转自:https://blog.csdn.net/sunshine_010/article/details/80039493
In this work, we establish dense correspondences between an RGB image and a surface-based representation of the human body, a task we refer to as dense human pose estimation. We first gather dense correspondences for 50K persons appearing in the COCO dataset by introducing an efficient annotation pipeline. We then use our dataset to train CNN-based systems that deliver dense correspondence ‘in the wild’, namely in the presence of background, occlusions and scale variations. We improve our training set’s effectiveness by training an ‘inpainting’ network that can fill in missing ground truth values, and report clear improvements with respect to the best results that would be achievable in the past. We experiment with fullyconvolutional networks and region-based models and observe a superiority of the latter; we further improve accuracy through cascading, obtaining a system that delivers highly-accurate results in real time. Supplementary materials and videos are provided on the project page http://densepose.org.
在这项工作中,我们建立了RGB图像和人体surface-based的表示之间的密集对应关系,我们称之为密集人体姿态估计。我们首先通过引入高效的annotation pipeline来收集出现在COCO数据集中的5万人的密集对应关系。然后,我们使用我们的数据集来训练基于CNN的系统,“in the wild”实现密集的对应关系,也就是背景,遮挡和尺度变化。我们通过训练能够填补缺失的ground truth值的“inpainting”网络来提高我们的训练集的有效性,并报告过去可以实现的最佳结果方面的明显改进。我们试验用全卷积网络和region-based的模型,并观察后者的优越性;我们通过cascading进一步提高准确性,获得实时提供高精度结果的系统。补充材料和视频在项目页面http://densepose.org上提供。
This work aims at pushing further the envelope of human understanding in images by establishing dense correspondences from a 2D image to a 3D, surface-based representation of the human body. We can understand this task as involving several other problems, such as object detection, pose estimation, part and instance segmentation either as special cases or prerequisites. Addressing this task has applications in problems that require going beyond plain landmark localization, such as graphics, augmented reality, or human-computer interaction, and could also be a stepping stone towards general 3D-based object understanding.
这项工作旨在通过建立从2D图像到3D人体surface-based的密集对应关系,进一步推动人类对图像理解的包络。我们可以将此任务理解为涉及其他几个问题,例如物体检测,姿态估计,局部和实例分割,作为特殊情况或先决条件。解决这个问题的应用需要超越平面标志性定位(如图形,增强现实或人机交互)的问题,也可能成为实现基于3D物体理解的基石。
The task of establishing dense correspondences from an image to a surface-based model has been addressed mostly in the setting where a depth sensor is available, as in the Vitruvian manifold of [41], metric regression forests [33], or the more recent dense point cloud correspondence of [44]. By contrast, in our case we consider a single RGB image as input, based on which we establish a correspondence between surface points and image pixels.
从图像到基于表面的模型建立密集对应的任务主要在深度传感器可用的环境中解决,如[41]的Vitruvian manifold,metric regression forests[33]或更近期dense point cloud correspondence [44]。相反,在我们的例子中,我们将单个RGB图像视为输入,基于此我们建立了surface points和image pixels之间的对应关系。
Several other works have recently aimed at recovering dense correspondences between pairs [3] or sets of RGB images [48, 10] in an unsupervised setting. More recently, [42] used the equivariance principle in order to align sets of images to a common coordinate system, while following the general idea of groupwise image alignment, e.g. [23, 21].
最近的几项工作旨在恢复密集对[3]或RGB图像集[48,10]之间的密切对应在无人监督的设置。最近,[42]使用equivariance原理来将图像集合对齐到一个共同的coordinates系,同时遵循groupwise image alignment的一般思想,例如, [23,21]。
While these works are aiming at general categories, our work is focused on arguably the most important visual category, humans. For humans one can simplify the task by exploiting parametric deformable surface models, such as the Skinned Multi-Person Linear (SMPL) model of [2], or the more recent Adam model of [14] obtained through carefully controlled 3D surface acquisition. Turning to the task of image-to-surface mapping, in [2], the authors propose a two-stage method of first detecting human landmarks through a CNN and then fitting a parametric deformable surface model to the image through iterative minimization. In parallel to our work, [20] develop the method of [2] to operate in an end-to-end fashion, incorporating the iterative reprojection error minimization as a module of a deep network that recovers 3D camera pose and the lowdimensional body parametrization.
