文章目录
前言
接着Exploration Strategies in Deep Reinforcement Learning (1)继续。
基于Exploration Strategies in Deep Reinforcement Learning再创作。
Intrinsic Rewards as Exploration Bonuses
更好地进行探索(尤其是解决难题)的一种常见方法是通过额外的bonus来增加环境的奖励,以鼓励进行额外的探索。因此,策略以包含两项的奖励来训练,即 r t = r t e + β r t i r_t = r^e_t +\beta r^i_t rt=rte+βrti,其中 β \beta β是调整利用与探索之间的平衡的超参数。
- r t e r^e_t rte是时间 t t t处来自环境的外部奖励,根据手头的任务定义。
- r t i r^i_t rti是时间t的内部探索bonus。
这种内在的奖励在某种程度上受到心理学的内在动机的启发(Oudeyer&Kaplan, 2008)。好奇心驱使的探索可能是儿童成长和学习的重要方式。换句话说,探索性活动应该在人类思维中获得内在奖励,以鼓励这种行为。内在的回报可能与好奇心,惊奇,对国家的熟悉以及许多其他因素有关。
相同的想法可以应用于RL算法。在以下各节中,基于bonus的探索奖励方法大致分为两类:
- 发现新状态
- agent关于环境知识的提升
Count-based Exploration
如果我们将内在奖励视为使我们感到惊讶的奖励条件,那么我们需要一种方法来衡量一个状态是新颖的还是经常出现的。一种直观的方法是计算遇到某个状态的次数并相应地分配奖励。bonus引导agent的行为偏向很少访问的状态,而不是常见的状态。这称为基于计数的探索方法。
令 N n ( s ) N_n(s) Nn(s)为经验计数函数,该函数记录序列 s 1 : n s_{1:n} s1:n中状态 s s s的实际访问次数。不幸的是,直接使用 N n ( s ) N_n(s) Nn(s)进行探索是不切实际的,因为大多数状态的 N n ( s ) = 0 N_n(s)=0 Nn(s)=0,尤其是考虑到状态空间通常是连续的或高维的。 对于大多数状态,即使以前从未见过,我们都需要一个非零计数。
Counting by Density Model
Bellemare, et al. (2016)使用密度模型来估计状态访问的频率,并使用一种新颖的算法从该密度模型中得出伪计数。首先定义状态空间上的条件概率 ρ n = ρ ( s ∣ s 1 : n ) \rho_n=\rho(s|s_{1:n}) ρn=ρ(s∣s1:n)作为在前n个状态为 s 1 : n s_{1:n} s1:n的情况下,第(n + 1)个状态为 s s s的概率。为了实验上衡量它,我们可以简单地使用 N n ( s ) n \frac{N_n(s)}{n} nNn(s)。
让我们还将状态s的 recoding probability 定义为密度模型观察到新出现的s之后分配给s的概率, ρ n ′ ( s ) = ρ ( s ∣ s 1 : n s ) \rho^′_n(s)=\rho(s | s_{1:n}s) ρn′(s)=ρ(s∣s1:ns)。
文章介绍了两个概念以更好地调节密度模型:伪计数函数 N ^ n ( s ) \hat{N}_n(s) N^n(s)、伪计数和 n ^ \hat{n} n^。由于它们旨在模仿经验计数函数,因此我们有:
ρ n ( s ) = N ^ ( s ) n ^ ≤ ρ ′ ( s ) = N ^ ( s ) + 1 n ^ + 1 \rho_n(s)=\frac{\hat{N}(s)}{\hat{n}}\leq\rho'(s)=\frac{\hat{N}(s)+1}{\hat{n}+1} ρn(s)=n^N^(s)≤ρ′(s)=n^+1N^(s)+1
