.23.4
- Qt 5.12.0
使用PyCharm进行开发,使用TensorFlow的GPU版本加速训练。
所有功能都做类封装,前3项功能使用Python语言。
在Python的类定义文件中加入判断是否为当前运行文件的判断,即在类定义文件中执行功能:
if __name__ == "__main__":
3. 视频图像截取设计
__init__()函数指定视频文件,并且打开VideoCapture__del__()函数释放VideoCapture- 调用
gen()函数生成帧图像文件,参数包括抓取帧数目和目标文件夹,以及输出图像宽高 gen()函数中生成图像文件命名顺序编号,但是在视频中随机取帧,保证后续处理各文件时,减少相邻图像间的关联程度
import cv2 # 导入OpenCV
import os # 用于文件夹操作
import random # 用于生成随机数
class VideoFramer:
"""
从视频中随机取出图像帧
建立对象时指定视频源文件
在生成图像文件时指定目标文件夹及生成图像数目
注意在生成图像文件时采用顺序命名,但是随机位置取帧,在顺序处理文件时减少图像间关联
"""
def __init__(self, file_path, init_cnt):
"""
:param file_path: 视频文件路径
:param init_cnt: 输出文件起始计数值
"""
# 判断文件路径参数
if type(file_path) != str:
print("VideoFramer对象无法识别")
self.ready = False
return
# 打开抓取对象
self.cap = cv2.VideoCapture(file_path)
if self.cap.isOpened(): # 打开成功
# 成员变量赋值
self.src = file_path
self.len = self.cap.get(cv2.CAP_PROP_FRAME_COUNT)
self.ready = True
self.cnt = init_cnt
else:
print("打开视频文件失败")
self.ready = False
def __del__(self):
# 如果抓取对象已打开,则释放
if self.cap.isOpened():
self.cap.release()
# 随机抓取图像
def gen(self, num, dst_folder=None, width=480, height=270):
"""
:param num: 抓取的视频帧的数目
:param dst_folder: 保存图像路径
:param width: 保存图像宽度
:param height: 保存图像高度
:return: True表示抓取成功,False表示失败
"""
# 如果功能未就绪,返回失败
if not self.ready:
return False
# num参数类型必须为整数
if type(num) != int:
print("抓取图像数目非整数")
return False
# num参数必须非0
if num < 1:
print("抓取图像数目小于1")
return False
# 如果未指定目标路径,则使用当前工作目录
if dst_folder is None:
dst_folder = os.getcwd()
# 判断目标路径
if type(dst_folder) != str:
print("无法取得目标路径")
return False
# 检查目标文件夹是否存在,不存在则建立文件夹
if not(os.path.exists(dst_folder) and os.path.isdir(dst_folder)):
# 建立文件夹
os.makedirs(dst_folder)
# 建立文件夹失败
if not os.path.exists(dst_folder):
print("建立目标文件夹失败")
return False
# 随机抓取图像帧
for i in range(num): # i取值0~(num-1)
# 取得0~(len-1)范围内的随机数作为当前取帧位置
pos = int(random.uniform(0, self.len-1))
# 设置抓取对象的帧位置
self.cap.set(cv2.CAP_PROP_POS_FRAMES, pos)
# 抓取
ret, frame = self.cap.read()
if ret: # 抓取成功,保存图像
# 改变输出图像尺寸
frame = cv2.resize(frame, dsize=(width, height))
# 保存图像文件
ret = cv2.imwrite(os.path.join(dst_folder, "cap_{0:d}.jpg".format(self.cnt)), frame)
if not ret: # 保存失败
print(os.path.join(dst_folder, "cap_{0:d}.jpg".format(self.cnt)), "保存失败")
return False
else:
# 已保存帧计数增1
self.cnt += 1
# 显示已生成图像文件数据,每100帧显示进度
if self.cnt % 100 == 0:
print("已生成图像文件数目:{0}".format(self.cnt))
else:
print("抓取帧{0}失败".format(pos))
return False
# 完成
print("在文件夹{0}内生成帧图像文件{1}".format(dst_folder, num))
return True
# 如果当前类定义文件用于执行,则执行以下代码
if __name__ == "__main__":
src = "d:/temp/xml2tfrecord/vid_train.mp4"
# 建立抓取对象
vf = VideoFramer(src, 10002)
if not vf.ready:
print("视频文件{0}打开失败".format(src))
else:
print("视频文件{0}打开成功".format(vf.src))
print("视频总帧数{0}".format(vf.len))
# 抓取图像文件
vf.gen(1, "d:/temp/xml2tfrecord/images", 480, 270)
# 清理抓取对象
del vf
4. 图像样本转化为TFRecord
4.1. 图像数据处理
4.1.1. 用OpenCV读取图像数据
用OpenCV读取图像数据的格式为numpy.ndarray
import cv2
# 读取分辩率为1920*1080的3通道图像文件
img = cv2.imread("d:/temp/test_folder/image2.jpg", cv2.IMREAD_COLOR) # cv2.IMREAD_COLOR值为1
print(img.shape) # 输出: (1080, 1920, 3)
print(type(img)) # 输出: <class 'numpy.ndarray'>
print(img.dtype) # 输出: uint8
# 修改宽高
img = cv2.resize(img, (480, 270)) # 注意dsize参数的元组按目标宽高排列
# 将BGR格式转为TensorFlow常用的RGB格式
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 显示图像
cv2.imshow("bgr", img)
cv2.imshow("rgb", img_rgb)
cv2.waitKey(0)
上述代码显示图像如下:


4.1.2. 用TensorFlow读取图像数据
用TensorFlow读入图像文件的类型为bytes,即string类型
解析图像文件必须用Session运行tensor才能执行,而且必须注意float类型的归一化及其与uint8的转换
import cv2
import tensorflow as tf
# 读取分辩率为1920*1080的3通道图像文件
with tf.gfile.FastGFile("d:/temp/test_folder/image2.jpg", "rb") as fid:
img = fid.read()
print(type(img)) # 输出: <class 'bytes'>
# 建立解析jpg图像为原始数据的tensor
img_tensor = tf.image.decode_jpeg(img)
print(type(img_tensor)) # 输出: <class 'tensorflow.python.framework.ops.Tensor'>
print(img_tensor.shape) # 输出: (?, ?, ?)