虽然这些工作是针对一般类别的,但我们的工作集中在可以说是最重要的视觉类别 - 人类。对于人类来说,可以通过利用参数变形表面模型(如[2]的Skinned Multi-Person Linear(SMPL)model)或通过仔细控制3D表面采集获得的更近期的Adam模型[14]来简化任务。谈到图像到曲面映射的任务,在文献[2]中,作者提出了一种two-stage方法,首先通过CNN检测人类landmarks,然后通过迭代最小化将参数变形表面模型拟合到图像。与我们的工作平行[20]开发了[2]以端到端方式运行的方法,将iterative reprojection error最小化作为深度网络的模块,其恢复3Dcamera pose 和 lowdimensional body参数化。
Our methodology differs from all these works in that we take a full-blown supervised learning approach and gather ground-truth correspondences between images and a detailed, accurate parametric surface model of the human body [27]: rather than using the SMPL model at test time we only use it as a means of defining our problem during training. Our approach can be understood as the next step in the line of works on extending the standard for humans in [26, 1, 19, 7, 40, 18, 28]. Human part segmentation masks have been provided in the Fashionista [46], PASCAL-Parts [6], and Look-Into-People (LIP) [12] datasets; these can be understood as providing a coarsened version of image-to-surface correspondence, where rather than continuous coordinates one predicts discretized part labels. Surface-level supervision was only recently introduced for synthetic images in [43], while in [22] a dataset of 8515 images is annotated with keypoints and semi-automated fits of 3D models to images. In this work instead of compromising the extent and realism of our training set we introduce a novel annotation pipeline that allows us to gather ground-truth correspondences for 50K images of the COCO dataset, yielding our new DensePose-COCO dataset.
我们的方法不同于所有这些工作,因为我们采用全面的监督式学习方法,并收集图像与详细,精确的人体参数曲面模型之间的ground-truth correspondences[27]:而不是在测试中使用SMPL模型我们只用它作为定义训练期间问题的一种手段。我们的方法可以理解为[26,1,19,7,40,18,28]中延伸人类标准的工作路线的下一步。在Fashionista [46],PASCAL-Parts [6]和Look-Into-People(LIP)[12]数据集中提供了Human part segmentation masks;这些可以被理解为提供image-to-surface correspondence的粗化版本,而不是连续coordinates,其预测离散的部分标签。表面水平监督最近才引入了合成图像[43],而[22]中的8515图像数据集使用关键点和3D自动拟合图像进行注释。在这项工作中,我们引入了一种新的annotation pipeline,使我们能够收集COCO数据集的50K图像的ground-truth correspondences关系,而不是损害我们训练集的范围和真实性,从而产生我们新的DensePose-COCO数据集。
Our work is closest in spirit to the recent DenseReg framework [13], where CNNs were trained to successfully establish dense correspondences between a 3D model and images ‘in the wild’. That work focused mainly on faces, and evaluated their results on datasets with moderate pose variability. Here, however, we are facing new challenges, due to the higher complexity and flexibility of the human body, as well as the larger variation in poses. We address these challenges by designing appropriate architectures, as described in Sec. 3, which yield substantial improvements over a DenseReg-type fully convolutional architecture. By combining our approach with the recent Mask-RCNN system of [15] we show that a discriminatively trained model can recover highly-accurate correspondence fields for complex scenes involving tens of persons with real-time speed: on a GTX 1080 GPU our system operates at 20-26 frames per second for a 240 × 320 image or 4-5 frames per second for a 800 × 1100 image.
