目录
Abstract
hand-eye coordination tasks 手眼协调任务
尽管有很有希望的结果,但使用图像的训练智能体是硬件密集型的,通常需要数以百万计的训练步骤来收敛,从而导致长时间的训练时间,并增加机器人的磨损风险。
In this paper, we propose training the vision system using supervised learning prior to training robotic actuation using Deep Deterministic Policy Gradient (DDPG).
在本文中,我们提出了先使用监督学习来训练视觉系统,然后再使用深度确定性策略梯度(DDPG)来训练机器人的驱动。
The vision system uses a software retina, based on the mammalian retino-cortical transform, to preprocess full-size images to compress image data while preserving the full field of view and high-frequency visual information around the fixation point prior to processing by a Deep Convolutional Neural Network (DCNN) to extract visual state information.
视觉系统使用软件视网膜,基于哺乳动物视网膜-皮质变换,对全尺寸图像进行预处理,压缩图像数据,同时保留全视场和注视点周围的高频视觉信息,然后通过深度卷积神经网络(DCNN)进行处理,提取视觉状态信息。
使用视觉系统对环境进行预处理,提高了智能体的样本复杂性和网络更新速度,从而显著加快了训练速度,减少了图像数据损失。
Our method is used to train a DRL system to control a real Baxter robot’s arm, processing full-size images captured by an in-wrist camera to locate an object on a table and centre the camera over it by actuating the robot arm.
我们的方法用于训练一个DRL系统来控制一个真正的Baxter机器人的手臂,处理由手腕内相机捕获的全尺寸图像,以定位桌子上的物体,并通过驱动机器人手臂将相机集中在其上方。
Keywords
- Software Retina Preprocessor
- Reinforcement Learning
- Robotic Vision
- CNN
1. INTRODUCTION
图像数据是一个智能体的高维状态空间,卷积层的包含进一步增加了需要学习的参数的数量。
缓解基于视觉的DRL任务难度的一种方法是通过裁剪和缩小输入图像来减少状态空间。
虽然这可以大大减少状态空间,但它以降低视场和降低图像质量为代价,限制了可以从图像处理中提取的潜在信息。
这项工作提出训练一个基于视网膜的视觉系统,从图像中提取状态信息,使用监督学习作为一种减少DRL学习问题的难度。
在Gazebo上用Baxter机械臂开发了一个训练环境,目标是将手臂中心放在桌子上的一个物体上。
深度确定性策略梯度(DDPG)用于成功地训练智能体预测终端位置运动,然后使用Inverse Kinematics(IK)进行。
使用不同的视觉系统对智能体进行训练,以评估使用预测对象位置的训练与从DCNN中去除预测层获得的不同大小的特征向量的影响。
2. BACKGROUND
A. Software Retina
The retina is a layer of different nerve cells at the back of the eye which turns light into neural impulses before sending them to the brain.
视网膜是眼睛后部的一层不同的神经细胞,在将它们送到大脑之前将光变成神经冲动。
Photoreceptor cells sample the retinal image most densely in the fovea of the eye, located around the fixation point, and are increasingly sparsely sample towards the periphery.
感光细胞采样视网膜图像最密集地位于眼睛中央凹,位于固定点周围,并且向周围越来越稀疏。
Ganglion cells are connected to the photoreceptor cells to combine their responses to provide data compression. In the fovea they have a very small receptive field, sometimes only connecting to one photoreceptor, whilst they are increasingly larger towards the periphery of the visual field.
神经节细胞与感光细胞连接,结合它们的反应来提供数据压缩。在视网膜中央凹,它们有一个非常小的感受野,有时只连接到一个光感受器,而它们在视野的外围则越来越大。
This creates a blurring effect whereby visual information is preserved at the fixation point and image information towards the periphery becomes progressively more blurred.