ρ n ( s ) \rho_n(s) ρn(s)和 ρ n ′ ( s ) \rho'_n(s) ρn′(s)之间的关系要求密度模型learning-positive:对于所有的 s 1 : n ∈ S n s_{1:n}\in S^n s1:n∈Sn以及所有的 s ∈ S s\in S s∈S,都有 ρ n ( s ) ≤ ρ n ′ ( s ) \rho_n(s)\leq \rho'_n(s) ρn(s)≤ρn′(s)。换句话说,观察到一个 s s s实例后,密度模型对于这个 s s s的预测应该增加。除了learning-positive,密度模型应该完全在线训练,使用非随机的经验状态的minibatches,因此自然的我们有 ρ n ′ ( s ) = ρ n + 1 \rho'_n(s)=\rho_{n+1} ρn′(s)=ρn+1。
伪计数可以通过解线性方程得到:
N ^ n ( s ) = n ^ ρ n ( s ) = ρ n ( s ) ( 1 − ρ n ′ ( s ) ) ρ n ′ ( s ) − ρ n ( s ) \hat{N}_n(s)=\hat{n}\rho_n(s)=\frac{\rho_n(s)(1-\rho'_n(s))}{\rho'_n(s)-\rho_n(s)} N^n(s)=n^ρn(s)=ρn′(s)−ρn(s)ρn(s)(1−ρn′(s))
或者通过prediction gain(PG)估计:
N ^ n ( s ) ≈ ( e P G n ( s ) − 1 ) − 1 = ( e log ρ n ′ ( s ) − log ρ n ( s ) − 1 ) − 1 \hat{N}_n(s)\approx(e^{PG_n(s)}-1)^{-1}=(e^{\log \rho'_n(s)-\log \rho_n(s)}-1)^{-1} N^n(s)≈(ePGn(s)−1)−1=(elogρn′(s)−logρn(s)−1)−1
通常count-based的内在bonus为: r t i = N ( s t , a t ) − 1 2 r_t^i=N(s_t,a_t)^{-\frac{1}{2}} rti=N(st,at)−21(as in MBIE-EB; Strehl & Littman, 2008)。pseudo-count-based探索是类似的: r t i = ( N ^ ( s t , a t ) + 0.01 ) − 1 2 r_t^i=(\hat{N}(s_t,a_t)+0.01)^{-\frac{1}{2}} rti=(N^(st,at)+0.01)−21
Bellemare et al., (2016) 的实验采用了一个简单的 CTS(Context Tree Switching)密度模型来估计伪计数。CTS 模型将 2D 图像作为输入,并根据位置相关的 L 形滤波器的乘积为其分配概率,其中每个滤波器的预测由在过去图像上训练的 CTS 算法给出。CTS 模型很简单,但在表达能力、可扩展性和数据效率方面存在局限性。 在后续论文中,Georg Ostrovski, et al. (2017)通过训练 PixelCNN (van den Oord et al., (2016)) 作为密度模型改进了该方法。
密度模型也可以是 Zhao & Tresp (2018) 中的高斯混合模型。他们使用变分 GMM 来估计轨迹的密度(例如,一系列状态的串联)及其预测概率,以指导off-policy设置中经验重放的优先级。
Counting after Hashing
使计数高维状态成为可能的另一个想法是将状态映射到哈希码,以便状态的出现变得可追踪(Tang et al. 2017)。状态空间用哈希函数 ϕ : S ⟼ Z k \phi:S\longmapsto\mathbf{Z}^k ϕ:S⟼Zk离散化。 探索奖励 ri:S↦R 被添加到奖励函数中,定义为 ri(s)=N(ϕ(s))−1/2,其中 N(ϕ(s)) 是 ϕ 出现的经验计数 (s)。探索bonus为 r i ( s ) = N ( ϕ ( s ) ) − 1 2 r^i(s)=N(\phi(s))^{-\frac{1}{2}} ri(s)=N(ϕ(s))−21,其中 N ( ϕ ( s ) ) N(\phi(s)) N(ϕ(s))是 ϕ ( s ) \phi(s) ϕ(s)出现次数的计数。