我们的工作与最近的DenseReg框架最接近[13],CNN的训练是成功地在3D模型和“in the wild”图像之间建立密集对应关系。这项工作主要集中在人脸上,并对具有中等姿势变化的数据集评估其结果。然而,在这里,由于人体更高的复杂性和灵活性,以及更大的姿势变化,我们正面临新的挑战。我们通过设计适当的体系结构来解决这些挑战, 3,它比DenseReg型完全卷积体系结构产生了实质性的改进。通过将我们的方法与[15]中最近的Mask-RCNN系统相结合,我们证明了一个有区别地训练的模型可以为包含数十个人的复杂场景以实时速度恢复高精度对应场:在GTX 1080 GPU上,我们的系统运行对于240×320图像为每秒20-26帧或对于800×1100图像为每秒4-5帧。
Our contributions can be summarized in three points. Firstly, as described in Sec. 2, we introduce the first manually-collected ground truth dataset for the task, by gathering dense correspondences between the SMPL model [27] and persons appearing in the COCO dataset. This is accomplished through a novel annotation pipeline that exploits 3D surface information during annotation.
我们的贡献可以总结为三点。首先,如第二节所述。 2,我们通过收集SMPL模型[27]和出现在COCO数据集中的人之间的密集对应关系,介绍第一个手动收集的任务的ground truth数据集。这是通过一种新颖的annotation pipeline完成的,该pipeline在annotation过程中利用3D surface信息。
Secondly, as described in Sec. 3, we use the resulting dataset to train CNN-based systems that deliver dense correspondence ‘in the wild’, by regressing body surface coordinates at any image pixel. We experiment with both fully-convolutional architectures, relying on Deeplab [4], and also with region-based systems, relying on MaskRCNN [15], observing a superiority of region-based models over fully-convolutional networks. We also consider cascading variants of our approach, yielding further improvements over existing architectures.
其次,如第二节所述。如图3所示,我们使用结果数据集来训练基于CNN的系统,通过回归任何image pixels处的身体surface coordinates,在in the wild提供密集的coordinates关系。我们依靠Deeplab [4]以及region-based的系统,基于MaskRCNN [15]的全卷积架构实验,观察region-based模型在完全卷积网络上的优越性。我们还考虑了我们方法的cascading variants,相对于现有体系结构产生了进一步的改进。
Thirdly, we explore different ways of exploiting our constructed ground truth information. Our supervision signal is defined over a randomly chosen subset of image pixels per training sample. We use these sparse correspondences to train a ‘teacher’ network that can ‘inpaint’ the supervision signal in the rest of the image domain. Using this inpainted signal results in clearly better performance when compared to either sparse points, or any other existing dataset, as shown experimentally in Sec. 4.
第三,我们探索利用我们构建的ground truth信息的不同方式。我们的监督信号被定义在每个训练样本随机选择的image pixels子集上。我们使用这些稀疏的对应关系来训练“teacher”网络,该网络可以在图像域的其余部分“inpaint”监督信号。与稀疏点或任何其他现有数据集相比,使用此inpainted后的信号可显着提高性能,如第4节中的实验所示。
Our experiments indicate that dense human pose estimation is to a large extent feasible, but still has space for improvement. We conclude our paper with some qualitative results and directions that show the potential of the method. We will make code and data publicly available from our project’s webpage, http://densepose.org.
我们的实验表明,密集的人体姿态估计在很大程度上是可行的,但仍有改进空间。我们用一些定性结果和方向来总结我们的论文,说明该方法的潜力。我们将从我们项目的网页http://densepose.org公开提供代码和数据。
COCO-DensePose Dataset
Gathering rich, high-quality training sets has been a catalyst for progress in the classification [38], detection and segmentation [8, 26] tasks. There currently exists no manually collected ground-truth for dense human pose estimation for real images. The works of [22] and [43] can be used as surrogates, but as we show in Sec. 4 provide worse supervision.
