AlexNet 模型
http://cvml.ist.ac.at/courses/DLWT_W17/material/AlexNet.pdf
ImageNet Classification with Deep Convolutional Neural Networks 是Hinton和他的学生Alex Krizhevsky在12年ImageNet Challenge使用的模型结构,刷新了Image Classification的几率,从此deeplearning在Image这块开始一次次超过state-of-art,甚至于搭到打败人类的地步
这就是那张图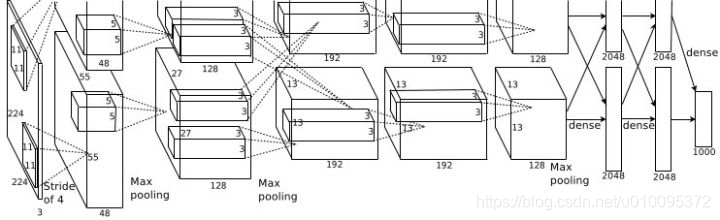
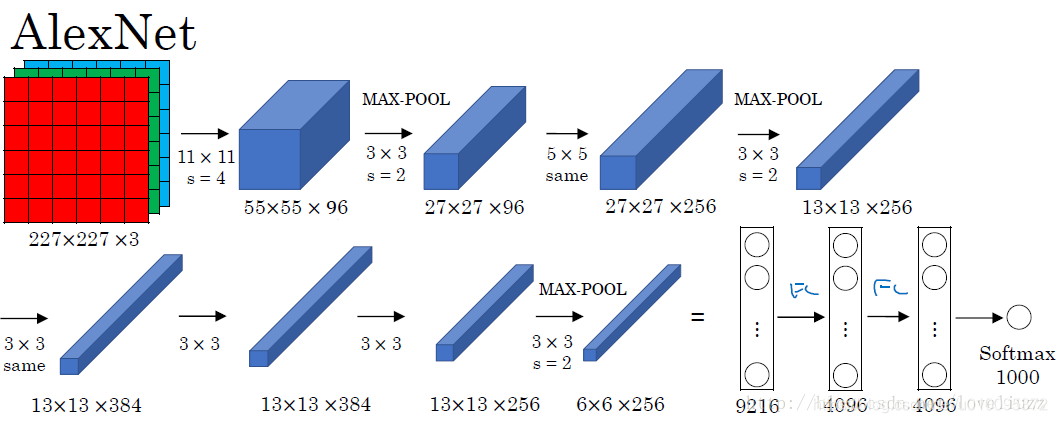
AlexNet 有8层,前5层是卷积层,后3层是全连接层,最后一层全连接层的输出是1000维softmax的输入
第一层,卷积层
第1卷积层使用96个核对224 × 224 × 3的输入图像进行滤波,核大小为11 × 11 × 3,步长是4个像素(核映射中相邻神经元感受野中心之间的距离)。
第二层,卷积层
第2卷积层使用用第1卷积层的输出(响应归一化和池化)作为输入,并使用256个核进行滤波,核大小为5 × 5 × 48。第3,4,5卷积层互相连接,中间没有接入池化层或归一化层。
第三层,卷积层
第3卷积层有384个核,核大小为3 × 3 × 256,与第2卷积层的输出(归一化的,池化的)相连。
第四层,卷积层
第4卷积层有384个核,核大小为3 × 3 × 192。
第五层,卷积层
第5卷积层有256个核,核大小为3 × 3 × 192。每个全连接层有4096个神经元。
MxNet 实现
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import data as gdata, nn
import os
import sys
net = nn.Sequential()
net.add(nn.Conv2D(96, kernel_size=11, strides=4, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 减⼩卷积窗⼝,使⽤填充为2来使得输⼊与输出的⾼和宽⼀致,且增⼤输出通道数
nn.Conv2D(256, kernel_size=5, padding=2, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 连续3个卷积层,且使⽤更⼩的卷积窗⼝。除了最后的卷积层外,进⼀步增⼤了输出通道数。
# 前两个卷积层后不使⽤池化层来减⼩输⼊的⾼和宽
nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(384, kernel_size=3, padding=1, activation='relu'),
nn.Conv2D(256, kernel_size=3, padding=1, activation='relu'),
nn.MaxPool2D(pool_size=3, strides=2),
# 这⾥全连接层的输出个数⽐LeNet中的⼤数倍。使⽤丢弃层来缓解过拟合
nn.Dense(4096, activation="relu"), nn.Dropout(0.5),
nn.Dense(4096, activation="relu"), nn.Dropout(0.5),
# 输出层。由于这⾥使⽤Fashion-MNIST,所以⽤类别数为10,⽽⾮论⽂中的1000
nn.Dense(10))
X = nd.random.uniform(shape=(1, 1, 224, 224))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224, root='./data')
lr, num_epochs, ctx = 0.01, 5, d2l.try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
VGG 模型
用小的过滤器去多次卷积
https://blog.csdn.net/u013181595/article/details/80974210
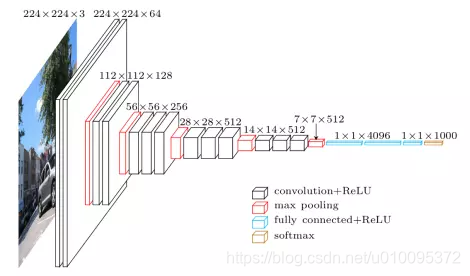
https://www.jianshu.com/p/3510872fb186
INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
def vgg_block(num_convs, num_channels):
blk = nn.Sequential()
for _ in range(num_convs):
blk.add(nn.Conv2D(num_channels, kernel_size=3,
padding=1, activation='relu'))
blk.add(nn.MaxPool2D(pool_size=2, strides=2))
return blk
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
net = nn.Sequential()
# 卷积层部分
for (num_convs, num_channels) in conv_arch:
net.add(vgg_block(num_convs=num_convs, num_channels=num_channels))
net.add(nn.Dense(4096, activation='relu'), nn.Dropout(0.5),
nn.Dense(4096, activation='relu'), nn.Dropout(0.5),
nn.Dense(10))
return net
net = vgg(conv_arch)
net.initialize()
