文章目录
前言
探索-利用两难是RL中的关键主题,执行目标策略使得我们可以直接计算目标策略的状态值,但当前策略不一定是全局最优,因此需要探索避免局部最优,但这又增加了训练时间。本文为再创作,不是单纯的翻译,旨在较全面了解有哪些探索方式,更多是浮于表面的了解。顺便推荐一下这个作者,文章质量很高。
Exploration Strategies in Deep Reinforcement Learning
Classic Exploration Strategies
首先是在多臂老虎机和tabular RL上效果不错的探索方法:
- Epsilon-greedy:以 ϵ \epsilon ϵ的概率进行随机探索, 1 − ϵ 1-\epsilon 1−ϵ的概率执行最优策略。作为一种经典方法,annealing epsilon-greedy在DRL上也有广泛的应用。
- Upper confidence bounds:选择动作最大化上置信界 Q ^ t ( a ) + U ^ t ( a ) \hat{Q}_t(a)+\hat{U}_t(a) Q^t(a)+U^t(a),其中 Q ^ t ( a ) \hat{Q}_t(a) Q^t(a)是截至时间 t t t,动作 a a a的平均奖赏; U ^ t ( a ) \hat{U}_t(a) U^t(a)是一个反比于 a a a被执行次数的函数。因此该策略会优先选被执行次数少、但Q值大的动作,也就是说这个动作似乎很好,但因为执行次数不够所以要多次执行得到准确的Q值,确保其是真的好。更多细节可参考这里。
- Boltzmann exploration:根据 boltzmann distribution (softmax) 采样动作,每个动作的概率为 e Q t ( a ) τ ∑ b = 1 n e Q t ( b ) τ \frac{e^{\frac{Q_t(a)}{\tau}}}{\sum_{b=1}^{n}e^{\frac{Q_t(b)}{\tau}}} ∑b=1neτQt(b)eτQt(a),差异通过温度参数 τ > 0 \tau>0 τ>0控制。高温趋近随机,低温趋近贪心。
- Thompson sampling:agent跟踪对最佳行动的可能性的信念,并从该分布中采样。首先定义每个动作的Beta分布 B e t a ( α , β ) Beta(\alpha,\beta) Beta(α,β), α \alpha α代表成功得到奖赏的次数, β \beta β代表失败的次数,基于某种先验初始化两者。在时间步 t t t,我们对于每个动作都采样其期望奖赏,选择期望奖赏最大的动作。得到奖赏后,更新被选动作的参数: α + = r t , β + = ( 1 − r t ) \alpha+=r_t,\beta+=(1-r_t) α+=rt,β+=(1−rt)。本质是Probability matching,根据观察推断概率,让概率匹配观察,想了解更多可参考这个。
下面的策略可以在DRL上有更好的探索:
- Entropy loss term:在损失函数里增加一个策略的熵,鼓励执行不同的动作
