参考资料:How to Discount Deep Reinforcement Learning: ...
为帮助跟我一样的小白,如果有大神看到错误,还请您指出,谢谢~
知乎同名:uuummmmiiii
创新点:相比于原始DQN不固定折扣因子(discount factor,γ),学习率(learning rate,α)
改进:变化discount factor 和 learning rate
改进原因:原始的DQN,即用NN代替Q表“存储”Q值,会出现系统不稳定的情况(应该是涉及到强化学习中状态之间有相关性,而NN中假设的输入都是独立同分布的问题)
带来益处:加快学习算法收敛,提高系统稳定性
Abstract
在强化学习中采用深度网络做函数估计已经取得了很大的进展(DQN),在DQN这个基准之上进行改进,本文阐述了discount factor在DQN的学习过程中起到的作用,当diacount factor在训练过程中逐渐增长到它的最终值,我们实力验证了这样可以减少learning step,即加快收敛。如果再伴随着learning rate的变化(减少),可以增加系统稳定性,表现在后面验证中,可以降低过拟合。我们的算法容易陷入局部最优,采用actor-critic算法增加exploration,防止陷入僵局和无法发现some parts of the state space.
Introduction
在强化学习中,深度神经网络可以代替Q表,解决状态空间大使得内存不足的问题,但缺点是用NN会产生不稳定(Q值震荡或者发散)。
本文的研究动机取决于:棉花糖实验(marshmallow),孩子们更倾向于等待更长时间换取更多的奖励。
本文结构:首先回顾DQN中的一些equation;探索discount factor的作用;再加入learning rate进行实验。
Instabilities of the online neural fitted Q-learning