print(img_tensor.dtype) # 输出: <dtype: 'uint8'>
# 指定tensor的shape
# 无论是否设置shape,decode_jpeg都能正确解析图像
img_tensor.set_shape([1080, 1920, 3])
print(img_tensor.shape) # 输出: (1080, 1920, 3)
# 修改宽高
# 特别注意resize_images输出类型为float32,即将uint8转化为float32类型
# resize_images即可以操作图像batch的4D数据,也可以转化单幅图像的3D数据
img_resize_float = tf.image.resize_images(img_tensor, size=(270, 480))
print(type(img_resize_float)) # 输出: <class 'tensorflow.python.framework.ops.Tensor'>
print(img_resize_float.shape) # 输出: (270, 480, 3),如果img_tensor未指定shape,则输出为(270, 480, ?)
print(img_resize_float.dtype) # 输出: <dtype: 'float32'>
# 转换类型为uint8
# 特别注意convert_image_dtype中float32类型的图像都必须归一化至0~1范围
# img_resize_float/255用于归一化至0~1的范围
img_resize_uint = tf.image.convert_image_dtype(img_resize_float/255, dtype=tf.uint8, saturate=True)
# 用Session完成tensor的计算
with tf.Session() as sess:
img_rgb_float = sess.run(img_resize_float)
print(type(img_rgb_float)) # 输出: <class 'numpy.ndarray'>
print(img_rgb_float.shape) # 输出: (270, 480, 3)
print(img_rgb_float.dtype) # 输出: float32
img_rgb = sess.run(img_resize_uint)
print(type(img_rgb)) # 输出: <class 'numpy.ndarray'>
print(img_rgb.shape) # 输出: (270, 480, 3)
print(img_rgb.dtype) # 输出: uint8
# 用OpenCV显示生成的图像
img_bgr = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2BGR)
cv2.imshow("float rgb", img_rgb_float/255) # imshow显示float类型图像,必须归一化至0~1范围
cv2.imshow("bgr", img_bgr)
cv2.imshow("rgb", img_rgb)
cv2.waitKey(0)
上述代码是显示图像如下:



4.2. TFRecord文件的数据读写方法
4.2.1. TFRecord的写入
import tensorflow as tf
"""
TFRecord的写入主要在于以下各类
tf.python_io.TFRecordWriter: tf.python_io.TFRecordWriter.write()执行写操作
tf.train.Example: tf.train.Example.SerializeToString()生成写操作对象
tf.train.Features: 包含tf.train.Feature
tf.train.Feature: 建立tf.train.Example使用的feature
tf.train.BytesList: 建立字符串列表的feature
tf.train.FloatList: 建立浮点数列表的feature
tf.train.Int64List: 建立整型数列表的feature
"""
# tf.train.Feature支持的3种list类型
# 字符串、浮点数、int64整型数
data_bytes = b"\x11\x22\x33\x44" # b'\x11"3D'
data_float = 3.2
data_int64 = 0
# 建立5个TFRecord文件保存数据
for i in range(5):
filename = "d:/temp/test_folder/rec{0}.tfrecords".format(i)
with tf.python_io.TFRecordWriter(filename) as writer: # 用with而不是调用writer.close()
example = tf.train.Example(features=tf.train.Features(
feature={
# feature参数输入为字典,key为字符串,值为tf.train.Feature对象
# tf.train.Feature三种list分别传入不同类型的list
# bytes_list=tf.train.BytesList(value=字符串列表)
# float_list=tf.train.FloatList(value=浮点数列表)
# int64_list=tf.train.Int64List(value=int64整型数列表)
"bytes": tf.train.Feature(bytes_list=tf.train.BytesList(value=[data_bytes])),
"float": tf.train.Feature(float_list=tf.train.FloatList(value=[float(i)])),
"int64": tf.train.Feature(int64_list=tf.train.Int64List(value=[i]))
}
))
writer.write(example.SerializeToString())
4.2.2. TFRecord的读出
import tensorflow as tf
"""
TFRecord的写入主要在于以下:
tf.train.match_filenames_once: 用于查找TFRecord文件
tf.train.string_input_producer: 用于从文件列表中取出单个文件名
tf.TFRecordReader: tf.TFRecordReader.read()读出TFRecord文件中的数据
tf.parse_single_example: 将TFRecord文件中的数据解析为字典
tf.FixedLenFeature: 用于取出TFRecord中的feature
tf.train.Coordinator: 操作线程的关闭
tf.train.start_queue_runners: 启动tf.train.string_input_producer返回的queue的输出,开启工作
"""
# 获取文件列表
files = tf.train.match_filenames_once("d:/temp/test_folder/rec*.tfrecords")