- Noise-based Exploration:在观察、动作甚至参数空间增加噪声(Fortunato, et al. 2017, Plappert, et al. 2017)
Key Exploration Problems
环境噪声和稀疏奖赏让探索变得尤其困难。
The Hard-Exploration Problem
“hard-exploration”问题是指在奖励非常稀少甚至具有欺骗性的环境中进行探索。这很困难,因为在这种情况下进行随机探索很少会发现成功状态或获得有意义的反馈,比如Montezuma’s Revenge。
The Noisy-TV Problem
“Noisy-TV”问题始于Burda等人(2018年)的思想实验。假设agent通过寻求新奇的经验获得奖赏,那么具有不可控和不可预测的随机噪声输出的电视将能够永远吸引agent的注意力。agent始终从嘈杂的电视中获得新的奖励,但未能取得任何有意义的进步,因此成为“couch potato”。
{kind=link}
Q-Value Exploration
受 Thompson sampling 的启发,Bootstrapped DQN(Osband, et al. 2016)通过使用自举方法引入了经典DQN中Q值近似的不确定性概念。自举法是通过多次从相同总体中进行有放回采样,然后汇总结果来近似分布。
多个Q值头并行训练,但每个头仅消耗一个自举子采样数据集,每个磁头都有自己的对应目标网络。所有Q值头均共享同一骨干网。


在一个episode开始时,将均匀采样一个Q值头,然后在这个episode中执行收集经验数据。然后从掩码分布 m ∼ M m\sim M m∼M中采样一个二进制掩码,并确定哪些头可以使用该数据进行训练。掩码分布 M M M的选择决定了如何生成bootstrapped样本,例如:
- 如果 M M M是 p = 0.5 p = 0.5 p=0.5的独立伯努利分布,则它对应于double-or-nothing bootstrap。
- 如果 M M M总是返回全一掩码,则该算法将简化为集成方法 。
但是,这种探索仍然受到限制,因为自举引入的不确定性完全依赖于训练数据。最好注入一些独立于数据的先验信息。期望这种“嘈杂”的先验将促使agent在奖赏稀疏的时候持续探索。在bootstrapped DQN中添加随机先验以进行更好探索的算法(Osband, et al. 2018)是基于贝叶斯线性回归。贝叶斯回归的核心思想是:“我们可以通过在数据的嘈杂版本上训练,并进行一些随机正则化来生成后验样本”。 使用统计学的bootstrap而不是高斯噪声来实现状态相关的变化。

令 f θ f_\theta fθ为非线性Q函数, f θ − f_{\theta^-} fθ−为非线性目标Q函数,使用随机先验函数 p p p和数据 D D D的损失函数为:
L γ ( θ ; θ − , p , D ) : = ∑ t ∈ D ( r t , γ max a ′ ∈ A ( f θ − + p ⏟ target Q ) ( s t ′ , a ′ ) − ( f θ + p ⏟ online Q ) ( s t , a t ) ) 2 \mathcal{L}_{\gamma}(\theta;\theta^-,p,D):=\sum_{t\in D}(r_t,\gamma\max_{a'\in A}(\underbrace{f_{\theta^-}+p}_{\text{target Q}})(s_t',a')-(\underbrace{f_{\theta}+p}_{\text{online Q}})(s_t,a_t))^2 Lγ(θ;θ−,p,D):=t∈D∑(rt,γa′∈Amax(target Q
fθ−+p)(st′,a′)−(online Q
fθ+p)(st,at))2
Variational Options
options是具有终止条件的策略。搜索空间中有大量可用options,它们与agent的意图无关。通过将内部options明确地包含在建模中,agent可以获取内部的奖赏用于探索。
VIC (short for “Variational Intrinsic Control”; Gregor, et al. 2017)就是这样一种通过建模options和学习基于options的策略来给agent提供内部探索奖赏。令 Ω \Omega Ω代表从 s 0 s_0 s0开始 s f s_f sf结束的一个option。环境概率分布 p J ( s f ∣ s 0 , Ω ) p^J(s_f|s_0,\Omega) pJ(sf∣s0,Ω)定义了给定起始状态 s 0 s_0 s0,option Ω \Omega Ω在哪里终止。可控制性分布 p C ( Ω ∣ s 0 ) p^C(\Omega|s_0) pC(Ω∣s0)定义了我们可以从中采样option的概率分布。因此可得 p ( s f , Ω ∣ s 0 ) = p J ( s f ∣ s 0 , Ω ) P C ( Ω ∣ s 0 ) p(s_f,\Omega|s_0)=p^J(s_f|s_0,\Omega)P^C(\Omega|s_0) p(sf,Ω∣s0)=pJ(sf∣s0,Ω)PC(Ω∣s0)
选择options的时候想要实现两个目标:
- 实现一个多样的起始于 s 0 s_0 s0的终结状态集合,即最大化 H ( s f ∣ s 0 ) H(s_f|s_0) H(sf∣s0)
- 准确知道一个给定 Ω \Omega Ω的终结状态,即最小化 H ( s f ∣ s 0 , Ω ) H(s_f|s_0,\Omega) H(sf∣s0,Ω)
两者结合就能得到要最大化的互信息:
I ( Ω ; s f ∣ s 0 ) = H ( s f ∣ s 0 ) − H ( s f ∣ s 0 , Ω ) I(\Omega;s_f|s_0)=H(s_f|s_0)-H(s_f|s_0,\Omega) I(Ω;sf∣s0)=H(sf∣s0)−H(sf∣s0,Ω)

此处,可以使用任何RL算法优化 π ( a ∣ Ω , s ) \pi(a|\Omega,s) π(a∣Ω,s)。option推理函数 q ( Ω ∣ s 0 , s f ) q(\Omega|s_0,s_f) q(Ω∣s0,sf)进行监督学习。先验 p C p^C pC被更新使得它倾向于选择具有较高奖励的 Ω \Omega Ω。请注意, p C p^C pC也可以是固定的(例如高斯)。通过学习,各种 Ω \Omega Ω都会导致不同的行为。