COCO密集的数据集
收集丰富,高质量的训练集已成为分类[38],检测和分割[8,26]任务进展的催化剂。目前,对于真实图像的密集人体姿态估计,不存在手动收集的ground truth。 [22]和[43]的工作可以作为替代品,但正如我们在第二节中展示的那样。 第4节提供更差的监督。
In this Section we introduce our COCO-DensePose dataset, alongside with evaluation measures that allow us to quantify progress in the task in Sec. 4. We have gathered annotations for 50K humans, collecting more then 5 million manually annotated correspondences.
在本节中,我们将介绍我们的COCO-DensePose数据集,以及评估测量,使我们能够量化第二部分中的任务进度。 第4节我们收集了5万人的注释,收集了500多万手动注释的correspondences。
We start with a presentation of our annotation pipeline, since this required several design choices that may be more generally useful for 3D annotation. We then turn to an analysis of the accuracy of the gathered ground-truth, alongside with the resulting performance measures used to assess the different methods.
我们首先介绍我们的annotation pipeline,因为这需要几个设计选择,这对3D annotation来说可能更为普遍。然后,我们转而分析所收集的ground-truth的准确性,以及用于评估不同方法的结果性能度量。
Learning Dense Human Pose Estimation
We now turn to the task of training a deep network that predicts dense correspondences between image pixels and surface points. Such a task was recently addressed in the Dense Regression (DenseReg) system of [13] through a fully-convolutional network architecture [4]. In this work, we introduce improved architectures by combining the DenseReg approach with the Mask-RCNN architecture [15], yielding our ‘DensePose-RCNN’ system. We develop cascaded extensions of DensePose-RCNN that further improve accuracy and describe a training-based interpolation method that allows us to turn a sparse supervision signal into a denser and more effective variant.
学习密集的人体姿势估计
现在我们转向训练一个预测image pixels和surface points之间密集对应关系的深层网络的任务。最近,通过完全卷积网络体系结构[4]在密集回归(DenseReg)系统[13]中解决了这样的任务。在这项工作中,我们通过将DenseReg方法与Mask-RCNN架构相结合来引入改进的架构[15],产生了我们的’DensePose-RCNN’系统。我们开发了DensePose-RCNN的cascading扩展,进一步提高了准确性,并描述了一种基于训练的interpolation方法,该方法允许我们将稀疏监督信号变成更密集和更有效的变体。
3.1. Fully-convolutional dense pose regression
The simplest architecture choice consists in using a fully convolutional network (FCN) that combines a classification and a regression task, similar to DenseReg. In a first step, we classify a pixel as belonging to either background, or one among several region parts which provide a coarse estimate of surface coordinates. This amounts to a labelling task that is trained using a standard cross-entropy loss. In a second step, a regression system indicates the exact coordinates of the pixel within the part. Since the human body has a complicated structure, we break it into multiple independent pieces and parameterize each piece using a local two-dimensional coordinate system, that identifies the position of any node on this surface part.
3.1 全卷积密集姿态回归
最简单的架构选择包括使用完全卷积网络(FCN),该网络结合了分类和回归任务,类似于DenseReg。在第一步中,我们将一个pixel归类为属于背景或者几个区域部分中的一个,它们提供surface coordinates的粗略估计。这相当于使用标准交叉熵损失进行训练的标签任务。第二步,回归系统指出part pixel的确切coordinates。由于人体结构复杂,因此我们将其分解为多个独立的部分,并使用局部二维coordinates系对每个部分进行参数化,以识别该表面部分上任何节点的位置。
3.2. Region-based Dense Pose Regression
Using an FCN makes the system particularly easy to train, but loads the same deep network with too many tasks, including part segmentation and pixel localization, while at the same time requiring scale-invariance which becomes challenging for humans in COCO. Here we adopt the region-based approach of [34, 15], which consists in a cascade of proposing regions-of-interest (ROI), extracting region-adapted features through ROI pooling [16, 15] and feeding the resulting features into a region-specific branch. Such architectures decompose the complexity of the task into controllable modules and implement a scale-selection mechanism through ROI-pooling. At the same time, they can also be trained jointly in an end-to-end manner [34].