# 创建输入队列
# 重复输出输入文件列表中的所有文件名,除非用参数num_epochs指定每个文件可轮询的次数
# shuffle参数用于控制随机打乱文件排序
# 返回值说明:
# A queue with the output strings. A QueueRunner for the Queue is added to the current Graph's QUEUE_RUNNER collection.
# 用tf.train.start_queue_runners启动queue的输出
queue = tf.train.string_input_producer(files, shuffle=False)
# 如果只有单个文件,则使用单个文件名构成列表,注意[]
# queue = tf.train.string_input_producer(["d:/temp/test_folder/rec0.tfrecords"], shuffle=False)
# 建立TFRecordReader并解析TFRecord文件
reader = tf.TFRecordReader()
_, serialized_example = reader.read(queue) # tf.TFRecordReader.read()用于读取queue中的下一个文件
rec_features = tf.parse_single_example( # 返回字典,字典key值即features参数中的key值
serialized_example,
features={
"bytes": tf.FixedLenFeature(shape=[], dtype=tf.string),
"float": tf.FixedLenFeature(shape=[], dtype=tf.float32),
"int64": tf.FixedLenFeature(shape=[], dtype=tf.int64)
}
)
"""
tensor字典
{'bytes': <tf.Tensor 'ParseSingleExample/ParseSingleExample:0' shape=() dtype=string>,
'float': <tf.Tensor 'ParseSingleExample/ParseSingleExample:1' shape=() dtype=float32>,
'int64': <tf.Tensor 'ParseSingleExample/ParseSingleExample:2' shape=() dtype=int64>}
"""
print(rec_features)
with tf.Session() as sess:
"""
sess.run(tf.global_variables_initializer())
print(sess.run(files))
上述代码运行出错,提示如下:
Attempting to use uninitialized value matching_filenames
因为tf.train.match_filenames_once使用的是局部变量,非全局变量
需要改成下方代码才能正确运行
"""
sess.run(tf.local_variables_initializer())
print(sess.run(files)) # 打印文件列表
# 用子线程启动tf.train.string_input_producer生成的queue
coord = tf.train.Coordinator() # 用于控制线程结束
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 读出TFRecord文件内容
for i in range(10):
# 每次run都由string_input_producer更新至下一个TFRecord文件
print(sess.run(rec_features["int64"]))
print(sess.run(rec_features))
coord.request_stop() # 结束线程
coord.join(threads) # 等待线程结束
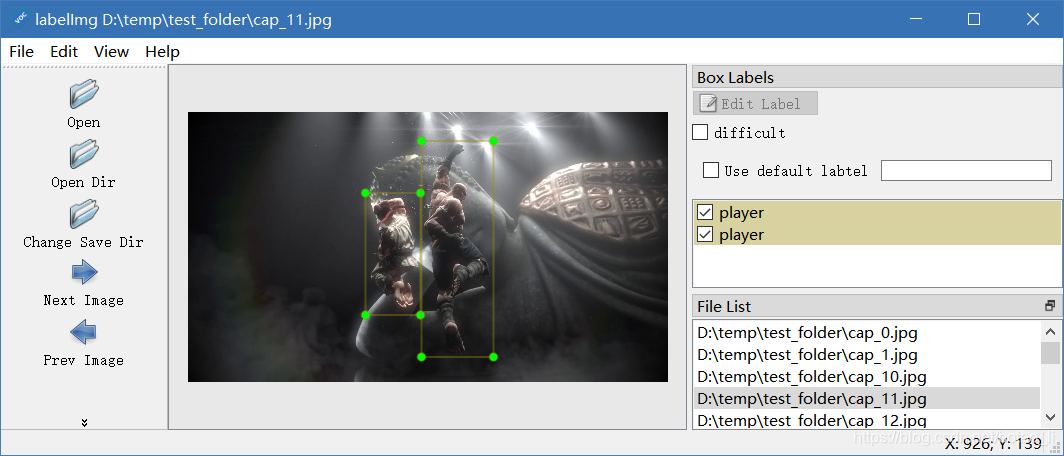
4.3. LabelImg标注文件的格式与解析
主要参考:https://www.jianshu.com/p/86894ccaa407
LabelImg为每个标识的图像文件建立一个对应的xml标注文件,一般情况下默认的标注文件名与图像文件名一致。
典型的标注文件内容如下:
<annotation>
<folder>test_folder</folder>
<filename>cap_11.jpg</filename>
<path>D:\temp\test_folder\cap_11.jpg</path>
<source>
<database>Unknown</database>
</source>
<size>
<width>480</width>
<height>270</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>player</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>178</xmin>
<ymin>81</ymin>
<xmax>233</xmax>
<ymax>203</ymax>
</bndbox>
</object>
<object>
<name>player</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>234</xmin>
<ymin>29</ymin>
<xmax>306</xmax>
<ymax>245</ymax>
</bndbox>
</object>
</annotation>
用以下代码读取LabelImg的标注文件信息:
import glob # 用于遍历文件夹内的xml文件
import xml.etree.ElementTree as ET # 用于解析xml文件
# 遍历文件夹内的全部xml文件,1个xml文件描述1个图像文件的标注信息
for f in glob.glob("d:/temp/test_folder/*.xml"):
# 解析xml文件
try:
tree = ET.parse(f)
except FileNotFoundError:
print("无法找到xml文件: "+f)
except ET.ParseError:
print("无法解析xml文件: "+f)
else: # ET.parse()运行正确
# 取得xml根节点
root = tree.getroot()
# 取得图像路径和文件名
print(root.find("filename").text)
print(root.find("path").text)
# 取得图像宽高
print(int(root.find("size")[0].text)) # width节点的序号为[0]
print(int(root.find("size")[1].text)) # height节点的序号为[1]
# 取得bbox
for obj in root.findall("object"): # 查找根节点下全部名为object的节点
print(int(obj[4][0].text)) # bndbox节点的序号为[4]
print(int(obj[4][1].text))
print(int(obj[4][2].text))
print(int(obj[4][3].text))
4.4. 将LabelImg的标注及对应的图像文件保存为TFRecord
import tensorflow as tf # 导入TensorFlow
import cv2 # 导入OpenCV
import os # 用于文件操作
import glob # 用于遍历文件夹内的xml文件
import xml.etree.ElementTree as ET # 用于解析xml文件
# 将LabelImg标注的图像文件和标注信息保存为TFRecord
class LabelImg2TFRecord:
@classmethod
def gen(cls, path):
"""
:param path: LabelImg标识文件的路径,及生成的TFRecord文件路径
"""
# 遍历文件夹内的全部xml文件,1个xml文件描述1个图像文件的标注信息
for f in glob.glob(path + "/*.xml"):
# 解析xml文件
try:
tree = ET.parse(f)
except FileNotFoundError:
print("无法找到xml文件: "+f)
return False
except ET.ParseError:
print("无法解析xml文件: "+f)
return False
else: # ET.parse()正确运行
# 取得xml根节点
root = tree.getroot()
# 取得图像路径和文件名
img_name = root.find("filename").text
img_path = root.find("path").text
# 取得图像宽高
img_width = int(root.find("size")[0].text)
img_height = int(root.find("size")[1].text)
# 取得所有标注object的信息
label = [] # 类别名称
xmin = []
xmax = []
ymin = []
ymax = []
# 查找根节点下全部名为object的节点
for m in root.findall("object"):
xmin.append(int(m[4][0].text))
xmax.append(int(m[4][2].text))
ymin.append(int(m[4][1].text))
ymax.append(int(m[4][3].text))
# 用encode将str类型转为bytes类型,相应的用decode由bytes转回str类型
label.append(m[0].text.encode("utf-8"))
# 至少有1个标注目标
if len(label) > 0:
# 用OpenCV读出图像原始数据,未压缩数据
data = cv2.imread(img_path, cv2.IMREAD_COLOR)
# 将OpenCV的BGR格式转为RGB格式
data = cv2.cvtColor(data, cv2.COLOR_BGR2RGB)
