目录
Abstract
任务:在杂乱的场景中拾起物体
设计了一种由吸盘和夹具组成的复合机械手,可以稳定地抓取物体。吸盘用于首先从杂物中抬起物体,夹持器用于相应地抓取物体。
利用可见性图(affordance map)为吸盘提供像素级的吸取候选点。为了获得良好的观测图,在系统中引入了主动探索机制。
设计了一种有效的度量方法来计算当前可见性图的奖励,并采用深度Q网络(DQN)引导机械手积极探索环境,直到生成的可见性图适合抓取。
I. INTRODUCTION
带吸盘的机械手非常流行,广泛应用于机器人抓握任务。这是因为吸盘通常结构简单,对许多不同的物体都很坚固。自密封吸盘阵列来大大提高机器人在不确定环境下的抓取能力。
然而,吸盘的工作机制对物体的表面和姿势施加了许多限制。
另外,吸盘的移动方向与力方向之间的不一致使得抓握不稳定并且导致吸盘的工作寿命短。
Zeng提出了通过对整个场景的分析,使用视觉图/可见性图来表示抓取点,大大提高了机器人抓取的精度。
可见性图是一个显示输入图像中每个像素的置信率的图。
然而,由于环境通常是复杂的和非结构化的,有时机器人在视觉图上显示的抓取位置很难掌握。通过积极地探索环境,机器人能够对环境进行一些改变,直到它适合抓取。
当场景中的物体距离太近而不能抓取时,机器人可以主动探索环境,改变物体的位置,直到适合抓取为止。同样地,机器人也可以通过将物体分开来重新排列,来改变它们的位置。

II. RELATED WORK
本文创新点:
- 设计了一个新型的复合机械臂,包括了吸盘和夹持器。
- 为了获得一个更好的可见性图,设计了一个基于DQN的积极探索算法。
- 复合机械臂和积极探索算法相结合,获得了很好的性能表现。
| Work | Content | Ad/Disad-vantage |
|---|---|---|
| a multifunctional gripper with a retractable mechanism | (1) Switch between suction mode and grasping mode quickly and automatically. (2) Provide a hardware basis for implementing different grasp strategies | doesn’t consider the coupling between the two modes |
| the Suction Pinching Hand | two underactuated fingers and one extendable and foldable finger whose fingertip has a suction cup mounted on it. (两个动作不足的手指和一个可伸缩和可折叠的手指,其指尖上有一个吸盘) | It can grasp various objects stably by using both the suction and pinching at the same time. |
作者设计的机械臂:
- It has a suction mode and a grasping mode, which can be coupled to work simultaneously and also work separately.(实现了吸盘模式和抓取模式的耦合)
- The proposed composite robotic hand is able to close its two fingers to push objects in order to actively explore the environment.(可以将手指合并,实现推的基本动作)
III. SYSTEM OVERVIEW
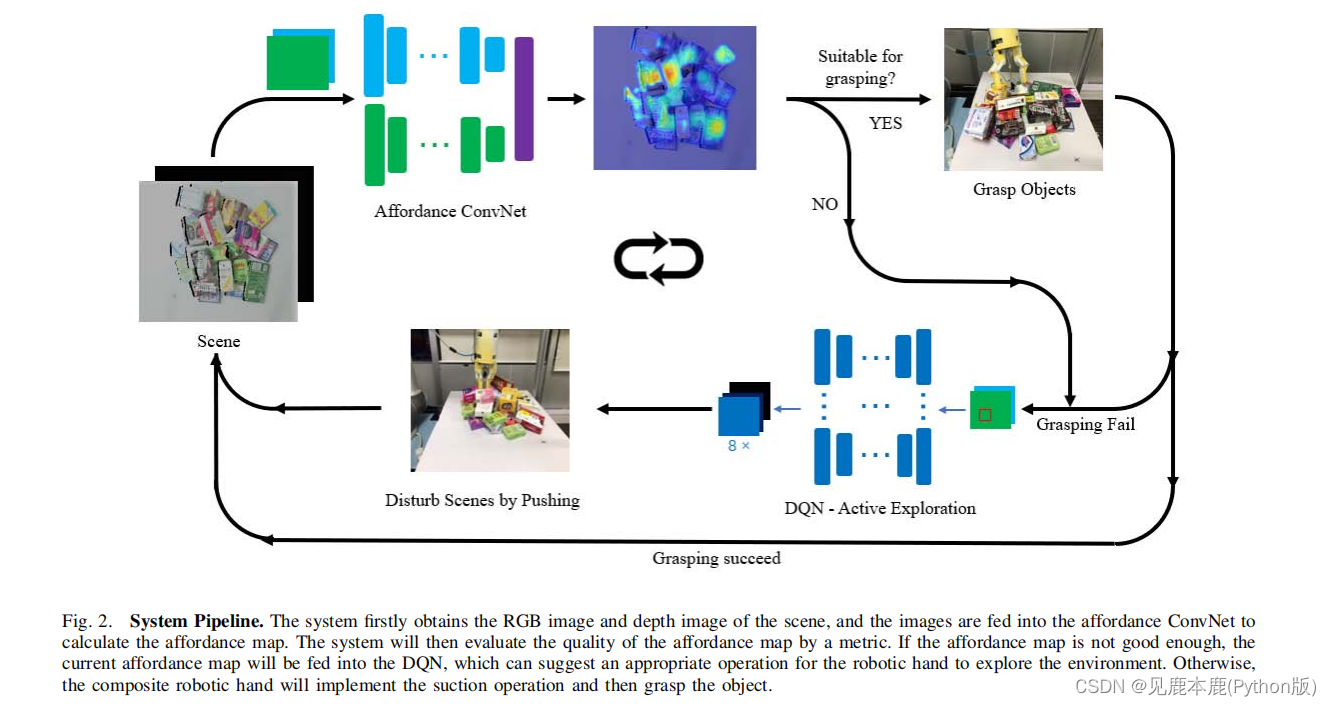
- 获得该场景的RGB图像和深度图像。
- 使用ConvNet获得基于输入图像的计算视觉图。
- 提出了一种度量 Φ Φ Φ来评估当前提供图的质量。
- 如果Φ高于一定的阈值,复合机械手将用吸盘进行吸力操作,然后据此抓取物体。
- 否则,可见性图将被输入DQN,DQN引导复合机械手通过推动前面的物体对环境造成一些干扰。
- 此过程将被迭代,直到成功拾取环境中的所有对象。
IV. ARCHITECTURE
A. Robotic Hand Structure