3.2 region-based的稠密姿态回归
使用FCN使得该系统特别容易训练,但加载相同的深度网络和太多的任务,包括part 分割和pixel定位,同时需要尺度不变性,这对于COCO中的人来说变得具有挑战性。在这里,我们采用region-based的方法[34,15],其中包括提案区域(ROI)cascading,通过ROI-pooling提取区域自适应特征[16,15],并将结果特征提供给一个区域特定的分支。这样的体系结构将任务的复杂性分解为可控模块,并通过ROI-pooling实现规模选择机制。同时,他们也可以以端到端的方式联合训练[34]。
We adopt the settings introduced in [15], involving the construction of Feature Pyramid Network [25] features, and ROI-Align pooling, which have been shown to be important for tasks that require spatial accuracy. We adapt this architecture to our task, so as to obtain dense part labels and coordinates within each of the selected regions.
我们采用[15]中介绍的设置,涉及构建特征金字塔网络[25]特征,以及ROI-Align pooling,这些对于需要空间精度的任务来说显得非常重要。我们将这种架构适应于我们的任务,以便在每个选定区域内获得密集的part labels和coordinates。
As shown in Fig. 7, we introduce a fully-convolutional network on top of ROI-pooling that is entirely devoted to these two tasks, generating a classification and a regression head that provide the part assignment and part coordinate predictions, as in DenseReg. For simplicity, we use the exact same architecture used in the keypoint branch of MaskRCNN, consisting of a stack of 8 alternating 3×3 fully convolutional and ReLU layers with 512 channels. At the top of this branch we have the same classification and regression losses as in the FCN baseline, but we now use a supervision signal that is cropped within the proposed region.
如图7所示,我们在完全致力于这两项任务的ROI-pooling中引入一个完全卷积网络,生成一个classification和一个egression head,用于提供part assignment和part coordinates predictions,如DenseReg。为简单起见,我们使用与MaskRCNN的关键点分支完全相同的体系结构,由8个交替的3×3完全卷积和512个通道的ReLU层组成。在这个分支的顶部,我们有与FCN baseline 相同的分类和回归损失,但我们现在使用在proposed region内裁剪的监督信号。
3.3. Multi-task cascaded architectures
Inspired by the success of recent pose estimation models based on iterative refinement [45, 30] we experiment with cascaded architectures. Cascading can improve performance both by providing context to the following stages, and also through the benefits of deep supervision [24].
3.3 Multi-task cascaded体系结构
受近期基于迭代细化的姿态估计模型的成功启发[45,30],我们试验了cascading架构。通过为以下阶段提供背景,并通过深度监督的好处,cascading可以提高性能[24]。
During inference, our system operates at 25fps on 320x240 images and 4-5fps on 800x1100 images using a GTX1080 graphics card.
在推断过程中,我们的系统使用GTX1080图形卡以320x240的图像以25fps的速度运行,800x1100的图像以4-5fps的速度运行。
As shown in Fig. 8, we do not confine ourselves to cascading within a single task, but also exploit information from related tasks, such as keypoint estimation and instance segmentation, which have successfully been addressed by the Mask-RCNN architecture [15]. This allows us to exploit task synergies and the complementary merits of different sources of supervision.
如图8所示,我们不局限于在单个任务中cascading,而是利用来自相关任务的信息,如keypoint estimation 和instance segmentation,这些已经由Mask-RCNN架构成功解决[15]。这使我们能够利用任务协同作用和不同监督来源的互补优势。
3.4. Distillation-based ground-truth interpolation
Even though we aim at dense pose estimation at test time, in every training sample we annotate only a sparse subset of the pixels, approximately 100-150 per human. This does not necessarily pose a problem during training, since we can make our classification/regression losses oblivious to points where the ground-truth correspondence was not collected, simply by not including them in the summation over the per-pixel losses [39]. However, we have observed that we obtain substantially better results by “inpainting” the values of the supervision signal on positions that were not originally annotated. For this we adopt a learning-based approach where we firstly train a “teacher” network (depicted in Fig. 9) to reconstruct the ground-truth values wherever these are observed, and then deploy it on the full image domain, yielding a dense supervision signal. In particular, we only keep the network’s predictions on areas that are labelled as foreground, as indicated by the part masks collected by humans, in order to ignore network errors on background regions.