# 建立Example
example = tf.train.Example(features=tf.train.Features(feature={
# 用encode将str类型转为bytes类型
# 以下各feature的shape固定,读出时必须使用tf.FixedLenFeature
"filename": tf.train.Feature(bytes_list=tf.train.BytesList(value=[img_name.encode("utf-8")])),
"width": tf.train.Feature(int64_list=tf.train.Int64List(value=[img_width])),
"height": tf.train.Feature(int64_list=tf.train.Int64List(value=[img_height])),
"data": tf.train.Feature(bytes_list=tf.train.BytesList(value=[data.tostring()])), # 图像数据ndarray转化成bytes类型
# 以下各feature的shape不固定,,读出时必须使用tf.VarLenFeature
"object/label": tf.train.Feature(bytes_list=tf.train.BytesList(value=label)),
"object/bbox/xmin": tf.train.Feature(int64_list=tf.train.Int64List(value=xmin)),
"object/bbox/xmax": tf.train.Feature(int64_list=tf.train.Int64List(value=xmax)),
"object/bbox/ymin": tf.train.Feature(int64_list=tf.train.Int64List(value=ymin)),
"object/bbox/ymax": tf.train.Feature(int64_list=tf.train.Int64List(value=ymax))
}))
# 建立TFRecord的写对象
# img_name.split('.')[0]用于去掉扩展名,只保留文件名
with tf.python_io.TFRecordWriter(os.path.join(path, img_name.split('.')[0]+".tfrecords")) as writer:
# 数据写入TFRecord文件
writer.write(example.SerializeToString())
# 结束
print("生成TFRecord文件: " + os.path.join(path, img_name.split('.')[0]+".tfrecords"))
else:
print("xml文件{0}无标注目标".format(f))
return False
print("完成全部xml标注文件的保存")
return True
if __name__ == "__main__":
LabelImg2TFRecord.gen("d:/temp/test_folder")
4.4.1.验证
import tensorflow as tf
import cv2
import numpy as np
# 获取文件列表
files = tf.train.match_filenames_once("d:/temp/test_folder/cap*.tfrecords")
# 创建输入队列
# 重复输出输入文件列表中的所有文件名,除非用参数num_epochs指定每个文件可轮询的次数
# shuffle参数用于控制随机打乱文件排序
# 返回值说明:
# A queue with the output strings. A QueueRunner for the Queue is added to the current Graph's QUEUE_RUNNER collection.
# 用tf.train.start_queue_runners启动queue的输出
queue = tf.train.string_input_producer(files, shuffle=True)
# 建立TFRecordReader并解析TFRecord文件
reader = tf.TFRecordReader()
_, serialized_example = reader.read(queue) # tf.TFRecordReader.read()用于读取queue中的下一个文件
rec_features = tf.parse_single_example( # 返回字典,字典key值即features参数中的key值
serialized_example,
features={
# 写入时shape固定的数值用FixedLenFeature
"filename": tf.FixedLenFeature(shape=[], dtype=tf.string), # 由于只有1个值也可以用shape[1],返回list
"width": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"height": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"data": tf.FixedLenFeature(shape=[], dtype=tf.string),
# 写入时shape不固定的数值,读出时用VarLenFeature,读出为SparseTensorValue类对象
"object/label": tf.VarLenFeature(dtype=tf.string),
"object/bbox/xmin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/xmax": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymax": tf.VarLenFeature(dtype=tf.int64),
}
)
# # 将tf.string转化成tf.uint8的tensor
# img_tensor = tf.decode_raw(rec_features["data"], tf.uint8)
# print(img_tensor.shape) # 输出: dododo
with tf.Session() as sess:
"""
sess.run(tf.global_variables_initializer())
print(sess.run(files))
上述代码运行出错,提示如下:
Attempting to use uninitialized value matching_filenames
因为tf.train.match_filenames_once使用的是局部变量,非全局变量
需要改成下方代码才能正确运行
"""
sess.run(tf.local_variables_initializer())
print(sess.run(files)) # 打印文件列表
# 用子线程启动tf.train.string_input_producer生成的queue
coord = tf.train.Coordinator() # 用于控制线程结束
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 读出TFRecord文件内容
for i in range(20):
# 每次run都由string_input_producer更新至下一个TFRecord文件
rec = sess.run(rec_features)
print(rec["filename"].decode("utf-8")) # 由bytes类型转为str类型
print("目标数目: " + str(rec["object/label"].values.size))
print(rec["object/label"].values)
print(rec["object/bbox/xmin"].values)
print(rec["object/bbox/xmax"].values)
print(rec["object/bbox/ymin"].values)
print(rec["object/bbox/ymax"].values)
# 将图像数据转化为numpy.ndarray
img = np.fromstring(rec["data"], np.uint8)
print(type(rec["data"])) # 输出: <class 'bytes'>
print(type(img)) # 输出: <class 'numpy.ndarray'>
# 根据feature设置图像shape
img = np.reshape(img, (rec["height"], rec["width"], 3))
print(img.shape) # 输出: (rec["height"], rec["width"], 3)
# 将图像由RGB转为RGB用于imshow
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
# 绘制标注框
for j in range(rec["object/label"].values.size):
img = cv2.putText(img,
rec["object/label"].values[j].decode("utf-8"),
(rec["object/bbox/xmin"].values[j], rec["object/bbox/ymin"].values[j]-2),
cv2.FONT_HERSHEY_PLAIN,
1,
(0, 255, 0)
)
img = cv2.rectangle(img,
(rec["object/bbox/xmin"].values[j], rec["object/bbox/ymin"].values[j]),
(rec["object/bbox/xmax"].values[j], rec["object/bbox/ymax"].values[j]),
(0, 0, 255))
# 显示图像
cv2.imshow(rec["filename"].decode("utf-8"), img)
cv2.waitKey()
coord.request_stop() # 结束线程
