深度学习经典网络(1)
1.AlexNet [2012]
论文: ImageNet Classification with Deep Convolutional Neural Networks [2012年ImageNet竞赛冠军]
主要内容:训练了一个很深的卷积神经网络在ImageNet实现1000类图片分类,top-1和top-5的错误率分别达到了37.5%和17%,比当时最好的方法(SIFT+FVs 分别为45.7%和25.7%)降低了8.2%和8.7%。
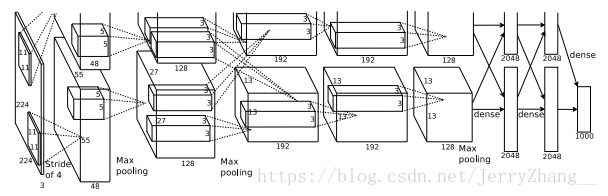
网络结构:五个卷积层,三个全连接层。使用上下两栏的网络结构,在第三个卷积层和全卷积层中,对来自上一层输入数据进行共享。其它处仅使用来自本栏的上一层的数据。
输入图片大小为224X224,由ImageNet上的256X256图片随机裁剪得到,输出维度为1000的向量,表示1000个类别的分类结果。
主要贡献:
(1)使用整流线性单元ReLU代替双曲正切函数tanh作为激活函数,提高了训练的速度;
(2)局部相应归一化(LRN)提高模型泛化能力。对得到的feature map临近的以当前feature map位置为中心的左右各n/2个(若有)feature map 计算同一位置上的激活值的平方和sum的指数函数(K+a*sum)^B 值,以此值作为分母进行归一化。 局部相应归一化的主要思想来自真实神经元之间的相互抑制机制,使具有较大的激活值的神经元能够往后有效传递信息。
(3)重叠池化(Overlaping Pooling)。作者进行了重叠pooling,即使pooling的步长小于pooling核的边长。作者发现使用重叠池化能够降低top-1和top-5的误差0.4%和3%。另外使用重叠池化更不容易过拟合。
防止过拟合策略:
(1)数据集扩增,主要包括两个方面:1)图像的随机裁剪和水平翻转。2)图像RGB通道强度值的调整。
(2)Dropout:作者在前两个全连接层使用了dropout方法,即强制神经元以0.5的概率失火,不输出。 训练多个模型并在预测时使用多个模型平均的结果有利于提高预测的准确度,dropout在训练的过程中随机关闭一些神经元,起到了类似训练了多个模型的效果,有一种类似bagging的作用。同时,使用dropout较少了神经元之间的“复杂合作”,迫使单个的神经元独自学习一种鲁棒的表示能力,减轻对其它神经元的依赖。
训练策略:
(1)weight decay 权值衰减,作者认为这不仅是一个正则化项,同时能减小训练误差
一般的SGD权值更新为:
g=▽θ
wi=wi-εg
带动量的SGD
g=▽θ
v←αV-εg
wi←wi+v
本文中的带权值衰减动量SGD
g=▽θ
v←αv-εg-βεWi(权值衰减部分)
Wi←Wi+v
总结:这篇文章提出了一种深的卷积神经网络结构,通过使用GPU高效训练,使用了一些诸如局部响应归一化、重叠池化、ReLU、权值衰减、dropout等技术,成功训练了深的卷积神经网络,并在ImageNet图片分类上取得了不错的效果。作者同时也通过实验表明网络深度的重要性,减少任何一个卷积层,误差会增加2%。
2.Network In Network [2013]
论文:Network In Network
主要内容:提出了一种称为Network In Network的网络结构,这种结构使用多层感知机连接卷积层,实现上使用1*1的卷积,已达到拟合复杂激活函数的目的。另外相对于一些卷积神经网络的全连接层,使用全局平均池化(Global Average Pooling)代替。这种代替的好处减少了很多参数,并且相比于全连接不容易过拟合。