3.4 Distillation-based的ground truth插值
尽管我们的目标是在测试时进行密集的姿态估计,但在每个训练样本中,我们仅注释pixel的稀疏子集,大约每个人100-150个。这在训练过程中并不一定会造成问题,因为我们可以使得我们的分类/回归损失忽略了不收集 ground-truth对应点的点,只需将它们不包含在每pixel点损失的总和中[39]。但是,我们注意到,通过对监督信号的数值“inpainting”原本未注释的位置,我们获得了实质上更好的结果。为此,我们采用了一种基于学习的方法,首先训练一个“teacher”网络(如图9所示),在观察到的地方重建ground truth值,然后将其部署在全图像域上,产生密集的监督信号。特别是,我们只保留网络对标记为前景的区域的预测,如人类收集的部分蒙版所示,以便忽略背景区域上的网络错误。
In this work we have tackled the task of dense human pose estimation using discriminative trained models. We have introduced COCO-DensePose, a large-scale dataset of ground-truth image-surface correspondences and developed novel architectures that allow us to recover highly-accurate dense correspondences between images and the body surface in multiple frames per second. We anticipate that this will pave the way both for downstream tasks in augmented reality or graphics, but also help us tackle the general problem of associating images with semantic 3D object representations.
在这项工作中,我们使用区分训练模型来解决密集人体姿态估计的任务。我们已经引入了COCO-DensePose,一个大规模的ground truth image-surface correspondences 数据集,并开发了新颖的架构,使我们能够以每秒多帧的速度恢复图像和身体表面之间高度准确的密集对应关系。我们预计这将为增强现实或图形中的下游任务铺平道路,同时也帮助我们解决将图像与语义3D物体表示相关联的一般问题。
Figure 7: DensePose-RCNN architecture: we use a cascade of region proposal generation and feature pooling, followed by a fully-convolutional network that densely predicts discrete part labels and continuous surface coordinates.
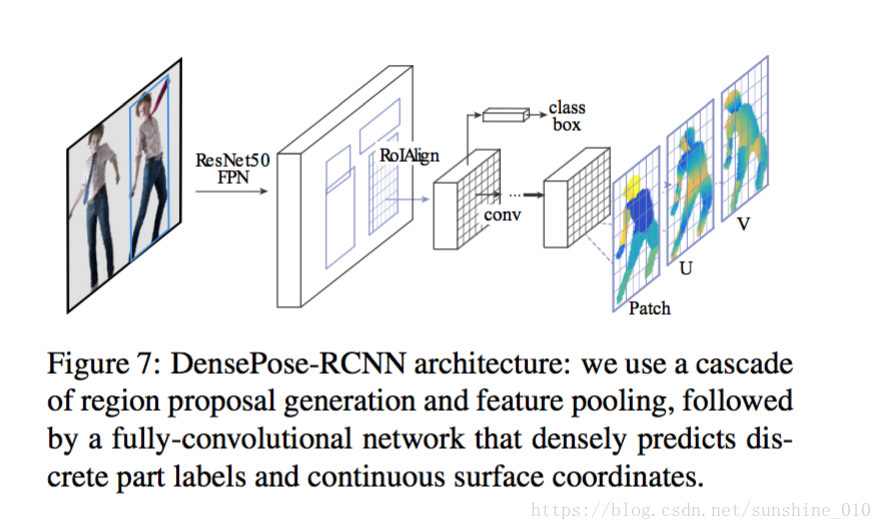
图7:DensePose-RCNN架构:我们使用cascade of region proposal generation 和 feature pooling,紧接着是一个完全卷积网络,它密集地预测discrete part labels 和 continuous surface coordinates。
Figure 8: Cross-cascading architecture: The output of the RoIAlign module in Fig. 7 feeds into the DensePose network as well as auxiliary networks for other tasks (masks, keypoints). Once first-stage predictions are obtained from all tasks, they are combined and then fed into a second-stage refinement unit of each branch.