复合机械手由两个平行的手指和一个吸盘组成。
这两个手指对称地分布在底座上。每个手指都有一个马达驱动的平行四边形机制,它确保了当手指抓取物体时,两个手指的表面总是平行的。
吸盘系统由一个吸盘、一个推杆、一个气缸、两个气泵、一个微型电机和一个电磁阀组成。吸盘放在两个手指的中间。在复合材料机械手的内外分别配备了两个气泵。内部的一个和微型电机用于控制吸盘,而外部的一个与电磁阀驱动与75毫米范围的推杆。
B. Grasp Process
- 机械手移动到提升点,当到达提升点时,吸盘将被弹出,以接近物体的表面。
- 空气泵在吸盘中产生负压,从而使物体被提升。
- 推杆缩回,在两个手指之间抓住物体。
- 将手指闭合,以确保抓握的稳定性。
- 该对象将被释放。
- 释放物体的过程与吸力的过程相反。
C. Characteristics of Grasp Process
当机械手移动时,手指和吸盘施加的力可以协调起来,保证物体被稳定地抓住。
实验证明,复合机械手能够有效、稳定地抓取不同大小和形状的物体。

V. DEEP Q-NETWORK STRUCTURE
A. Affordance Map
它解决了传统抓取策略中要求在抓取前先识别物体的问题。
然而,不可避免的是,有时很难从所获得的可见性图中区分出较好的抓取点,特别是在场景比较复杂的情况下。
1) Affordance ConvNet
Affordance ConvNet是一个以RGB和深度图像为输入和输出视觉图像的网络,这是一个密集的值从0到1的像素级热图。数值越接近1,提升位置就越好。
为了训练的目的,我们手动标记场景图像,其中适合抓取的区域被标注。
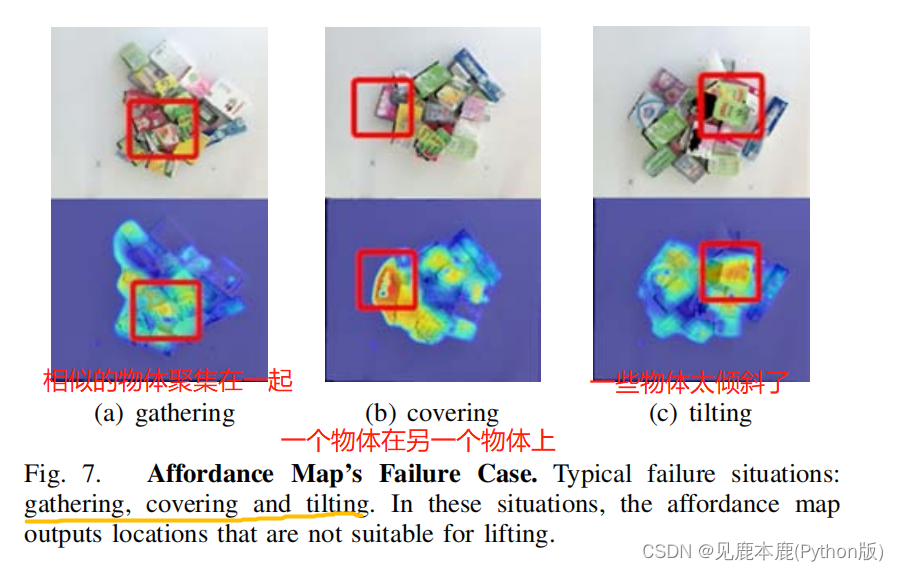
2) Failure cases
- 当高度或颜色相似的物体彼此接近时,很可能被视为一个单一的物体。
- 当两个对象部分重叠时,这两个对象可以被视为一个对象。
- 当物体的姿势过度倾斜时,可能不适合实际操作。
B. Active Exploration
网络结构基于U-Net,表示像素级的动作。
U-Net是最近提出的一种强大的轻量级网络结构,包括下采样和上采样。它在生成像素级语义信息方面具有良好的性能。
为了由于速度的原因而最小化网络的大小,我们将这个结构调整为一个更小的结构,使用一个下采样和上采样,并将RGBD图像的大小调整为四分之一的分辨率。

