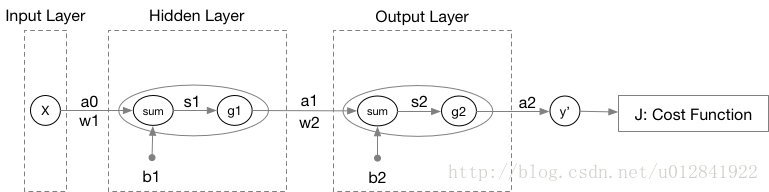
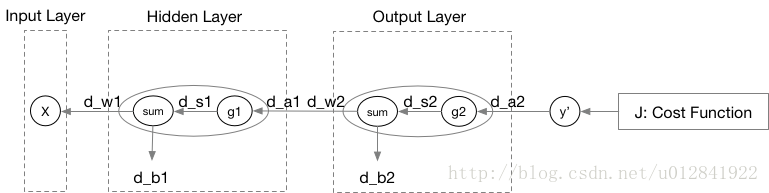
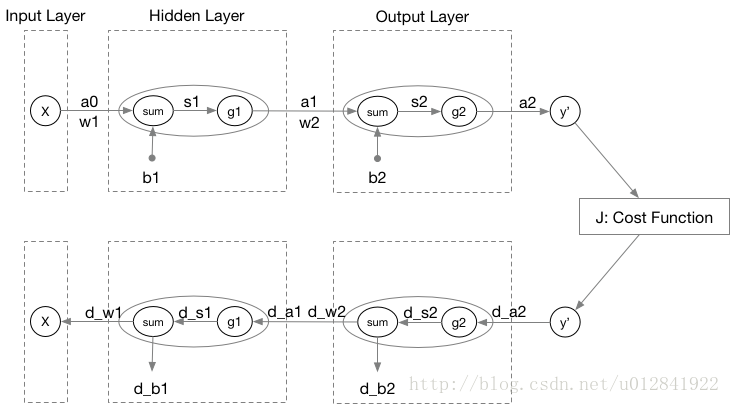
首先,我们以一个双层神经网络为例展示神经网络关于数据标签的计算过程(即前向传播)。
其中,
Wl
和
bl
分别表示第
l
层神经元的权重参数和偏置项,
sl=WlTal−1+bl
。
gl
表示第
l
层神经元的激活函数,不同层可以选取不同的函数作为激活函数。
al
表示第
l
层神经元的输出。本例最终的输出
a2
即是该神经网络针对数据集
X
计算得到的预测值
ŷ
。
我们可以构建出本神经网络的成本函数
J(ŷ )
。一个常见的方式是采用最小二乘法,使得残差最小化:
J(ŷ )=1m∑i=1m(yi−ŷ i)2=1m(Y−Ŷ )T(Y−Ŷ )
我们以上图为例,将每层神经元的计算过程以数学公式表示:
{s1=W1a0+b1a1=g1(s1){s2=W2a1+b2a2=g2(s2)
然后,我们来扩展成本函数
J(ŷ )
:
J(ŷ )=J(a2)=J[g2(s2)]=J[g2(W2a1+b2)]=J{g2[W2g1(W1a0+b1)+b2]}=J{g2[W2g1(W1X+b1)+b2]}
为易于观察,对于不同函数
J,g2,g1
,上式采用了不同的括号。上式即嵌套的函数:
J(ŷ )=J(g2(g1(X)))
。因此,使得成本函数
J(ŷ )
最小化,我们可以使用
梯度下降法得到此例中的自变量
W1,W2,b1
和
b2
:
{W2=W2−α▽J(W2)b2=b2−α▽J(b2){W1=W1−α▽J(W1)b1=b1−α▽J(b1)
通用的更新公式为:
Wl=Wl−α▽J(Wl)bl=bl−α▽J(bl)
上式便是神经网络的反向传播算法,即其学习策略。下面我将继续以文章开始处的例子详细解释反向传播算法。
其中,
dWl
和
dbl
分别表示成本函数
J
对于
Wl
和
bl
的偏导数,
ds1
亦是如此。我们可以先计算一下
W2
和
b2
的更新公式(因为它们离成本函数最近,偏导的计算量最小):
{W2=W2−α▽J(W2)b2=b2−α▽J(b2)
其中,
▽J(W2)=∂J∂W2=dW2
,
▽J(b2)=∂J∂b2=db2
。
da2=⎡⎣⎢⎢⎢⎢⎢da21da22⋮da2l2⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢∂J∂a21∂J∂a22⋮∂J∂a2l2⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢⎢⎢−2m(y1i−a21i)−2m(y2i−a22i)⋮−2m(yl2i−a2l2i)⎤⎦⎥⎥⎥⎥⎥⎥⎥
其中,
l2
表示神经网络第2层的神经元数目,
J=1m∑i=1m(yi−ŷ i)2
。
ds2=⎡⎣⎢⎢⎢⎢⎢ds21ds22⋮ds2l2⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢da21g2′(s21)da22g2′(s22)⋮da2l2g2′(s2l2)⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢g2′(s21)0⋮00g2′(s22)0………00g2′(s2l2)⎤⎦⎥⎥⎥⎥⎥⎡⎣⎢⎢⎢⎢⎢da21da22⋮da2l2⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢g2′(s21)0⋮00g2′(s22)0………00g2′(s2l2)⎤⎦⎥⎥⎥⎥⎥da2
然后,求
dW2
和
db2
:
dW2=⎡⎣⎢⎢⎢⎢⎢dw211dw221⋮dw2l21dw212dw222dw2l22………dw21l1dw22l1dw2l2l1⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢ds21a11ds22a11⋮ds2l2a11ds21a12ds22a12ds2l2a12………ds21a1l1ds22a1l1ds2l2a1l1⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢ds21ds22⋮ds2l2⎤⎦⎥⎥⎥⎥⎥[a11a12…a1l1]=ds2a1T
db2=⎡⎣⎢⎢⎢⎢⎢db21db22⋮db2l2⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢ds21ds22⋮ds2l2⎤⎦⎥⎥⎥⎥⎥=ds2
对于
W1
和
b1
的更新公式:
{W1=W1−α▽J(W1)b1=b1−α▽J(b1)
其中,
▽J(W1)=ds1a0T
,
▽J(b1)=ds1
(推导过程同上)。其中:
ds1=⎡⎣⎢⎢⎢⎢⎢g1′(s11)0⋮00g1′(s12)0………00g1′(s1l1)⎤⎦⎥⎥⎥⎥⎥da1
da1=⎡⎣⎢⎢⎢⎢⎢da11da12⋮da1l1⎤⎦⎥⎥⎥⎥⎥=⎡⎣⎢⎢⎢⎢⎢⎢ds2T[w211w221…w2l21]Tds2T[w212w222…w2l22]T⋮ds2T[w21l1w22l1…w2l2l1]T⎤⎦⎥⎥⎥⎥⎥⎥=W2Tds2
因此,根据链式规则可得更为通用的公式:
dsl=gl′(sl)Wl+1Tdsl+1dslast=glast′(slast)∂J∂alast
最后,我将本例的前向传播和反向传播的图示结合起来,并给出完整的反向传播更新公式。
{Wl=Wl−α▽J(Wl)=Wl−αdslal−1Tbl=bl−α▽J(bl)=bl−αdsl{dsl=gl′(sl)Wl+1Tdsl+1dslast=glast′(slast)∂J∂alast