这就产生了一种模糊的效果,即视觉信息被保存在注视点上,而朝向边缘的图像信息则逐渐变得越来越模糊。
Balasuirya使用自我相似的神经网络来开发人工视网膜镶嵌。

Ozimek通过插值视网膜样本中的皮质图像,扩展了Balasuirya的工作,该图像可以直接使用传统的CNNs进行处理。
这种采样表现为一种“缩放效应”,使精细的人工协调技能,如穿针,同时也保持整个视野。
使用皮层图像训练神经网络提供更短的训练时间,这是因为他增加图像压缩,同时也提供一定程度的规模和旋转不变性,皮层空间类似于对数极空间,输入图像规模和旋转的影响是准正交的皮层图像轴。

B. Deep Reinforcement Learning Hand-Eye Coordination
Kalashnikov等人提出了 Q t − O p t Q_{t}-Opt Qt−Opt算法,该算法利用真实机器人抓取尝试离线策略学习,使用472x472像素图像训练大型 Q Q Q网络,并进行CEM优化,以找到具有最佳 Q Q Q值的动作。
然而,为了收集数据需要80万机器人工作时长,训练足够的Q函数需要5~15million步,然后使用离线策略和在线策略掌握进行进一步微调。
Pore等人提出通过在OpenAI的FetchPickandPlace环境中采用行为抓取方法来提高DRL的样本复杂性。
行为克隆通过专家演示来训练三种基本行为:方法、抓取和收缩,然后使用DRL来训练LSTM来编排行为,决定何时应该运行来成功抓取一个立方体。
我们的工作与Pore采用的基于行为的方法最密切相关,但使用了视网膜视觉系统,并专注于训练一种使用DRL而不是行为克隆的类似行为的方法。
3. METHODOLOGY
A. Simulator Details
Baxter机器人是在Gazebo内部建模的,这是一个强大的3D机器人模拟器,桌子上有一个蓝色的立方体,作为智能体中心化的目标。

The goal in the environment is to move the Baxter robot’s arm so that the object sits within the centre of the field of view of its in-wrist camera.
在环境中的目标是移动Baxter机器人的手臂,使该物体位于其手腕内摄像头的视野中心。
神经生物学表明,在执行手眼协调任务时,在进行运动控制之前,人类首先注视关键位置。
| reward | meaning |
|---|---|
| the negative reward | The further away an object is from the visual field centre, the larger the negative reward. |
| 0 | the agent centred on the object perfectly in a single movement. |