1) Local patch
因此,我们在网络中提出了一种局部补丁的UNet结构,它可以以更少的步数获得更好的场景,并最小化模型大小,以加快计算速度。
Assuming that in the current state, p M p_{M} pM is the most promising picking point with the highest confidence score in the affordance map ( p M = arg max { I a f f } p_{M} = \argmax \{I_{aff} \} pM=argmax{ Iaff}). We crop(收集) the input RGBD image around this corresponding pixel with a size of ( 128 × 128 ) (128 × 128) (128×128) and downsample(下采样) it to a size of ( 32 × 32 ) (32 × 32) (32×32) ( 32 = 128 ÷ 4 ) (32 = 128 \div 4) (32=128÷4) before feeding it into our U-Net based network, which greatly reduces the model size.
2) Paralleled tiny U-Net
U-Net能够指示给定图像输入的像素级操作。对于每个动作,它都会在每个位置上输出一个置信度分数。
在本工作中定义了8个具体的动作。机器人可以从8个方向推动物体。
我们使用 O i = i × 45 ° ( i = 0 , . . . , 7 ) O_{i}=i \times 45 \degree (i=0,...,7) Oi=i×45°(i=0,...,7)来表示方向,推距离是局部补丁大小的一半。
整个网络包含了8个结构相同的U-Net模块。
U-Net被裁剪为一个很小的一个,只下采样和上采样一次。它对于我们的输入足够好,适合于具有亚像素级操作位置的场景。这样,DQN的动作空间就会减少,以获得更快的学习速度。
C. The metric of affordance map
设计了一种新的度量 Φ Φ Φ来计算当前提供图的奖励,这对于评估从DQN中获得的每个动作都很有用。
1) Flatness punishment based on Gaussian distribution
最大可见度值出现在有积累或倾斜的区域周围,而在该区域周围的可见度值的分布往往是有方向性的。
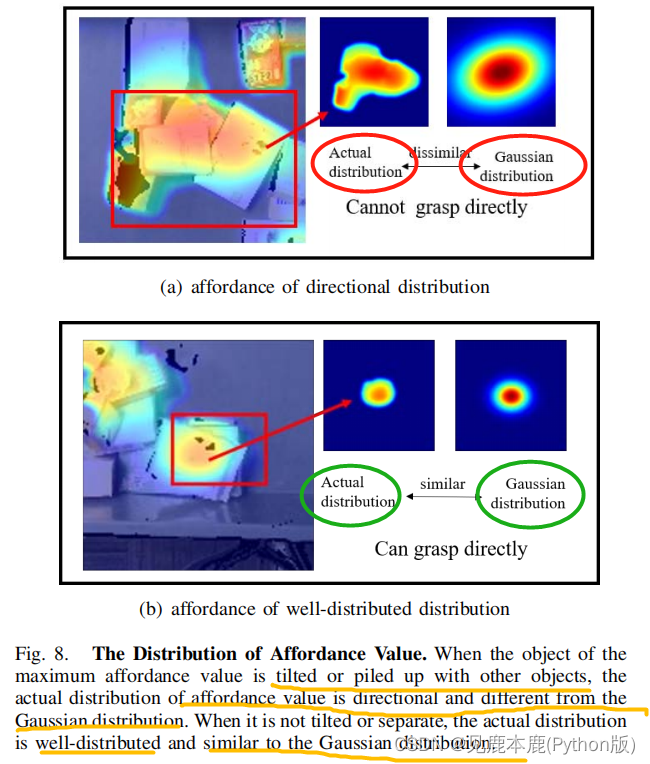
检测某一可见点是否是最优的可见点:
- 抽取实际场景中可见值最大的点
- 生成以这个点为中心的分布,抽取一些列的点,对应位置的值设置为 s i j s_{ij} sij
- 同样以这个点为中心生成高斯分布,同样抽取一些点,对应位置的值为 s i j ∗ s^{\ast}_{ij} sij∗
- 设置两个评估指标 e i j e_{ij} eij和 σ \sigma σ
- e i j = s i j ∗ − s i j v M e_{ij} = \frac{s^{\ast}_{ij}-s_{ij}}{v_{M}} eij=vMsij∗−sij
- σ = 1 m n ∑ i = 0 m ∑ j = 0 n e i j 2 \sigma = \frac{1}{mn} \sqrt{ \sum^{m}_{i=0} \sum^{n}_{j=0} e_{ij}^{2}} σ=mn1i=0∑mj=0∑neij2
- 当 σ \sigma σ较小时,说明 s i j ∗ s^{\ast}_{ij} sij∗和 s i j s_{ij} sij的相对偏差在很小的波动范围内,因此可见度值在该连通区域的分布分布良好。为了评价 σ \sigma σ的可见性图,引入了一个平面度量 Φ f Φ_{f} Φf作为 Φ f = e − σ Φ_{f}=e^{−σ} Φf=e−σ。
2) Interpeak intervals