网络结构:三个mlpconv(multi layer perceptron convolution)连接, 到n(n是分类数)个feature map做global average pooling,得到一个n维的向量,然后送入softmax做分类。
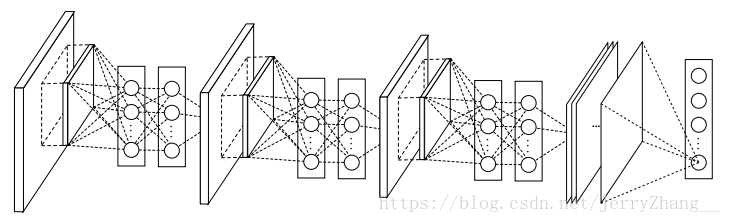
主要贡献:
(1)mlpconv: 优势:1)和传统卷积是兼容,实际上它的实现也是通过11的卷积来实现的;2)本身容易进行深度化。这里11 的卷积实际上是在前一层的feature maps 上做一个非线性的组合,可以使不同通道之间进行复杂交互。 另外1*1的卷积可以用来做升维或降维。
(2)global average pooling: 实际上是将feature map转换成了对每一个类的confidence map。优势有二:一是相比于全连接,更与卷积的结构相适应,这样很容易将这里的feature map视作为confidence map.另外一个优势就是这里没有需要优化的参数,去除了全连接中的大量参数,也很好地避免了过拟合。
结论:提出了新的结构,效果也很好,这种1*1的卷积方式和global average pooling 对以后的文章也有影响。
3.Maxout [2013]
论文:Maxout Network
主要内容:maxout实际上是一种多层感知机或者是神经网络,作为类似激活函数的功能存在,具有拟合任意凸函数的能力。
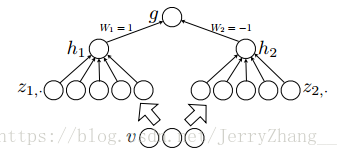
maxout结构:
h1和h2即为maxout的输出,其中Z1和Z2可以看做是隐隐层,通过maxout,可以近似任意的凸函数,充当激活函数。
激活函数的作用:若没有激活函数,即相当于激活函数是f(x)=wx,那么不管网络有多深,都是输入的线性函数,拟合能力有限,激活函数的引入为网络引入了非线性,则网络可以近似任意函数,才拥有很强的表示能力。神经网络中早期使用sigmoid函数,后来使用ReLU,主要原因有:1)sigmoid函数中的指数部分在前向计算和后向传播中计算量较大;2)sigmoid函数容易产生饱和,在两端接近0,1的部分梯度很小,容易产生梯度消失现象,无法传递信息;3)ReLU计算简单,单向抑制使一些神经元输出为0,起到网络稀疏作用,另外这种单向抑制更符合生物神经元的作用。
4.OverFeat [2013]
论文:OverFeat:integrated recognition,localization and detection using convolutional network
主要内容:使用同一个网络进行识别(分类:是什么),定位(是什么,在哪里)和检测(有些什么,在哪里)。
作者定义OverFeat为一种特征提取器(feature extractor),将网络的前面五层视为特征提取层,对于不同的任务将后面的层修改后重新训练,就可以得到很好地效果。这也充分展示了网络的迁移能力。
5.devil [2014]
论文:return of the devil, the details delving the deep into convolutional networks
主要内容:比较了卷积神经网络为代表的深度网络和传统的浅层特征(如BoVW,IFV)等在图像分类识别之间的差异。主要有有三种实验场景:1)使用pre-trained模型,2)使用pre-train的模型进行fine-tuning,3)使用浅层特征。