coord.join(threads) # 等待线程结束
显示图像与LabelImg比较

5. 网络训练设计
5.1. 输出设计
网络输出为[16, 3]的矩阵,shape[0]代表图像内最多可能出现的目标数目,shape[1]表示为(f, x, y)
其中f表示当前行序号有目标的概率,取值0~1,(x, y)为对应目标中心点的归一化坐标,取值范围0~1
设计损失函数如下:
上方(f’, x’, y’)即样本值,f’取值0或者1,表示当前序号位置是否有目标,(x’, y’)有如下取值规则
和
分别用于调节概率和与中心点距离的加权,如果两者加权一致,由于所有数据取值都为0~1,则有
5.2. 网络设计
网络模型为简化实现,参考LeNet-5。
输入为[16, 480, 270, 3],batch大小为16;图像宽高为配合16:9的宽高比设置为[480, 270];通道数为3,对应RGB。
| 网络层 | 输入 | 算法 | 输出 | 说明 |
|---|---|---|---|---|
| layer0_conv | [16, 480, 270, 3] | [3, 3, 3, 64], stride=1, valid | [16, 478, 268, 64] | |
| layer1_maxpool | [16, 478, 268, 64] | [1, 2, 2, 1], stride=2, same | [16, 238, 134, 64] | |
| layer2_conv | [16, 238, 134, 64] | [3, 3, 64, 128], stride=1, valid | [16, 236, 132, 128] | |
| layer3_maxpool | [16, 236, 132, 128] | [1, 2, 2, 1], stride=2, same | [16, 118, 66, 128] | |
| layer4_conv | [16, 118, 66, 128] | [3, 3, 128, 256], stride=1, valid | [16, 116, 64, 256] | |
| layer5_maxpool | [16, 116, 64, 256] | [1, 2, 2, 1], stride=2, same | [16, 58, 32, 256] | |
| layer6_conv | [16, 58, 32, 256] | [3, 3, 256, 512], stride=1, valid | [16, 56, 30, 512] | |
| layer7_maxpool | [16, 56, 30, 512] | [1, 2, 2, 1], stride=2, same | [16, 28, 15, 512] | |
| layer8_conv | [16, 28, 15, 512] | [1, 1, 512, 64], stride=1, valid | [16, 28, 15, 64] | |
| layer9_conv | [16, 28, 15, 64] | [1, 1, 64, 8], stride=1, valid | [16, 28, 15, 8] | |
| layer10_conv | [16, 28, 15, 8] | [1, 1, 8, 1], stride=1, valid | [16, 28, 15, 1] | |
| layer11_fc | [16, ] | [16, 420, 256] | [16, 256] | |
| layer12_fc | [16, 256] | [16, 256, 48] | [16, 48]=[16, 16, 3] |
5.3. 网络训练代码
全部的标注图像共491,使用其中包含检测目标的图像进行训练。
最早使用固定的学习速率,发现损失值降至一定程度后,出现突然上升,随后长时间运行不收敛速度极慢。于是根据损失值的下降,逐级减小学习速率。虽然仍然后在训练至一定程度后出现损失值突然上升,但是最小损失值得到了大幅下降。下方代码在2小时左右的时间内训练得到0.0002的最小损失值。
最终在测试中发现,模型对样本图像的计算效果较好,但是非样本图像几乎完全错误。具体见下述的测试部分说明。
import tensorflow as tf
import numpy as np
import cv2
import os
BATCH_SIZE = 16 # 训练batch大小
TRAIN_STEPS = 2000000 # 训练step数
IMAGE_WIDTH = 480
IMAGE_HEIGHT = 270
NUM_CHANNELS = 3
NUM_OBJECTS = 16
CONV_SIZE = 3 # 卷积尺寸
REGULARIZER_LAMBDA = 0.0001 # L2正则化权重
OBJ_DETECTION_THRESHOLD = 0.5 # 目标识别概率超过该门限表示发现目标
class CNNLeNet:
"""
仿照LeNet建立简单的CNN
"""
# 建立网络
@classmethod
def train(cls, path):
# 建立样本tensor
x = tf.placeholder(
dtype=tf.float32, shape=[BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS], name="x_input")
y_ = tf.placeholder(dtype=tf.float32, shape=[BATCH_SIZE, NUM_OBJECTS, 3], name='y_input')
# 建立graph
with tf.variable_scope("layer0_conv"):
layer0_weight = tf.get_variable("weight", [CONV_SIZE, CONV_SIZE, NUM_CHANNELS, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer0_bias = tf.get_variable("bias", [64],
initializer=tf.constant_initializer(0.0))
layer0_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(x, layer0_weight, strides=[1, 1, 1, 1], padding="VALID"), layer0_bias),
alpha=1.2)
with tf.variable_scope("layer1_maxpool"):
layer1_maxpool = tf.nn.max_pool(layer0_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("layer2_conv"):
layer2_weight = tf.get_variable("weight", [CONV_SIZE, CONV_SIZE, 64, 128],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer2_bias = tf.get_variable("bias", [128],
initializer=tf.constant_initializer(0.0))
layer2_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(layer1_maxpool, layer2_weight, strides=[1, 1, 1, 1], padding="VALID"), layer2_bias),
alpha=1.2)
with tf.variable_scope("layer3_maxpool"):
layer3_maxpool = tf.nn.max_pool(layer2_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("layer4_conv"):
layer4_weight = tf.get_variable("weight", [CONV_SIZE, CONV_SIZE, 128, 256],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer4_bias = tf.get_variable("bias", [256],
initializer=tf.constant_initializer(0.0))
layer4_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(layer3_maxpool, layer4_weight, strides=[1, 1, 1, 1], padding="VALID"), layer4_bias),
alpha=1.2)
with tf.variable_scope("layer5_maxpool"):
layer5_maxpool = tf.nn.max_pool(layer4_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("layer6_conv"):
layer6_weight = tf.get_variable("weight", [CONV_SIZE, CONV_SIZE, 256, 512],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer6_bias = tf.get_variable("bias", [512],
initializer=tf.constant_initializer(0.0))
layer6_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(layer5_maxpool, layer6_weight, strides=[1, 1, 1, 1], padding="VALID"), layer6_bias),
alpha=1.2)
with tf.variable_scope("layer7_maxpool"):
layer7_maxpool = tf.nn.max_pool(layer6_conv, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
with tf.variable_scope("layer8_conv"):
