机器学习sklearn之线性回归(Linear Regression)LR
sklearn拟合数据的基本步骤:
-
读取数据
-
拟合数据
-
预测数据
在这里要用到genfromtxt函数
numpy.genfromtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None, excludelist=None, deletechars=None, replace_space='_', autostrip=False, case_sensitive=True, defaultfmt='f%i', unpack=None, usemask=False, loose=True, invalid_raise=True, max_rows=None)[source]
1.fname 文件名
2.delimiter:str,int,or sequence,optional.分割值,表示数组的分割。
3.usecols,选择读哪几行
4.dtype,改行类型
示范一个数据集的操作,
from numpy import genfromtxt
data=genfromtxt('iris.csv',delimiter=',',usecols=(0,1,2,3))
print(data)

准备数据得到数据集,导出所用到的一些库
from numpy import genfromtxt
from sklearn import linear_model
dataPath = r"Delivery.csv"
deliveryData = genfromtxt(dataPath,delimiter=',')
print ("data")
print (deliveryData)

拟合数据
x= deliveryData[:,:-1]
y = deliveryData[:,-1]
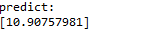
print (x)
print (y)
lr = linear_model.LinearRegression()
lr.fit(x, y)
print (lr)
print("coefficients:")
print (lr.coef_)
print("intercept:")
print (lr.intercept_)
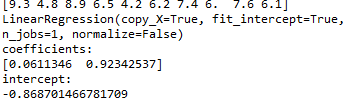
预测数据
xPredict = [102,6]
yPredict = lr.predict([xPredict])
print("predict:")
print (yPredict)