Tang et al. (2017) 提出使用 Locality-Sensitive Hashing (LSH) 将连续的高维数据转换为离散的哈希码。LSH 是一类流行的哈希函数,用于基于某些相似性度量查询最近邻居。如果哈希方案 x ⟼ h ( x ) x\longmapsto h(x) x⟼h(x)保留数据点之间的距离信息,则它是位置敏感的,这样相近向量获得相似的哈希,而远向量具有非常不同的哈希。SimHash 是一种计算效率高的 LSH,它通过角距测量相似性:
ϕ ( s ) = s g n ( A g ( s ) ) ∈ { − 1 , 1 } k \phi(s)=sgn(Ag(s))\in\{-1,1\}^k ϕ(s)=sgn(Ag(s))∈{
−1,1}k
A ∈ R k × D A\in \mathbf{R}^{k\times D} A∈Rk×D是一个矩阵,每个条目都是从标准高斯中独立同分布地采样得到, g : S ⟼ R D g:S\longmapsto \mathbf{R}^D g:S⟼RD是一个可选的预处理函数。二进制编码的维度是 k k k,控制状态空间离散的粒度, k k k越大粒度越高,碰撞越少。
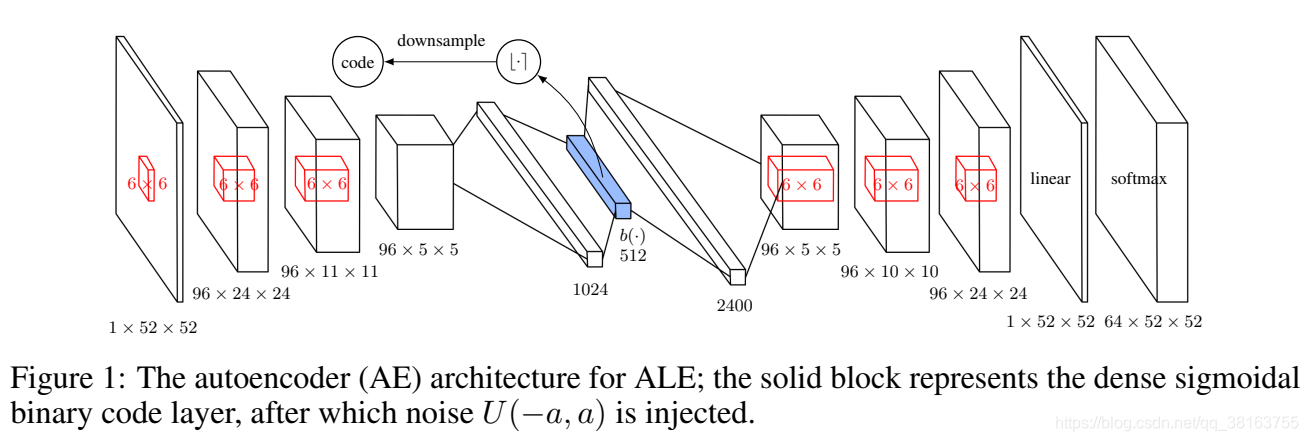

对于高维图像,SimHash 在原始像素级别上可能效果不佳。Tang et al. 2017设计了一个autoencoder(AE),它以输入状态 s s s来学习哈希码。它有一个特殊的全连接层,由 k 个 sigmoid 函数组成作为中间的潜在状态,然后该层的 sigmoid 激活值 b ( s ) b(s) b(s) 通过四舍五入到最接近的二进制数进行二值化 ⌊ b ( s ) ⌉ ∈ { 0 , 1 } D ⌊b(s)⌉\in\{0, 1\}^D ⌊b(s)⌉∈{
0,1}D 作为状态 s s s 的二进制哈希码。n 个状态的 AE 损失包括两项:
L ( { s n } n = 1 N ) = − 1 N ∑ n = 1 N log p ( s n ) ⏟ reconstruction loss + 1 N λ K ∑ n = 1 N ∑ i = 1 k min { ( 1 − b i ( s n ) ) 2 , b i ( s n ) 2 } ⏟ sigmoid activation being closer to binary \mathcal{L}(\{s_n\}_{n=1}^N)=\underbrace{-\frac{1}{N}\sum_{n=1}^N\log p(s_n)}_{\text{reconstruction loss}}+\underbrace{\frac{1}{N}\frac{\lambda}{K}\sum_{n=1}^N\sum_{i=1}^k\min\{(1-b_i(s_n))^2,b_i(s_n)^2\}}_{\text{sigmoid activation being closer to binary}} L({
sn}n=1N)=reconstruction loss
−N1n=1∑Nlogp(sn)+sigmoid activation being closer to binary
N1Kλn=1∑Ni=1∑kmin{
(1−bi(sn))2,bi(sn)2}
p ( s n ) p(s_n) p(sn)是AE的输出, λ \lambda λ是用来放缩的。这个方法的一个问题是不同的输入可能会映射到相同的哈希码,但我们希望 AE 仍然可以完美地重建它们。有人可能想用哈希码 ⌊ b ( s ) ⌉ ⌊b(s)⌉ ⌊b(s)⌉替换瓶颈层 b ( s ) b(s) b(s),但是梯度不能通过rounding函数反向传播。注入均匀噪声可以减轻这种影响,因为 AE 必须学会将潜在变量推分离以抵抗噪声。