Playing Atari with Deep Reinforcement Learning
比较尴尬,上篇文章不是DQN的来源,这篇才是。上篇Nature文章对于DQN做出的改进上次没读明白,查看其他资料,做实践的时候才明白。关于Nature的改进下面会提到。
基本信息
作者:VolodymyrMnih KorayKavukcuoglu DavidSilver AlexGraves IoannisAntonoglou DaanWierstra MartinRiedmiller
来源:NIPS 2013
机构:DeepMind
论文摘要
我们提出了第一个可以从高维输入中直接学习到控制策略的深度学习模型。这是一个卷积神经网络,基于Q-learning进行训练,它的输入就是像素点,输出是一个可以预估未来奖励的值函数。我们使用同样的算法和网络结构去学习Atari 2600的游戏,我们发现在6个游戏上它超过了之前所有的方法并在三个游戏上超过了人类专家。
论文背景目的和思想
关于背景和目的,其实在上篇博文论文笔记:Human-level control through deep reinforcement learning中说的已经差不多了。强化学习Q-learning很好使,但是它不适宜处理高维数据,奖励函数需要人为的去设定,因此,很自然的我们就想到,是不是可以用神经网络去拟合一个奖励函数(当然,这个过程用遇到了无数的困难)。通过这种方式,我们就可以构建一个比较通用的模型去处理不同的问题,就比如在本文中,各种游戏都可以玩,模型都能很好的学习到控制策略,甚至连超参数都不需要改。通过这种方式,我们希望可以解决Q-learning的通用性的问题。
这个的实现肯定不是一帆风顺的,遇到的问题在上篇文章中也提到了。
1、DL需要大量带标签的样本进行监督学习;RL只有reward返回值,而且伴随着噪声,延迟(过了几十毫秒才返回),稀疏(很多State的reward是0)等问题;
2、DL的样本独立;RL前后state状态相关;
3、DL目标分布固定;RL的分布一直变化,比如你玩一个游戏,一个关卡和下一个关卡的状态分布是不同的,所以训练好了前一个关卡,下一个关卡又要重新训练;
4、过往的研究表明,使用非线性网络表示值函数时出现不稳定等问题。
1、通过Q-Learning使用reward来构造标签(对应问题1)
2、通过experience replay(经验池)的方法来解决相关性及非静态分布问题(对应问题2、3)
另外就是通过一个神经网络产生当前Q值,使用另外一个神经网络产生Target Q值的方法来解决问题4。在这里我把nature的原文摘录以下,之前读的时候没注意,太简略了。

引入target_net后,再一段时间里目标Q值使保持不变的,一定程度降低了当前Q值和目标Q值的相关性,提高了算法稳定性。
相关工作
这篇博文的内容实在是太少了,介绍以下related work,感受以下这方面的发展成果和脉络。
TD-gammon是在此之前最出名的强化学习相关的方法,TD-gammon使用了类似于Q-learning的算法,用多层感知机来逼近value function,这种方法在西洋双陆棋上仅仅通过自对弈就取的到远远超过其他算法和人类的水平。受这个成果的激励,TD-gammon被用在其他的问题上,比如其他棋类,或者是玩游戏。但是效果都不大理想,这可能是因为在掷色子的过程中,掷色子的随机性帮助算法探索状态空间,同时使得值函数变得更加稳定。
后来,使用非线性函数的Q-learning算法在实践中被发现无法收敛。线性函数比非线性函数有更好的收敛性。
再到后来,大家开始尝试将深度学习和强化学习相结合,提出了具体的模型,并且针对非线性不收敛的问题提出了解决方法,比如 gradient temporal-difference,但是这些方法没有扩展到nonlinear control。
方法描述
NIPS的文章写的就详细多了。
Q-learning的基本公式:
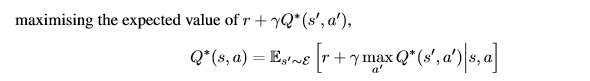
对于一个神经网络,要想迭代,就要有损失函数。这里的损失函数是希望奖励函数的预估在迭代中尽可能的变得稳定。


算法里面涉及到经验回访的内容在上个博文中已经重点讲了。
实验结果
作者测试了七个游戏,输入就是像素值,和分数,输出就是控制策略。七个游戏都保持了同样的网络,但是作者做了一个小小的改变,就是这些游戏的计分方式是不同的,作者统一把正奖励定位+1,负奖励定位-1,不变就是0,这样子同样的网络和参数就能得到稳定的结果。

从表格中我们可以看到,DQN超过了其他的各种算法,但是我们同样要看到,在大多数游戏中,DQN与人类依然有很大的差距。
另外还有一个显著的问题就是得分在迭代过程中十分不稳定(虽然效果还是不错)。另外,Atari上一共可以找出47种游戏,在nature那篇文章中DQN是全面超过了过去所有的方法,但是在这篇文章中只列举了7种,是不是代表其他的游戏用目前的方法不行呢?

总结
这样把DQN的来源给补齐了,思想上上篇文章都说了,说一下感慨。2013年的这篇文章是DQN的原型,当时的效果还不是特别好,说这个模型会玩游戏应该是比较勉强的,实在是太不稳定了。直到2015年,又提出这个网络的参数不一定要次次迭代,保留一个旧的参数带入损失函数,过一段实践之后再把新参数复制回去,这样子模型的稳定性会好很多。我能理解这样做可以继续减少参数的相关性,但至于为什么减少相关性之后收敛的就更好了,还是很难理解。再后来,就有了2016年大战李世石的阿尔法狗,再后来就是战胜柯洁的Zero版本。到现在,大家在研究怎么用它来打星际争霸,王者荣耀,里面看来还是有太多太多没有解决的问题,这个可能要自己亲自处理问题才能体会到。
下面做一些小小的实践补充以下经验吧,都是网上可以找得到的教程和实战。
https://github.com/caozixuan/RL_Learning
参考:实战强化学习DQN