discount factor作用与在机器学习中权衡bias-variance相似,discount factor 控制了策略复杂性的程度
Experiments
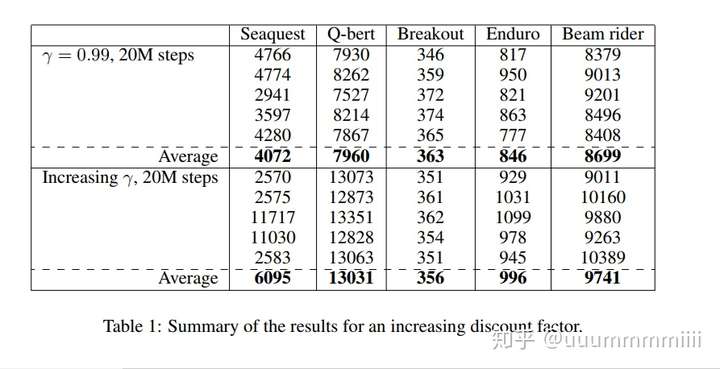
discount factor变化: =1-0.98(1-
)
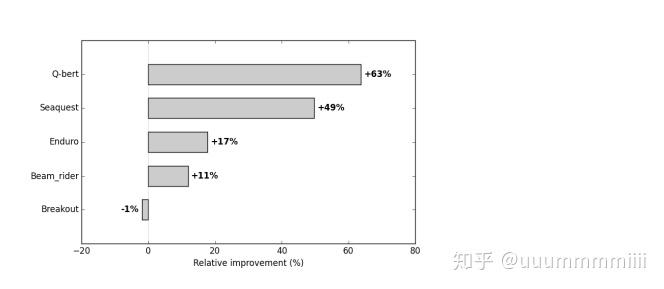 γ增加,有四个游戏算法学习更快
γ增加,有四个游戏算法学习更快
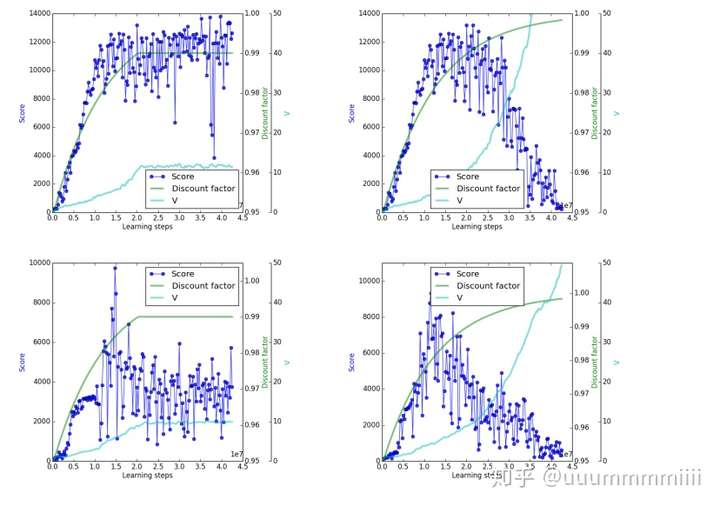 上面两图为第一个游戏,下面两图第二个游戏;左边两图γ都逐渐增加到0.99后不变,右边两图逐渐增加到接近1,可发现实际的scores较V值高很多,严重过拟合
上面两图为第一个游戏,下面两图第二个游戏;左边两图γ都逐渐增加到0.99后不变,右边两图逐渐增加到接近1,可发现实际的scores较V值高很多,严重过拟合
加入learning rate变化: =0.98
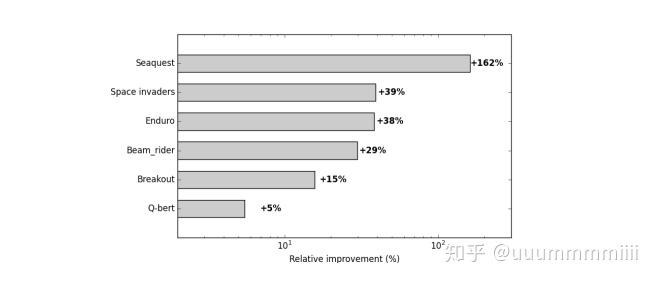
发现五个游戏均减少了learning step
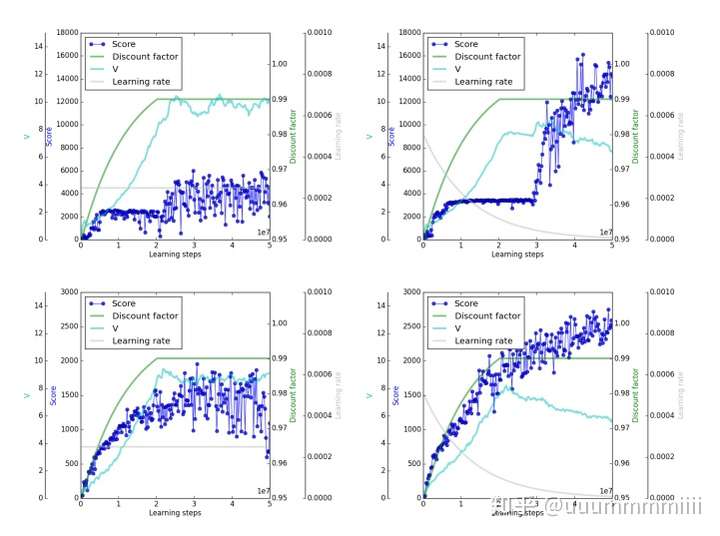 上面两个图表示第一个游戏,下面两图表示第二个游戏;γ均保持逐渐增加到0.99后不变,左边表示learning rate不变,右边两图表示learning rate逐渐减少
上面两个图表示第一个游戏,下面两图表示第二个游戏;γ均保持逐渐增加到0.99后不变,左边表示learning rate不变,右边两图表示learning rate逐渐减少
表示当discount factor保持逐渐增加到0.99后不变,逐渐减少learning rate,使得V值会降低,减少过拟合
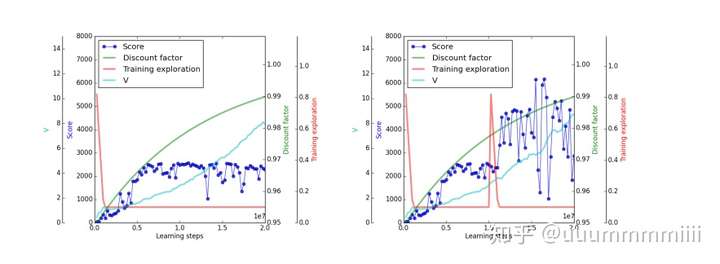 对于游戏seaquest,actor-critic算法可以跳出局部最优
对于游戏seaquest,actor-critic算法可以跳出局部最优