layer8_weight = tf.get_variable("weight", [1, 1, 512, 64],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer8_bias = tf.get_variable("bias", [64],
initializer=tf.constant_initializer(0.0))
layer8_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(layer7_maxpool, layer8_weight, strides=[1, 1, 1, 1], padding="VALID"), layer8_bias),
alpha=1.2)
with tf.variable_scope("layer9_conv"):
layer9_weight = tf.get_variable("weight", [1, 1, 64, 8],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer9_bias = tf.get_variable("bias", [8],
initializer=tf.constant_initializer(0.0))
layer9_conv = tf.nn.leaky_relu(tf.nn.bias_add(
tf.nn.conv2d(layer8_conv, layer9_weight, strides=[1, 1, 1, 1], padding="VALID"), layer9_bias),
alpha=1.2)
with tf.variable_scope("layer10_conv"):
layer10_weight = tf.get_variable("weight", [1, 1, 8, 1],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer10_bias = tf.get_variable("bias", [1],
initializer=tf.constant_initializer(0.0))
layer10_conv = tf.nn.leaky_relu(tf.nn.bias_add(tf.nn.conv2d(
layer9_conv, layer10_weight, strides=[1, 1, 1, 1], padding="VALID"), layer10_bias),
alpha=1.2)
layer10_conv_shape = layer10_conv.get_shape().as_list() # 取得tensor的shape,并且转为list
layer10_nodes = layer10_conv_shape[1]*layer10_conv_shape[2]*layer10_conv_shape[3]
# 为下层全连接计算,转换tensor的shape为[BATCH_SIZE, nodes],BATCH_SIZE即为layer10_conv_shape[0]
layer10_reshape = tf.reshape(layer10_conv, shape=[BATCH_SIZE, layer10_nodes])
with tf.variable_scope("layer11_fc"):
layer11_nodes = 256
layer11_weight = tf.get_variable("weight", [layer10_nodes, layer11_nodes],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer11_bias = tf.get_variable("bias", [layer11_nodes],
initializer=tf.constant_initializer(0.0))
layer11_fc = tf.nn.leaky_relu(tf.matmul(layer10_reshape, layer11_weight)+layer11_bias, alpha=1.2)
# 全连接层权重正则化
tf.add_to_collection("loss", tf.contrib.layers.l2_regularizer(REGULARIZER_LAMBDA)(layer11_weight))
with tf.variable_scope("layer12_fc"):
layer12_nodes = NUM_OBJECTS * 3 # 48
layer12_weight = tf.get_variable("weight", [layer11_nodes, layer12_nodes],
initializer=tf.truncated_normal_initializer(stddev=0.1))
layer12_bias = tf.get_variable("bias", [layer12_nodes],
initializer=tf.constant_initializer(0.0))
layer12_fc = tf.nn.leaky_relu(tf.matmul(layer11_fc, layer12_weight)+layer12_bias, alpha=1.2)
# 为了下层计算损失函数,转换tensor的shape为[BATCH_SIZE, NUM_OBJECTS, 3],BATCH_SIZE即为layer12_fc_shape[0]
y = tf.reshape(layer12_fc, shape=[BATCH_SIZE, NUM_OBJECTS, 3])
# 全连接层权重正则化
tf.add_to_collection("loss", tf.contrib.layers.l2_regularizer(REGULARIZER_LAMBDA)(layer12_weight))
# 计算样本损失
loss_obj = tf.reduce_mean(
tf.square(y[:, :, 0]-y_[:, :, 0]) + # 概率损失
0.5 * (tf.square(y[:, :, 1] - y_[:, :, 1]) + tf.square(y[:, :, 2] - y_[:, :, 2]))) # 坐标损失
tf.add_to_collection("loss", loss_obj)
# 将样本损失和全连接层权重正则损失相加
loss = tf.add_n(tf.get_collection("loss"))
# 定义学习率,随loss的范围而逐步减小,数值选择为试验所得
rate = tf.Variable(0.001, trainable=False)
tf.assign(rate, tf.where(tf.greater(loss, 0.02), 0.001,
(tf.where(tf.greater(loss, 0.01), 0.0005,
tf.where(tf.greater(loss, 0.005), 0.00001,
tf.where(tf.greater(loss, 0.001), 0.000005, 0.000001))))))
# 定义训练step
train_step = tf.train.AdamOptimizer(rate).minimize(loss)
###############################################################
# 读取全部的TFRecord文件
# 获取文件列表
files = tf.train.match_filenames_once(os.path.join(path, "cap*.tfrecords"))
# 创建输入队列
queue = tf.train.string_input_producer(files, shuffle=True)
# 建立TFRecordReader
reader = tf.TFRecordReader()
_, serialized_example = reader.read(queue)
rec_features = tf.parse_single_example( # 返回字典,字典key值即features参数中的key值
serialized_example,
features={
# 写入时shape固定的数值用FixedLenFeature
"filename": tf.FixedLenFeature(shape=[], dtype=tf.string), # 由于只有1个值也可以用shape[1],返回list
"width": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"height": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"data": tf.FixedLenFeature(shape=[], dtype=tf.string),
# 写入时shape不固定的数值,读出时用VarLenFeature,读出为SparseTensorValue类对象
"object/label": tf.VarLenFeature(dtype=tf.string),
"object/bbox/xmin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/xmax": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymax": tf.VarLenFeature(dtype=tf.int64),
}
)
# 模型保存
saver = tf.train.Saver()
# 保存最小的目标损失值,不包含正则损失
loss_min = 0.01
# 运行Session
with tf.Session() as sess:
sess.run(tf.local_variables_initializer()) # 初始化局部变量,用于取得文件列表
print(sess.run(files)) # 打印文件列表
sess.run(tf.global_variables_initializer()) # 初始化全局变量
# 用子线程启动TFRecord的输入队列
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 训练循环
for i in range(TRAIN_STEPS):
# 此处定义,用于在此层使用
rec = None
