常用数据集:
ImageNet http://www.image-net.org/
Microsoft的COCO http://mscoco.org/
CIFAR-10和CIFAR-100 https://www.cs.toronto.edu/~kriz/cifar.html
PASCAL VOC http://host.robots.ox.ac.uk/pascal/VOC/
模型们在ImageNet竞赛上的top-5错误率概况:

常用预训练模型池:

https://github.com/BVLC/caffe/wiki/Model-Zoo
AlexNet:
AlexNet 代码及模型(Caffe) https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet
微调AlexNet以适应任意数据集(Tensorflow) https://github.com/kratzert/finetune_alexnet_with_tensorflow

AlexNet信息如上图
- 在当时第一次使用了ReLU
- 使用了Norm层(在当时还不广泛)
- 训练数据量增大
- dropout 0.5
- 每批数据大小 128
- 优化方式:随机梯度下降+Momentum 0.9
- 学习率为0.01。每次损失到达瓶颈时除以10
- L2 正则 参数为5e-4
VGG:
VGG-16 官方代码和ILSVRC模型(Caffe) https://gist.github.com/ksimonyan/211839e770f7b538e2d8
VGG-19 官方代码和ILSVRC模型(Caffe) https://gist.github.com/ksimonyan/3785162f95cd2d5fee77
Tensorflow版 VGG-16/VGG-19 https://github.com/machrisaa/tensorflow-vgg
VGG是最符合典型CNN的一种网络,它在AlexNet的基础上加深了网络,以达到更好的效果。
(以下引用http://blog.csdn.net/u012767526/article/details/51442367#vggnet分析)
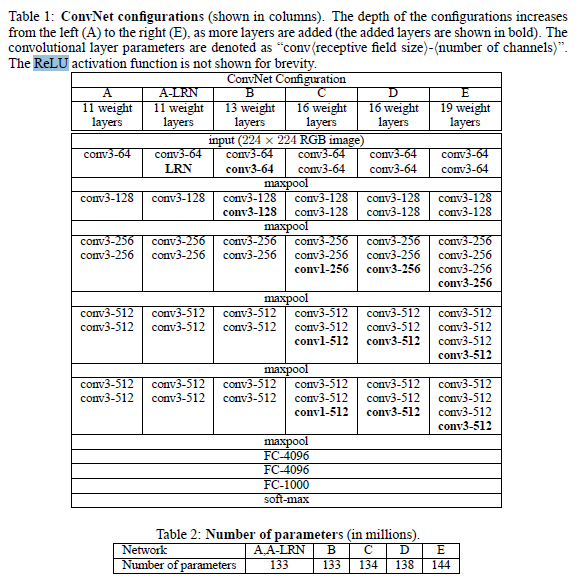
这里有两个表格,其中第一个表格是描述的是VGGNet的诞生过程。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,这种方式在经典的神经网络中经常见得到,就是先训练一部分小网络,然后再确保这部分网络稳定之后,再在这基础上逐渐加深。表1从左到右体现的就是这个过程,并且当网络处于D阶段的时候,效果是最优的,因此D阶段的网络也就是最后的VGGNet啦!
ResNet:
ResNet-50, ResNet-101, and ResNet-152 代码及ILSVRC/COCO模型(Caffe) https://github.com/KaimingHe/deep-residual-networks
以上模型的Torch版(lua),由Facebook实现 https://github.com/facebook/fb.resnet.torch
ResNet-1001代码及ILSVRC/COCO模型(Caffe-目前第一名) https://github.com/KaimingHe/resnet-1k-layers
ResNet-1001在CIFAR-10上的表现
| mini-batch | CIFAR-10 test error (%): (median (mean+/-std)) |
|---|---|
| 128 (as in [a]) | 4.92 (4.89+/-0.14) |
| 64 (as in this code) | 4.62 (4.69+/-0.20) |
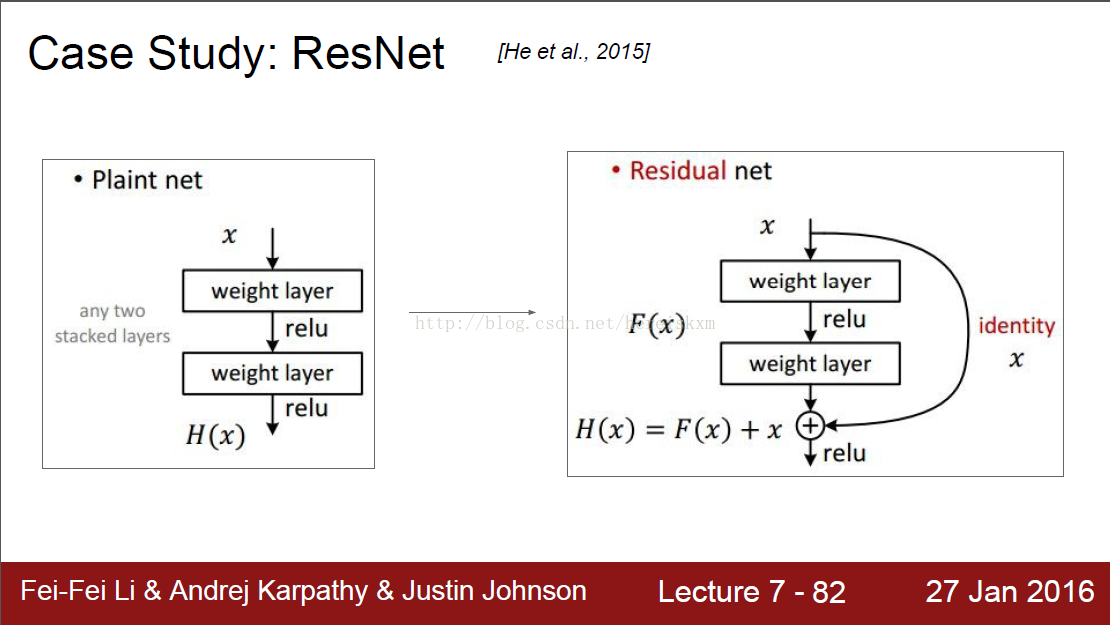
正常的网络是生成一个关于输入的函数,而ResNet生成的是一个对于输入的一个修饰:H(x) = F(x)+x。即神经网络生成的结果还要加上输入,才是最终输出。