Originally, a larger negative reward was returned to discourage the agent from losing sight, but this was found to be very difficult to tune because too large a value seemed to destabilise the Q estimates, preventing learning. On the other hand, an insufficiently low reward made losing sight of the object too rewarding compared to exploring the environment and amassing negative rewards.
最初,会返回一个较大的负奖励,以阻止智能体失明,但这很难调整,因为太大的值似乎会破坏Q估计值的稳定性,妨碍学习。另一方面,与探索环境和积累负面回报相比,报酬过低会使看不见物体的人获得太多的回报。
环境和系统状态观测包括腕内摄像机拍摄的最新图像以及腕内端点的当前x和y坐标。有必要包括x和y坐标,以便智能体能够了解其可达区域的范围。
如果没有这一步,智能体将无法知道一个动作是否可以执行,因此不能预测奖励价值,这将阻止批评者学习。
不幸的是,这也在观察中引入了噪声成分,因为手臂移动如此之快,每次运动完成后手腕会表现出欠阻尼的残余振荡。
B. Vision System Details
基于成功的ResNet体系结构ResNet64,实现并研究了两种不同的ResNet128,它们分别输出64和128维特征向量。
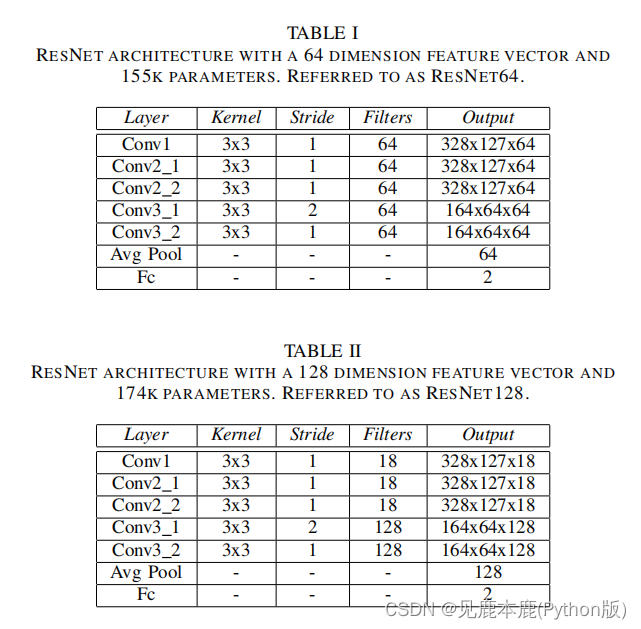
为了训练ResNet64和ResNet128体系结构,使用了带有动量的SGD优化算法。之所以选择动量SGD而非Adam,是因为它倾向于更好地泛化,从而以更高的训练损失为代价降低验证损失,并用于成功训练ResNet,以在ImageNet数据集上获得最先进的结果。
| hyper parameter | learning rate starts | optimization algorithm | decay factor | SGD momentum | weight decay | batch size |
|---|---|---|---|---|---|---|
| value | 0.01 | SGD | 10 | 0.9 | 1e-5 | 32 |
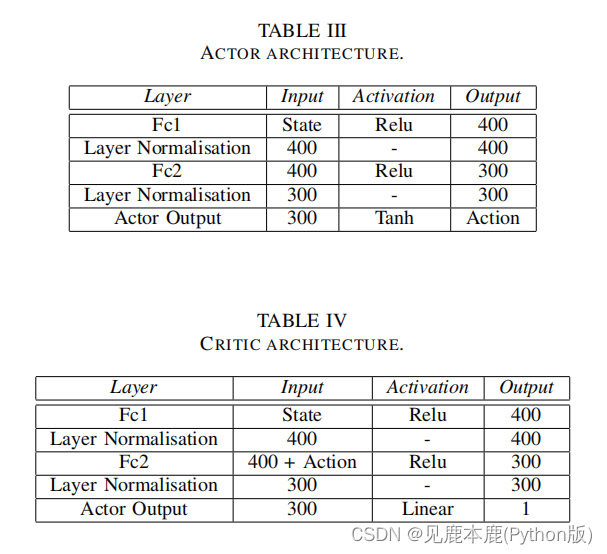
C. Agent Details
该状态在被网络处理之前,通过保持对每个状态维度的平均值和标准差的滚动估计来进行标准化,以帮助学习。
| Items | optimisation algorithm | actor | critic | L2 decay | the soft network updates | the discount factor | Additive action noise | exploration-exploitation trade-off | the experience replay | the episode number |
|---|---|---|---|---|---|---|---|---|---|---|