X = nd.random.uniform(shape=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.name, 'output shape:\t', X.shape)
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
net = vgg(small_conv_arch)
lr, num_epochs, batch_size, ctx = 0.05, 5, 128, d2l.try_gpu()
net.initialize(ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224, root='./data')
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
ResNet
ResNet最初的灵感出自这个问题:在不断增加神经网络的深度时,会出现一个Degradation(退化)的问题,即准确率会先上升然后达到饱和,再持续增加深度则会导致准确率下降。这并不是过拟合的问题,因为不光在测试集上误差增大,训练集本身误差也会增大。
假设有一个比较浅的网络达到了饱和的准确率,那么后面再加上几个y=x的全等映射层,起码误差不会增加,即更深的网络不应该带来训练集上误差上升。而这里提到的使用全等映射直接将前一层输出传到后面的思想,就是ResNet的灵感来源。假定某段神经网络的输入是x,期望输出是H(x),如果我们直接把输入x传到输出作为初始结果,那么此时我们需要学习的目标就是F(x) = H(x) - x。如图所示,这就是一个ResNet的残差学习单元(Residual Unit),ResNet相当于将学习目标改变了,不再是学习一个完整的输出H(x),只是输出和输入的差别H(x)-x,即残差。
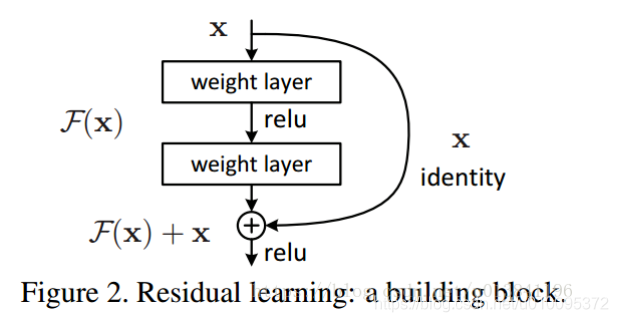
将输入x和输出的F(x)的和来一起做处理
https://blog.csdn.net/u013841196/article/details/80713314
import d2lzh as d2l
from mxnet import gluon, init, nd
from mxnet.gluon import nn
class Residual(nn.Block):
def __init__(self, num_channels, use_1x1conv=False, strides=1, **kwargs):
super(Residual, self).__init__(**kwargs)
self.conv1 = nn.Conv2D(num_channels, kernel_size=3, padding=1,
strides=strides)
self.conv2 = nn.Conv2D(num_channels, kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2D(num_channels, kernel_size=1,
strides=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm()
self.bn2 = nn.BatchNorm()
def forward(self, X):
Y = nd.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
return nd.relu(Y + X)
blk = Residual(3)
blk.initialize()
X = nd.random.uniform(shape=(4, 3, 6, 6))
net = nn.Sequential()
net.add(nn.Conv2D(64, kernel_size=7, strides=2, padding=3),
nn.BatchNorm(),nn.Activation('relu'),
nn.MaxPool2D(pool_size=3, strides=2, padding=1))
def resnet_blok(num_channels, num_residuals, first_block=False):
blk = nn.Sequential()
for i in range(num_residuals):
if i == 0 and not first_block:
blk.add(Residual(num_channels, use_1x1conv=True, strides=2))
else:
blk.add(Residual(num_channels))
return blk
net.add(resnet_blok(64, 2, first_block=True),
resnet_blok(128, 2),
resnet_blok(256, 2),
resnet_blok(512, 2))
net.add(nn.GlobalAvgPool2D(), nn.Dense(10))
X = nd.random.uniform(shape=(1, 1, 224, 224))
net.initialize()
for layer in net:
X = layer(X)
print(layer.name, 'output shape:\t', X.shape)
lr, num_epochs, batch_size, ctx = 0.05, 5, 256, d2l.try_gpu()
net.initialize(force_reinit=True, ctx=ctx, init=init.Xavier())
trainer = gluon.Trainer(net.collect_params(), 'sgd', {'learning_rate': lr})
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch5(net, train_iter, test_iter, batch_size, trainer, ctx, num_epochs)