DIAYN为“Diversity is all you need”的缩写,它是一个鼓励策略在没有奖赏函数的情况下学习有用技能的框架。它显式地将隐变量 z z z建模为skill embedding,并使策略基于状态 s s s和 z z z, π θ ( a , ∣ s , z ) \pi_{\theta}(a,|s,z) πθ(a,∣s,z)。其基于一些假设:
- 技能应该多样化,并导致不同状态的访问 → \to →最大化状态与技能之间的互信息 I ( S ; Z ) I(S;Z) I(S;Z)
- 技能应该通过状态而不是动作来区分 → \to →以状态为条件,最小化动作和技能之间的互信息 I ( A ; Z ∣ S ) I(A; Z∣S) I(A;Z∣S)
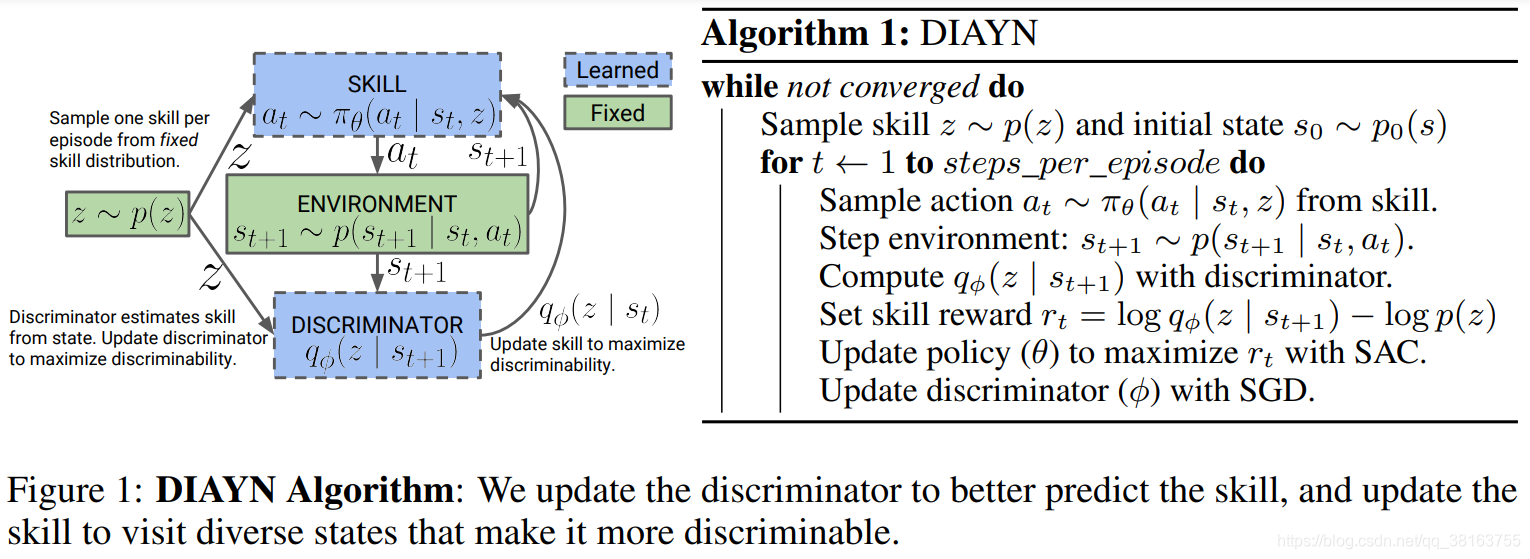
最大化目标函数,增加策略熵鼓励多样性:
F ( θ ) = I ( S ; Z ) + H [ A ∣ S ] − I ( A ; Z ∣ S ) \mathcal{F}(\theta)=I(S;Z)+H[A|S]-I(A;Z|S) F(θ)=I(S;Z)+H[A∣S]−I(A;Z∣S)
另外,Gregor, et al. (2017)观察到,使带有显式option的VIC在实践中很难在有函数近似的情况下起作用,因此他们还提出了另一个带有隐式option的VIC版本。不同于VIC将 Ω \Omega Ω建模为仅基于开始状态和结束状态,VALOR(“Variational Auto-encoding Learning of Options by Reinforcement”;Achiam, et al. 2018)依赖于整个轨迹来提取option上下文 c c c,其从固定的高斯分布中采样。在 VALOR中:
- 策略充当编码器,将上下文从噪声分布转换为轨迹
- 解码器尝试从轨迹中恢复上下文,并奖励使上下文易于区分的策略。解码器永远不会在训练过程中看到动作,因此agent必须与环境进行交互,促进与解码器的通信,以实现更好的预测。而且,解码器循环地输入一条轨迹的step序列,以更好地建模时间步之间的相关性。
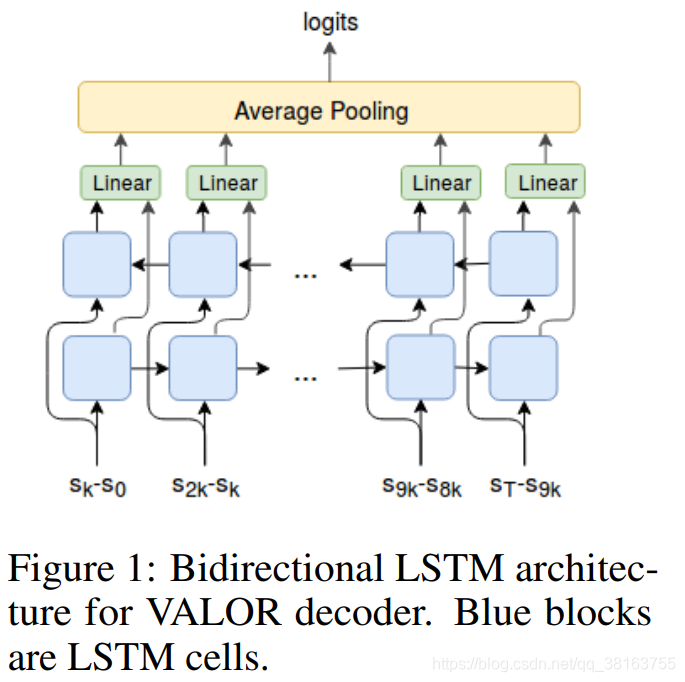
这里使用循环的解码器结构来实现VALOR,使用双向LSTM来确保轨迹的起点和终点都同样重要。我们仅使用来自轨迹的N = 11个等距观测作为输入,原因有两个:1)计算效率;2)编码一个启发式信息,即我们只对低频行为感兴趣(与信息密集的高频抖动相反)。最后,从Vezhnevets et al.(2017)那里获得启发,仅从N个观测值之间的状态空间中的k步transitions(deltas)中进行解码。直观上,这对应于agent应该移动的先验,因为在agent处于不同姿势保持静止的任何两种模式下,解码器都无法区分它们(因为delta相同地为零)。
DIAYN和VIC都是从状态解码,而不是整条轨迹。