| Values | Adam | 0.0001 | 0.001 | 0.01 | 0.001 | 0.99 | a mean of 0 0 0 and a standard deviation of 0.2 0.2 0.2 | 1.0 1.0 1.0 to reducing to 0.02 0.02 0.02 | 2 k k k | 20 |
4. EVALUATION
A. Training on Environment Dynamics
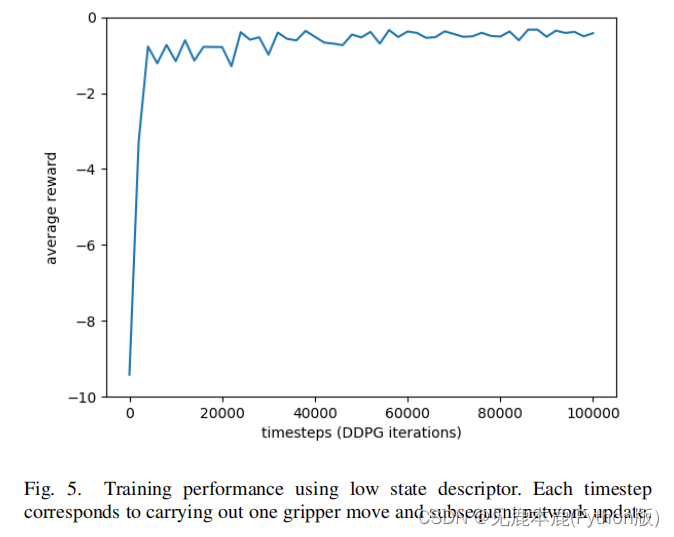
为了验证模拟的环境设计并提供一个基线性能度量,研究人员使用通过颜色阈值识别的立方体的中心位置对一个DDPG智能体进行了训练。
经过100k步长的训练,大约需要24小时,智能体能够准确地集中在一两个动作中。
然后估计并执行一个较小的动作,以细化相机相对于立方体中心的位置。
据观察,特工继续采取非常小的行动,以更准确地尝试中心。
然而,这些剩余位置细化不能执行,因为关节有一个精度公差,防止任何更新其角度低于这个公差限制。
B. Running Agent using Retina ResNet instead of Dynamics
在这个项目中,经过训练的两个ResNets以非常高的精度预测环境的动态。这在更现实的环境中不太可能是正确的,因为它们要复杂得多,包含许多在训练中从未见过的物体以及各种噪声源。
这允许智能体理解在最佳情况下如何利用这些信息来执行任务,而不需要使用不正确的信息来破坏智能体对问题动态的理解。
这提供了两个主要的学习任务的明确分离:如何使用视觉信息来执行任务,以及如何提取对视觉信息的准确估计。
为了评估智能体在使用ResNet预测中心位置而不是颜色阈值时的有效性,我们在5个时间步长中对超过100次片段的智能体的性能进行了评估。
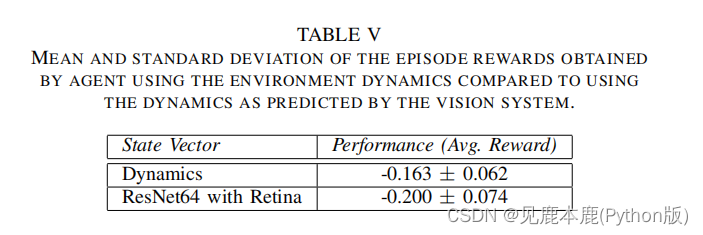
表5显示,在软件Retina上使用ResNet会产生轻微的性能影响,但从检查来看,这是由于智能体有时需要额外的移动,而不是不太准确。
怀疑这是由于ResNet的某些预测在某些特定情况下有点不准确。
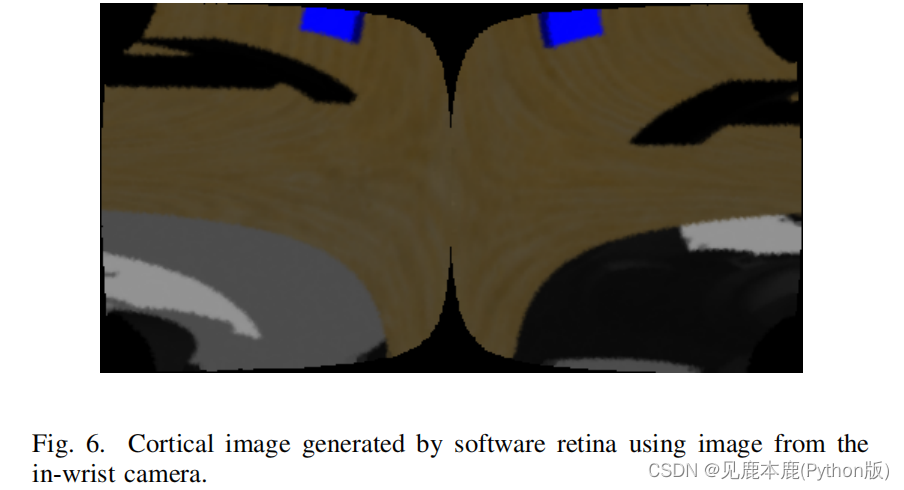

图7显示了在图6中使用皮质图像预测的位置,略接近相机的中心,因为部分立方体在皮质图像中不可见,如图7所示。
为了补偿初始预测的不准确性,当立方体靠近视网膜中央凹产生更准确的预测后,智能体采取额外的行动来更好地使立方体在中心。
C. Training Agent using Retina Features
在使用软件Retina成功地训练了两种ResNet架构之后,本节将探讨DDPG智能体使用图像特征的学习能力。
To ensure that the training results are fair, all seeds for the random generators were set to the same value so that exploration noise, cube spawning locations and weight initialisation were the same for each agent.