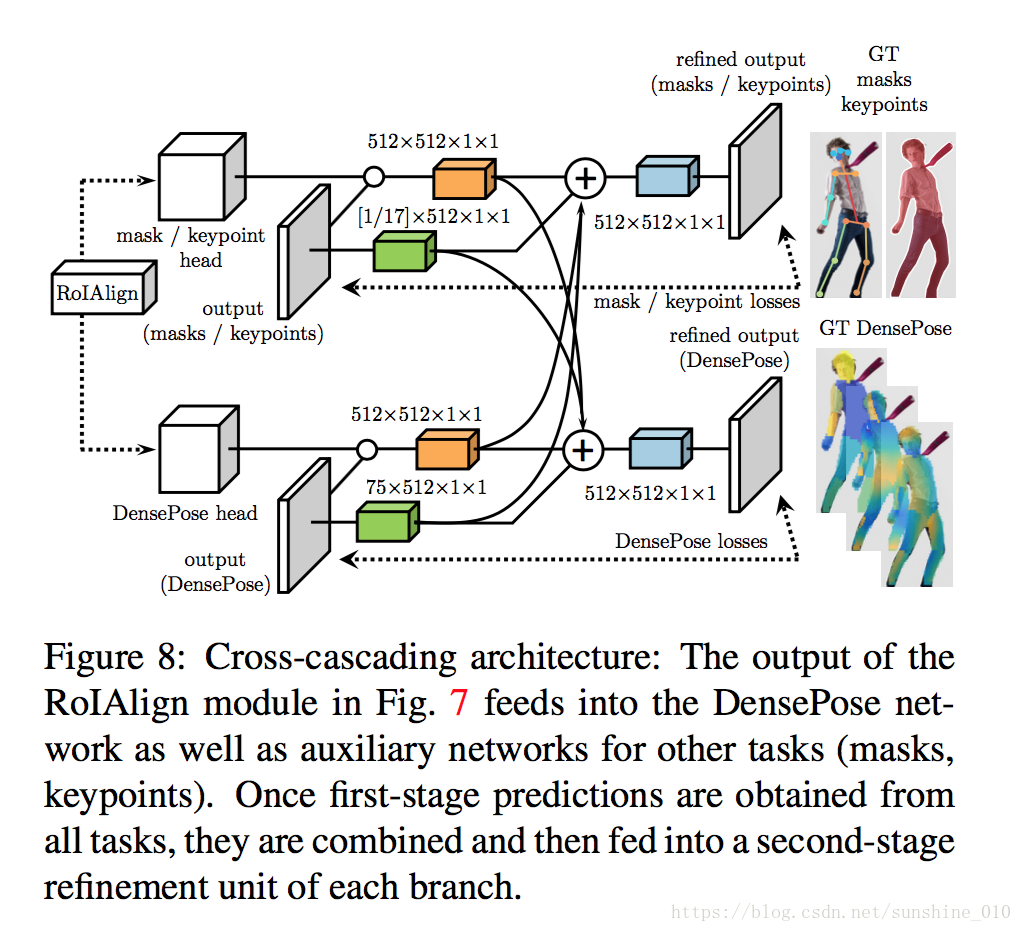
图8:Cross-cascading架构:图7中RoIAlign模块的输出馈入DensePose network以及其他任务(masks,keypoints)的辅助网络。一旦从所有任务中获得first-stage预测,就将它们合并,然后送入每个分支的second-stage 的refinement unit。