正向概率:假设袋子里面有N个红球,M个黑球,取出一个球,此时摸出黑球的概率是多少。
逆向概率:事先不知道袋子里面红球和黑球数量的比例,取出一个球或者多个球,观察这些取出的球的颜色,可以对袋子中红球和黑球的比例做出推断。
朴素贝叶斯是为了解决逆向概率问题。
朴素贝叶斯算法和之前介绍的分类算法不同,之前介绍的分类算法都是判别模型,如支持向量机、K近邻、决策树等等。判别模型是直接学习出输出Y和特征X之间的关系,直接学习决策函数Y=f(X),或者条件分布P(Y|X)。而朴素贝叶斯算法是生成模型,它是直接找出输出Y和特征X的联合分布,然后利用
得出。
先看看条件独立公式,如果X和Y是相互独立的,那么:
条件概率公式:
全概率公式:
贝叶斯公式:
朴素贝叶斯的假设:每个特征都是独立同分布的,每个特征同等重要,即每个特征是等权重的,只考虑特征是否出现,不考虑特征出现的次数。
以垃圾邮件分类为例子来介绍朴素贝叶斯,假设邮件
,
表示正常邮件,
表示垃圾邮件,判断该邮件是否为垃圾邮件,只需要判断
和
哪个概率大就可以。
其中
和
表示先验概率,
和
表示条件概率。
其中
表示正常邮件的数量,
表示垃圾邮件的数量,
表示总邮件数量。
可以表示为
,
可以表示为
,因为朴素贝叶斯假设每个特征是相互独立的,所以
所以只需要比较 和 的大小就可以判断是否为垃圾邮件。
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import make_classification
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import numpy as np
import warnings
warnings.filterwarnings('ignore')
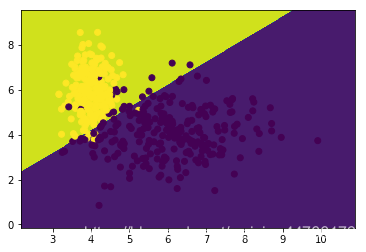
x, y = make_classification(n_clusters_per_class=1, n_samples=500, n_redundant=0, n_features=2, random_state=14)
x = x + 5
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=2)
nb = MultinomialNB().fit(x_train, y_train)
y_pred = nb.predict(x_test)
print('accuracy: ', accuracy_score(y_test, y_pred))
x_min, x_max = x[:, 0].min() - 1, x[:, 0].max() + 1
y_min, y_max = x[:, 1].min() - 1, x[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02), np.arange(y_min, y_max, 0.02))
z = nb.predict(np.c_[xx.ravel(), yy.ravel()])
zz = z.reshape(xx.shape)
plt.contourf(xx, yy, zz)
plt.scatter(x_train[:, 0], x_train[:, 1], c=y_train)
plt.scatter(x_test[:, 0], x_test[:, 1], c=y_pred)
plt.show()