计算了最接近最大可见度值的连接区域的边界框,并选择该区域的中心作为一个峰值位置。通过检测在其他小区域比其他点值高的点来找到其他峰值。
最大可见度值点的坐标记为 p M p_{M} pM。边界框 l l l的长度和宽度 w w w用于表示将被吸取的对象的大小。以 k k k作为可见度图中所有其他峰的个数, P m = { p 0 ⋅ ⋅ ⋅ p k − 1 } P_{m}=\{p_{0}···p_{k−1} \} Pm={
p0⋅⋅⋅pk−1}作为其他峰的坐标集合,定义一个区间度量 Φ d Φ_{d} Φd。
a = w + l 2 Φ d = min { 1 , ∣ ∣ p M − p i ∣ ∣ 2 a } ( i = 0 , 1 , ⋯ , k − 1 ) a = \frac{w+l}{2} \\ Φ_{d} = \min\{1,\frac{||p_{M}-p_{i}||_{2}}{a}\} (i=0,1,\cdots,k-1) a=2w+lΦd=min{
1,a∣∣pM−pi∣∣2}(i=0,1,⋯,k−1)
3) Maximum affordance
直接来源于ConvNet。
4) Reward design
所以最终的度量 Φ Φ Φ被定义为上述三个指标的加权和。
Φ = λ f × Φ f + λ d × Φ d + λ v × v M Φ = \lambda_{f} \times Φ_{f} + \lambda_{d} \times Φ_{d} + \lambda_{v} \times v_{M} Φ=λf×Φf+λd×Φd+λv×vM
其中,三个权值满足:
λ f + λ d + λ v = 1 → Φ ∈ [ 0 , 1 ] λ_{f} +λ_{d} +λ_{v} = 1 \rightarrow Φ \in [0,1] λf+λd+λv=1→Φ∈[0,1]
如果, Φ i Φ_{i} Φi>0.85,则我们认为场景已经足够好地抓取,机器人将停止改变环境。
基于所设计的度量,智能体的目标是最大化这个度量的价值。
如果 Φ i Φ_{i} Φi大于 δ δ δ的最后一帧 Φ i − 1 Φ_{i−1} Φi−1的度量,则奖励为1,否则为-1。
为了减少噪声干扰,我们设置 δ δ δ为0.01。
VI. EXPERIMENT
A. Experiment of DQN Performance in Simulation Environment
the simulation environment: V-REP
11 blocks are added into the scene + manually design several challenging scenes
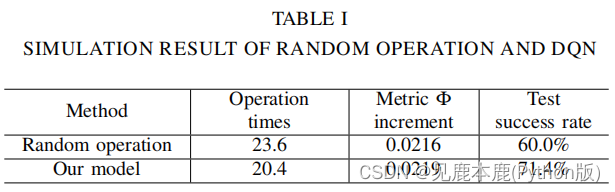
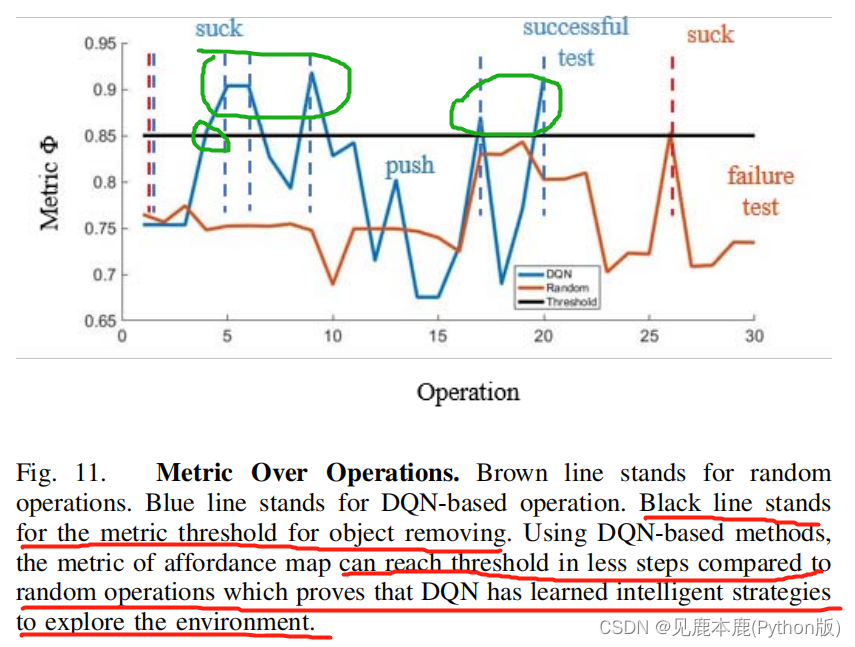
我们比较了所提出的模型和随机操作模型。在随机操作模型中,不是基于DQN的输出来推送对象,而是应用随机推送动作。