保证公平性——随机数种子都一样
智能体没有被赋予对象的确切中心位置,而是被赋予视觉特征,它必须使用这些特征来发展自己的理解对象的位置,以及它如何受到不同动作的影响。

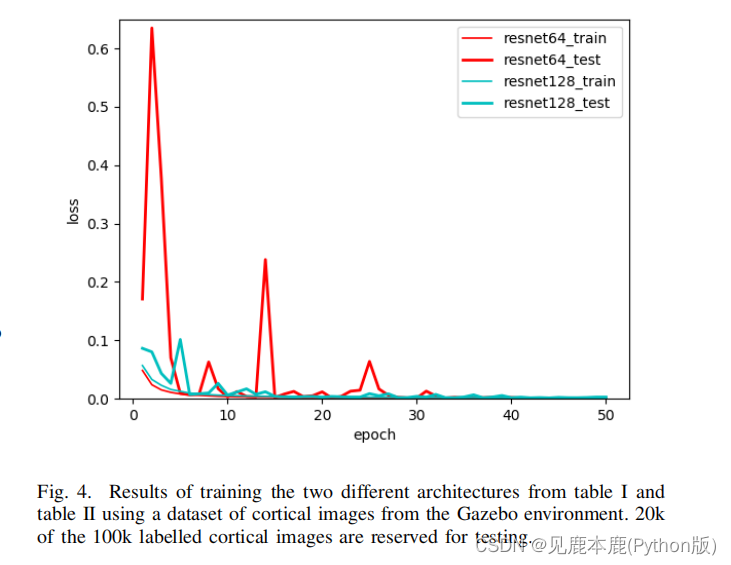
图8显示了使用ResNet64状态、ResNet128状态和低状态的DDPG智能体的相对训练性能。
尽管在50k时间步后,低状态智能体的性能始终优于其他智能体,但差异非常小,ResNet64和ResNet128智能体也学习成功的策略。
怀疑使用更大的状态维度,智能体需要更长的时间来学习,但在实践中,这些结果显示ResNet64和ResNet128智能体之间的差异很小。
为此,这些结果表明,智能体可以使用在任务相关数据集上训练的Retina视觉系统提取的更大的特征向量进行学习,而不会极大地影响训练性能。
环境图像由视觉系统进行处理,在智能体的经验回放中只存储状态,与端到端学习相比,大大提高了离线策略采样的速度,并补偿了视觉系统增加的处理时间。
D. Training using Dynamics or Image Features
选择是否使用视网膜视觉系统所预测的动态或图像特征来训练智能体是一个权衡的问题。
当使用动态模型时,与使用图像特征相比,当出现错误时,系统更容易负责任。可以清楚地看到,问题是由于视觉系统错误导致智能体使用的信息错误,还是信息正确,但智能体误解了如何使用它。
然而,使用动力学是限制性的,可能并不总是适用于手头的问题。也许在动态中没有包含一些对智能体的性能有益或至关重要的信息。
通过使用图像特征进行训练,智能体可以自己提取这些信息,或者学习一种比动态更好的完全不同的环境理解。
如果已知一些信息有助于解决部分问题,则可以使用动态和图像特征的混合来给智能体一些更高级别的知识,以帮助学习,而图像特征可以用来学习新的信息。
5. DEMONSTRATION ON THE REAL ROBOT
为了将视觉系统从模拟转移到现实世界,我们尝试冻结初始卷积层,以微调最终的连接层。
在这里,我们发现,由于图片的极端差异,在之前训练过的网络中只传递少量的真实世界数据,会导致严重的过拟合。
为了解决这个问题,我们将收集到的真实世界图像的数量从3200张增加到30000张,并且只使用了用于模拟训练的图像切片。在现实世界中的训练和通过模拟器进行的训练之间有明显的相似性,波动被认为是由两个世界的现实差距造成的。
研究发现,这些权重虽然在训练中提供了提升——通过聚焦于靠近物体——但由于两种环境的差异,它们在现实世界场景中并不是最优的。因此,重新运行训练,使用一个对象位置微调权重,然后使用多个立方体位置进行训练。
尽管训练智能体使用一个立方体作为一个对象,同时允许视觉系统使用完整的RGB颜色空间,但智能体已经显示出了有趣的行为,比如泛化跟踪任何对象。当呈现出两个对象,大致集中在两个对象的中间时,智能体会经历一些混乱。智能体也展示了对象跟踪能力,但被视觉组件的瓶颈,因为CNN处理图像需要大约一秒的时间。
6. FUTURE WORK
A. Transfer Learning
A more challenging problem would be training using large and more diverse datasets designed for different problems, e.g., motion and depth perception, object localisation etc.
继续增加模型的泛化性能——减小模型在不同场合下的训练难度
虽然在这个项目中使用特征向量大小128而不是64似乎没有很大影响训练,这可能是由于特征向量专门化环境和一个更大的状态空间,与任务无关的信息可能会降低样本的复杂性和训练时间。
B. Add Residual Block to Agent
虽然池化层对于筛选智能体需要学习的状态维度很有用,但它也可能会丢失重要的视觉信息,这将有利于训练智能体的最终性能。在智能体的开始处添加一个剩余块将允许智能体利用完整的视觉信息,同时也允许它学习特定于其当前环境的更高层次的特性。
使用剩余的跳过连接可以允许代理决定它在多大程度上使用了卷积层,而不是重用这些特性。