训练参数如上图:
- 每一个Conv层后面都会有Batch Normalization层。
- 权重初始化方式:Xavier/2
- optimization方式:随机梯度下降+Momentum(0.9)
- 学习率:0.1,每一次错误率达到瓶颈时除以10,直到错误率无法再优化为止。
- Mini-batch(每批训练数据) 大小为256
- Weight 衰减1e-5(?)
- 不需要dropout
</div>
常用数据集:
ImageNet http://www.image-net.org/
Microsoft的COCO http://mscoco.org/
CIFAR-10和CIFAR-100 https://www.cs.toronto.edu/~kriz/cifar.html
PASCAL VOC http://host.robots.ox.ac.uk/pascal/VOC/
模型们在ImageNet竞赛上的top-5错误率概况:
常用预训练模型池:
https://github.com/BVLC/caffe/wiki/Model-Zoo
AlexNet:
AlexNet 代码及模型(Caffe) https://github.com/BVLC/caffe/tree/master/models/bvlc_alexnet
微调AlexNet以适应任意数据集(Tensorflow) https://github.com/kratzert/finetune_alexnet_with_tensorflow
AlexNet信息如上图
- 在当时第一次使用了ReLU
- 使用了Norm层(在当时还不广泛)
- 训练数据量增大
- dropout 0.5
- 每批数据大小 128
- 优化方式:随机梯度下降+Momentum 0.9
- 学习率为0.01。每次损失到达瓶颈时除以10
- L2 正则 参数为5e-4
VGG:
VGG-16 官方代码和ILSVRC模型(Caffe) https://gist.github.com/ksimonyan/211839e770f7b538e2d8
VGG-19 官方代码和ILSVRC模型(Caffe) https://gist.github.com/ksimonyan/3785162f95cd2d5fee77
Tensorflow版 VGG-16/VGG-19 https://github.com/machrisaa/tensorflow-vgg
VGG是最符合典型CNN的一种网络,它在AlexNet的基础上加深了网络,以达到更好的效果。
(以下引用http://blog.csdn.net/u012767526/article/details/51442367#vggnet分析)
这里有两个表格,其中第一个表格是描述的是VGGNet的诞生过程。为了解决初始化(权重初始化)等问题,VGG采用的是一种Pre-training的方式,这种方式在经典的神经网络中经常见得到,就是先训练一部分小网络,然后再确保这部分网络稳定之后,再在这基础上逐渐加深。表1从左到右体现的就是这个过程,并且当网络处于D阶段的时候,效果是最优的,因此D阶段的网络也就是最后的VGGNet啦!
ResNet:
ResNet-50, ResNet-101, and ResNet-152 代码及ILSVRC/COCO模型(Caffe) https://github.com/KaimingHe/deep-residual-networks
以上模型的Torch版(lua),由Facebook实现 https://github.com/facebook/fb.resnet.torch
ResNet-1001代码及ILSVRC/COCO模型(Caffe-目前第一名) https://github.com/KaimingHe/resnet-1k-layers
ResNet-1001在CIFAR-10上的表现
| mini-batch | CIFAR-10 test error (%): (median (mean+/-std)) |
|---|---|
| 128 (as in [a]) | 4.92 (4.89+/-0.14) |
| 64 (as in this code) | 4.62 (4.69+/-0.20) |
正常的网络是生成一个关于输入的函数,而ResNet生成的是一个对于输入的一个修饰:H(x) = F(x)+x。即神经网络生成的结果还要加上输入,才是最终输出。
训练参数如上图:
- 每一个Conv层后面都会有Batch Normalization层。
- 权重初始化方式:Xavier/2
- optimization方式:随机梯度下降+Momentum(0.9)
- 学习率:0.1,每一次错误率达到瓶颈时除以10,直到错误率无法再优化为止。
- Mini-batch(每批训练数据) 大小为256
- Weight 衰减1e-5(?)
- 不需要dropout
</div>