使用三个指标来评估它们的性能。
- 每次测试的平均操作次数;
- 每次推送的度量 Φ Φ Φ的平均增量;
- 测试成功率,其定义为成功的测试次数除以测试次数;
1) Evaluation result
2) Training details
| Item | Value | Meaning |
|---|---|---|
| Training Method | RMSPropOtimizer | |
| learning rates | 1 0 − 3 10^{−3} 10−3 to 2.5 × 1 0 − 4 2.5×10^{−4} 2.5×10−4 | |
| the momentum | 0.9 | |
| γ \gamma γ | 0.6 | more attention on current epoch |
| ϵ \epsilon ϵ | 1 then 0.2 | giving allowance for more attempts on new pushing strategies |
B. Robotic Experiments
1) Experiment setup
Microsoft’s Kinect V2 camera
the UR5 manipulator
我们选择了40个不同的物体来构建不同的场景,让我们的机械手来抓取。
2) Evaluation metric
因此,我们将测试定义为在同一物体上连续3次提升失败时的失败,而在一个场景中的10个物体成功提升时,我们将测试定义为成功。
在此基础上,我们定义了3个指标。
- 对象的平均数量成功抓住每个测试
- 吸成功率,定义为成功的数量成功除以提升操作
- 测试成功率,定义为成功测试的数量除以测试的数量
3) Experiment result
实验结果表明,经过主动探索优化后,该系统的吸力成功率和试验成功率性能较好。与仅使用静态可见性图进行提升相比,主动探索减少了重复故障提升的可能性,使其对场景更稳健。

当系统只依赖于静态的可见度图来抓取时,它在混乱的场景中很可能会失败。图13为静态视觉图抓取实验结果。

在图14中,机械手主动地探索环境,寻找合适的抓取点。

然而,通过主动勘探优化的可见图仍存在一些问题。有两个主要的问题。
- 第一个问题是,所提出的度量 Φ Φ Φ不能区分所有不适合抓取的坏场景。当一个物体没有足够的提升支撑能力时,我们的系统就无法获得这些信息,而这类物体也很难抓取。
- 第二个问题是,我们的DQN有时会在没有物体的区域输出无用的推动动作。

4) Result analysis
然而,所提出的抓取策略仍然不完美,存在一些无用的推动作,包括在没有任何物体的地方进行推杆,系统不能识别各种不适合抓取的物体。
此外,一些表面不均匀的物体仍然很难用这种策略举起。随着物体被不断地移除,场景将变得越来越简单。因此,该策略逐渐倾向于直接或少推采用静态可见度图,以确保抓取的效率。