# 训练数据初值
x_input = np.zeros(shape=(BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS), dtype=float)
y_input = np.zeros(shape=(BATCH_SIZE, NUM_OBJECTS, 3), dtype=float)
# 建立训练样本batch
for j in range(BATCH_SIZE):
# 读取一个TFRecord文件,直到该TFRecord内部包含pig标签
label_list = []
# TFRecord中返回bytes类型,需要用str.encode转成bytes用于比较
while "pig".encode("utf-8") not in label_list:
rec = sess.run(rec_features)
label_list = rec["object/label"].values
# 取得图像数据
img = np.fromstring(rec["data"], np.uint8)
img = np.reshape(img, (IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS))
# 至此已取得包含pig标签的标注数据
# 训练数据组装
# 取得图像数据
x_input[j, :, :, :] = img/255.0 # /255.0进行uint8归一化
# 取得样本结果
obj_ind = 0 # y_input中的目标索引
for index, label in enumerate(rec["object/label"].values): # 用enumerate建立列表的遍历对象
# TFRecord中返回bytes类型,需要用str.encode转成bytes用于比较
if label == "pig".encode("utf-8"): # 发现目标label
# 目标概率
y_input[j, obj_ind, 0] = 1.0
# x轴中心点
y_input[j, obj_ind, 1] = (rec["object/bbox/xmin"].values[index] + rec["object/bbox/xmax"].values[index]) / 2.0 / IMAGE_WIDTH
# y轴中心点
y_input[j, obj_ind, 2] = (rec["object/bbox/ymin"].values[index] + rec["object/bbox/ymax"].values[index]) / 2.0 / IMAGE_HEIGHT
# 目标索引递增
obj_ind += 1
# 运行当前batch训练
sess.run(train_step, feed_dict={x: x_input, y_: y_input})
# print("train_step: {0}".format(i))
# 在训练样本中检查训练成果
if i % 10 == 0:
loss_output = sess.run(loss_obj, feed_dict={x: x_input, y_: y_input})
print("Step {1} train_loss: {0}".format(loss_output, i))
# 保存损失值最小的模型
if loss_output < loss_min:
loss_min = loss_output
saver.save(sess, os.path.join(path, "model_loss_min.ckpt"))
print("LOSS MIN model saved: {0}".format(loss_min))
else:
print("LOSS MIN: {0}".format(loss_min))
# 用OpenCV显示处理图像
y_output = sess.run(y, feed_dict={x: x_input, y_: y_input})
# 显示batch中的0和1索引的图像
img0 = x_input[0, :, :, :]
img0 = img0*255.0
img0 = img0.astype(np.uint8)
# 绘制输入中心点
for obj, p in enumerate(y_input[0, :, 0]):
if p > 0.5:
img0 = cv2.circle(img0, (
int(y_input[0, obj, 1] * IMAGE_WIDTH), int(y_input[0, obj, 2] * IMAGE_HEIGHT)),
radius=7, color=(0, 0, 255), thickness=2)
# 遍历图像0中的全部目标
print(y_output[0, :, :])
cnt = 0
for obj, p in enumerate(y_output[0, :, 0]):
if p > OBJ_DETECTION_THRESHOLD: # 目标概率大于门限,则认为发现目标
img0 = cv2.circle(img0, (int(y_output[0, obj, 1]*IMAGE_WIDTH), int(y_output[0, obj, 2]*IMAGE_HEIGHT)), radius=5, color=(0, 255, 0), thickness=cv2.FILLED)
cnt += 1
img0 = cv2.putText(img0,
"{0}".format(cnt),
(5, IMAGE_HEIGHT-5), # 左下角显示目标数目
cv2.FONT_HERSHEY_PLAIN,
1,
(0, 255, 0))
# 显示图像
cv2.imshow("image", img0)
cv2.waitKey(10)
coord.request_stop() # 结束线程
coord.join(threads) # 等待线程结束
if __name__ == "__main__":
CNNLeNet.train("d:/temp/xml2tfrecord/images")
5.4. 使用样本图像测试
使用训练样本图像测试发现大多数图像都得到了正确的计数和编差较小的中心点位置。极少数图像出现了错误识别(把图中纸箱作为目标,可能与部分错误标注有关),或者较大的中心点偏差。
图中红圈为标注的中心点,绿点为网络计算所得的中心点,左下角数字为网络计算得到的计数值。



代码如下:
import tensorflow as tf
import numpy as np
import cv2
import os
BATCH_SIZE = 16
IMAGE_WIDTH = 480
IMAGE_HEIGHT = 270
NUM_CHANNELS = 3
NUM_OBJECTS = 16
CONV_SIZE = 3 # 卷积尺寸
REGULARIZER_LAMBDA = 0.0001 # L2正则化权重
OBJ_DETECTION_THRESHOLD = 0.5 # 目标识别概率超过该门限表示发现目标
###############################################################
# 读取全部的TFRecord文件,用于样本验证
# 获取文件列表
files = tf.train.match_filenames_once(os.path.join("d:/temp/xml2tfrecord/images", "cap*.tfrecords"))
# 创建输入队列
queue = tf.train.string_input_producer(files, shuffle=True)
# 建立TFRecordReader
reader = tf.TFRecordReader()
_, serialized_example = reader.read(queue)
rec_features = tf.parse_single_example( # 返回字典,字典key值即features参数中的key值
serialized_example,
features={
# 写入时shape固定的数值用FixedLenFeature
"filename": tf.FixedLenFeature(shape=[], dtype=tf.string), # 由于只有1个值也可以用shape[1],返回list
"width": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"height": tf.FixedLenFeature(shape=[], dtype=tf.int64),
"data": tf.FixedLenFeature(shape=[], dtype=tf.string),
# 写入时shape不固定的数值,读出时用VarLenFeature,读出为SparseTensorValue类对象
"object/label": tf.VarLenFeature(dtype=tf.string),
"object/bbox/xmin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/xmax": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymin": tf.VarLenFeature(dtype=tf.int64),
"object/bbox/ymax": tf.VarLenFeature(dtype=tf.int64),
}
)
with tf.Session() as sess:
# 载入已保存的模型图
saver = tf.train.import_meta_graph("d:/temp/xml2tfrecord/images/model_loss_min.ckpt.meta")
# 载入模型内的所有参数
saver.restore(sess, tf.train.latest_checkpoint("d:/temp/xml2tfrecord/images/"))
# 取得输出y的tensor和输入的placeholder的tensor
graph = tf.get_default_graph()
try:
y_tensor = graph.get_tensor_by_name("layer12_fc/Reshape:0")
x_tensor = graph.get_tensor_by_name("x_input:0")
except (TypeError, KeyError):
print("fail to find the tensor")
else:
sess.run(tf.local_variables_initializer()) # 初始化局部变量,用于取得文件列表