结论:使data augmentation技术可以使浅层表示的效果有提升,但是即使提升之后和深度网络之间还是有很大差距。使用fine-tuning的方式比使用深度模型+SVM效果要好。
6.VGG [2104]
论文:very deep convolutional network for large scale image recognition
主要内容:探索了使用小的卷积核尺寸(3X3)构建深的网路,并取得了很好的结果,14年ImageNet定位和分类的1,2名。
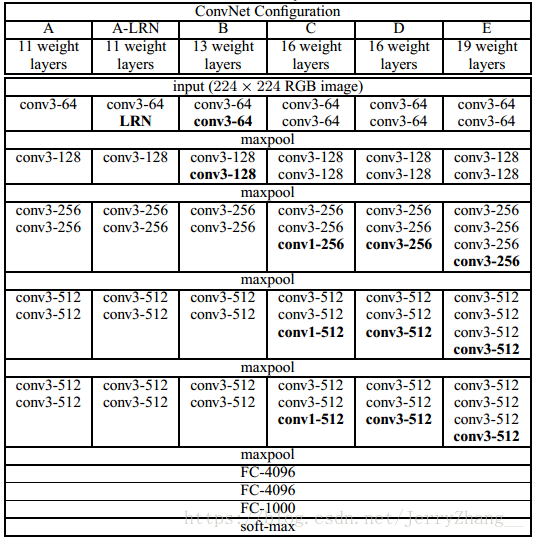
VGG19结构-22444+3 VGG16: 22333+3
主要发现:文章采用的3X3的卷积核的堆叠代替大尺寸的卷积核(如77)。两个33的卷积核的感受野与55的卷积核等同。3个33的卷积核的感受野与77的卷积核等同。有点在于:1)增加非线性,1个77使用了一个非线性激活单元,3个33 使用三个非线性激活函数,增加了网络的非线性,使网络的识别能力更强。 2)减少了参数:假设输入输出通道数目为C,3个33: 3*(33)CC , 而一个77: 77CC。比例为0.55:1。这可以看做是对77卷积核的一种正则化。
1*1的卷积核可以用来在不影响感受野的前提下对增加的网络的非线性,这在NIN文章阅读中有说明,VGG中用的是线性的。
总结:VGG在没有改变LeNet的基本结构的基础上,大大加深的网络的深度,展示了深度对于网络的重要性和好处。其在图像分类,物体定位等方面效果都很多,很多在VGG基础上进行fine-tuning的文章也展示了VGG网络强大的特征学习能力和应对多种应用的能力。
7.ResNet [2016]
论文: deep residual learning for image recognition
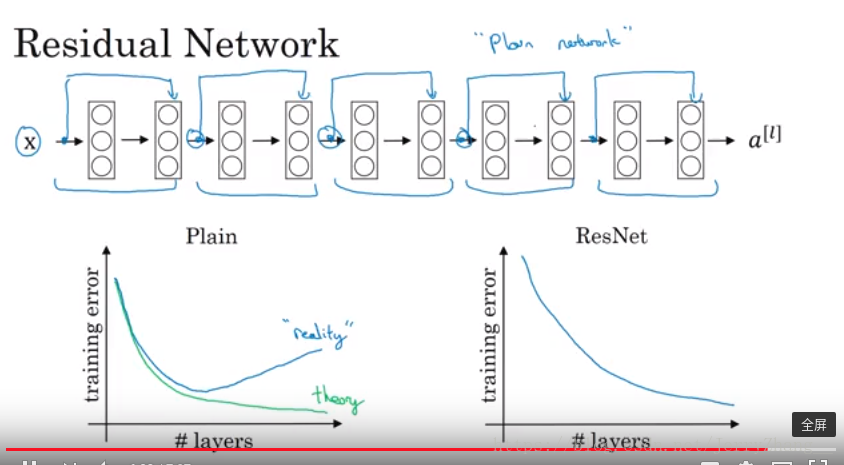
背景:更深的网络越来越不容易训练。
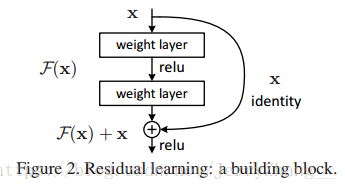
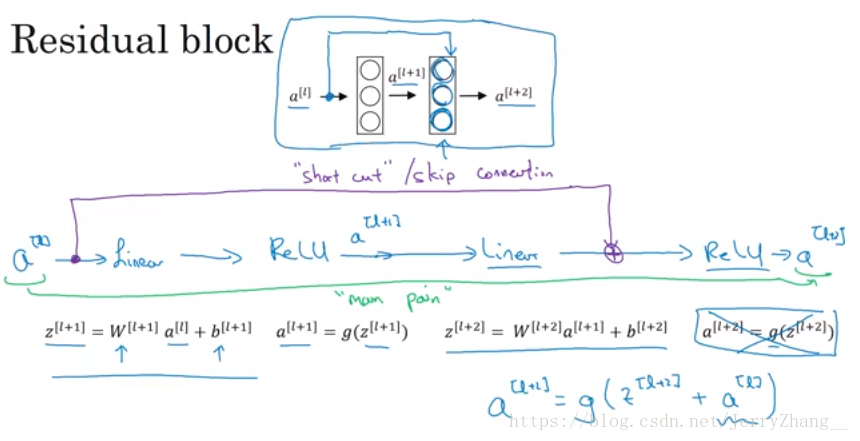
主要内容:提出了一种残差网络结构,这种网络结构易于训练,并能从网络的深度中获得准确率的增加。 网络输入为x, 传统网络的一些层学习映射H(x),现在要学习的残差为F(x)=H(x)-x,那么H(x)=F(x)+x,在残差网络中,不改变网络基本结构的情况下,加一个从输入x到输出F(x)之间的相加连接,就可以得到H(x); 这样学习到的就是F(x).
主要问题(驱动):之前的一些网络随着网络深度的增加,网络的准确率会出现饱和甚至出现退化。理论上对于一个已经构建好的较浅的网络,对于该网络,在它的后面增加一些恒等映射层,它的性能应该基本不变,但是实验发现,随着深度的增加,网络的性能会出现饱和甚至降低。也就是说这种结构很难实现恒等映射。使用残差网络,如果恒等映射是最优的,那么残差网络可以驱使非线性层输出为0而使得能够近似恒等映射。
网络结构(block):
这种跨层连接中间有两到三层,一层的话还是个线性映射,没有效果。F(x)+x是通过逐元素的相加完成的,对应通道的feature map相加。
网络中使用步长为2的卷积代替pooling, 每次feature map的尺寸减小一半,使feature map的数量增加一倍。对于feature map数目变化后的F(x)+x, 1)增加0的小尺寸(x)feature map, 2)使用1*1 的卷积核对x做卷积得到同样数目的feature map. 对于这两种情况,最后相加的时候都是按照步长为2进行相加的。