版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/algorithmPro/article/details/79221122
【写在前面的话】大概一年前看过Andrew老师的机器学习课程,受益良多。今年在用机器学习分类的时候,发现很多机器学习基础知识都已经忘得一干二净,对自己很是无语。因此,作者打算重新温习一篇Andrew老师的机器学习课程,并用博客来记录每一节课程的知识要点,加油吧!
机器学习模型:
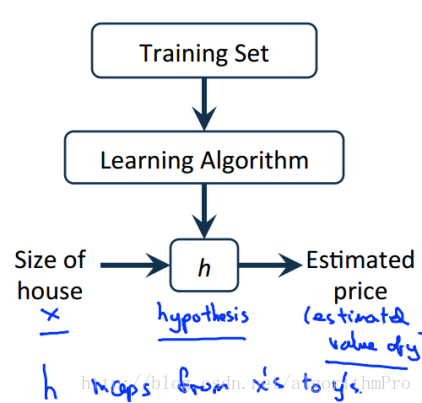
如上图,机器学习可以理解为:通过对训练数据学习来构建模型h(hypothesis),然后再通过新的测试数据来估计输入数据的结果。
模型估计:
模型估计主要是通过最小化损失函数来实现的,因此,怎么找到损失函数且最小化损失函数是模型估计的重点。
假设单变量回归模型:
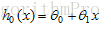
损失函数(cost function):
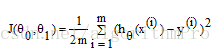 ,其中i为样本序号。
,其中i为样本序号。
通过最小化损失函数来求解模型参数,如下图:

梯度表示某一曲面在该点处增加最快的方向,因此,梯度的反方向亦是数值减小最快的方向,梯度下降法来求极值即是利用了这一种思想。
梯度下降算法:

利用梯度下降法同时更新theta0和theta1,当值随着迭代次数的增加收敛时,则停止更新,记录当前的参数值。

如上图:α代表学习率,若α过小,则梯度下降算法运算时间较慢;若α过大,则梯度下降算法则会超过极小值,最后可能不能满足收敛,甚至发散。

上表表示:固定学习率α,也能达到极小值,因为越接近极值点,则梯度越小,移动步长会自适应的较小。
梯度下降算法求解线性回归

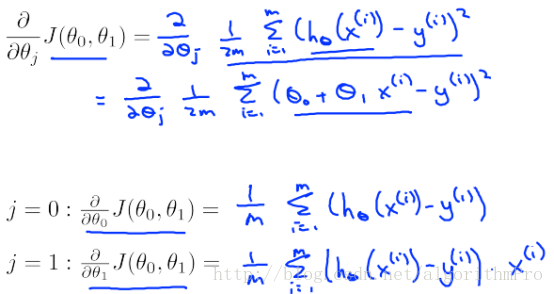
通过梯度下降算法同时更新参数theta:

梯度下降算法的求解受到初始值的影响,初始值选取的不一样,最后得到的结果有可能不一样,如下两图:
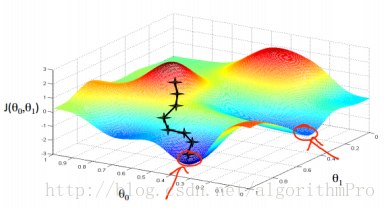

也可用等高线来表示:

损失函数可以理解为凸函数(convex Function),如下图:

批量梯度下降算法:
批量:每个步骤的梯度下降算法都使用了全部的训练数据。