print(sess.run(files)) # 打印文件列表
# 用子线程启动TFRecord的输入队列
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
# 测试循环
while True:
# 此处定义,用于在此层使用
rec = None
# 训练数据初值
x_input = np.zeros(shape=(BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS), dtype=float)
y_input = np.zeros(shape=(BATCH_SIZE, NUM_OBJECTS, 3), dtype=float)
# 建立训练样本batch
for j in range(BATCH_SIZE):
# 读取一个TFRecord文件,直到该TFRecord内部包含pig标签
label_list = []
# TFRecord中返回bytes类型,需要用str.encode转成bytes用于比较
while "pig".encode("utf-8") not in label_list:
rec = sess.run(rec_features)
label_list = rec["object/label"].values
# 取得图像数据
img = np.fromstring(rec["data"], np.uint8)
img = np.reshape(img, (IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS))
# 至此已取得包含pig标签的标注数据
# 训练数据组装
# 取得图像数据
x_input[j, :, :, :] = img / 255.0 # /255.0进行uint8归一化
# 取得样本结果
obj_ind = 0 # y_input中的目标索引
for index, label in enumerate(rec["object/label"].values): # 用enumerate建立列表的遍历对象
# TFRecord中返回bytes类型,需要用str.encode转成bytes用于比较
if label == "pig".encode("utf-8"): # 发现目标label
# 目标概率
y_input[j, obj_ind, 0] = 1.0
# x轴中心点
y_input[j, obj_ind, 1] = (rec["object/bbox/xmin"].values[index] +
rec["object/bbox/xmax"].values[index]) / 2.0 / IMAGE_WIDTH
# y轴中心点
y_input[j, obj_ind, 2] = (rec["object/bbox/ymin"].values[index] +
rec["object/bbox/ymax"].values[index]) / 2.0 / IMAGE_HEIGHT
# 目标索引递增
obj_ind += 1
# 运行当前batch训练
y_output = sess.run(y_tensor, feed_dict={x_tensor: x_input})
# 显示batch中的0和1索引的图像
img0 = x_input[0, :, :, :]
img0 = img0 * 255.0
img0 = img0.astype(np.uint8)
# 绘制输入中心点
for obj, p in enumerate(y_input[0, :, 0]):
if p > 0.5:
img0 = cv2.circle(img0, (
int(y_input[0, obj, 1] * IMAGE_WIDTH), int(y_input[0, obj, 2] * IMAGE_HEIGHT)),
radius=7, color=(0, 0, 255), thickness=2)
# 遍历图像0中的全部目标
print(y_output[0, :, :])
cnt = 0
for obj, p in enumerate(y_output[0, :, 0]):
if p > OBJ_DETECTION_THRESHOLD: # 目标概率大于门限,则认为发现目标
img0 = cv2.circle(img0, (
int(y_output[0, obj, 1] * IMAGE_WIDTH), int(y_output[0, obj, 2] * IMAGE_HEIGHT)), radius=5,
color=(0, 255, 0), thickness=cv2.FILLED)
cnt += 1
img0 = cv2.putText(img0,
"{0}".format(cnt),
(5, IMAGE_HEIGHT - 5), # 左下角显示目标数目
cv2.FONT_HERSHEY_PLAIN,
1,
(0, 255, 0))
# 显示图像
cv2.imshow("image", img0)
cv2.waitKey(0)
# coord.request_stop() # 结束线程
# coord.join(threads) # 等待线程结束
5.5. 使用非样本图像测试
测试发现使用非样本图像几乎完全错误


代码如下:
import tensorflow as tf
import numpy as np
import cv2
import os
BATCH_SIZE = 16
IMAGE_WIDTH = 480
IMAGE_HEIGHT = 270
NUM_CHANNELS = 3
NUM_OBJECTS = 16
CONV_SIZE = 3 # 卷积尺寸
REGULARIZER_LAMBDA = 0.0001 # L2正则化权重
OBJ_DETECTION_THRESHOLD = 0.5 # 目标识别概率超过该门限表示发现目标
cap = cv2.VideoCapture("d:/temp/xml2tfrecord/vid_test.mp4")
if cap.isOpened():
print("vid_test opened")
with tf.Session() as sess:
# 载入已保存的模型图
saver = tf.train.import_meta_graph("d:/temp/xml2tfrecord/images/model_loss_min.ckpt.meta")
# 载入模型内的所有参数
saver.restore(sess, tf.train.latest_checkpoint("d:/temp/xml2tfrecord/images/"))
# 取得输出y的tensor和输入的placeholder的tensor
graph = tf.get_default_graph()
try:
y_tensor = graph.get_tensor_by_name("layer12_fc/Reshape:0")
x_tensor = graph.get_tensor_by_name("x_input:0")
except (TypeError, KeyError):
print("fail to find the tensor")
else:
# 训练数据初值
x_input = np.zeros(shape=(BATCH_SIZE, IMAGE_HEIGHT, IMAGE_WIDTH, NUM_CHANNELS), dtype=float)
y_input = np.zeros(shape=(BATCH_SIZE, NUM_OBJECTS, 3), dtype=float)
# 测试循环
while True:
# 读取视频图像帧
ret, frame = cap.read()
# 修改图像帧宽高与模型输入相匹配
if ret:
frame = cv2.resize(frame, dsize=(IMAGE_WIDTH, IMAGE_HEIGHT))
# 取得图像数据,放入0位置
x_input[0, :, :, :] = frame / 255.0 # /255.0进行uint8归一化
# 运行当前batch训练
y_output = sess.run(y_tensor, feed_dict={x_tensor: x_input})
# 显示batch中的0和1索引的图像
img0 = x_input[0, :, :, :]
img0 = img0 * 255.0
img0 = img0.astype(np.uint8)
# 遍历图像0中的全部目标
cnt = 0
for obj, p in enumerate(y_output[0, :, 0]):
if p > OBJ_DETECTION_THRESHOLD: # 目标概率大于门限,则认为发现目标
img0 = cv2.circle(img0, (
int(y_output[0, obj, 1] * IMAGE_WIDTH), int(y_output[0, obj, 2] * IMAGE_HEIGHT)), radius=5,
color=(0, 255, 0), thickness=cv2.FILLED)
cnt += 1
img0 = cv2.putText(img0,
"{0}".format(cnt),
(5, IMAGE_HEIGHT - 5), # 左下角显示目标数目
cv2.FONT_HERSHEY_PLAIN,
1,
(0, 255, 0))
# 显示图像
cv2.imshow("image", img0)
cv2.waitKey(0)
else:
cap.set(cv2.CAP_PROP_POS_FRAMES, 0)
6. 后续问题
- **怎样解决过拟合问题?**增加样本?样本图像随机化?
- **怎样将训练好的模型用于实际应用?**训练模型中包含batch维度的结构,在实际应用中怎样从模型中去掉?见https://blog.csdn.net/botao_li/article/details/85112081
- **虽然目标数目设置为最大16,但是大多数情况下目标数仍小于该值,数值较大的目标位置相关的神经元训练较少,而目标0的相关神经元每次都会得到训练,怎样解决这种训练不平衡的情况?或者需不需要解决?**目前的训练样本只有0、1、2三种目标数目。之前的设想是用用轮询的方法将训练数据中的目标循环移动起始位置,但是这种训练方法下网络无法得到目标位置排列的规则,即无法判断当前目标输出位置。如果不在训练数据中进行目标位置轮换,则网络会首选从序号低的输出位置输出,这样就需要保证各种目标数目都有足够多的训练样本。