https://www.luogu.org/problemnew/show/P1983
题目描述
一条单向的铁路线上,依次有编号为 1, 2, …, n1,2,…,n的 nn个火车站。每个火车站都有一个级别,最低为 11 级。现有若干趟车次在这条线路上行驶,每一趟都满足如下要求:如果这趟车次停靠了火车站 xx,则始发站、终点站之间所有级别大于等于火车站xx 的都必须停靠。(注意:起始站和终点站自然也算作事先已知需要停靠的站点)
例如,下表是55趟车次的运行情况。其中,前44 趟车次均满足要求,而第 55 趟车次由于停靠了 33 号火车站(22级)却未停靠途经的 66 号火车站(亦为 22 级)而不满足要求。
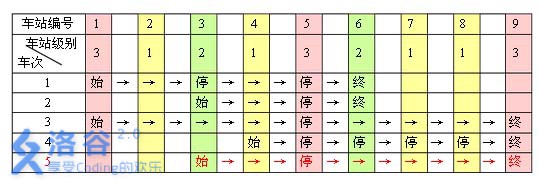
现有 mm 趟车次的运行情况(全部满足要求),试推算这nn 个火车站至少分为几个不同的级别。
输入输出格式
输入格式:
第一行包含 22 个正整数 n, mn,m,用一个空格隔开。
第 i + 1i+1 行(1 ≤ i ≤ m)(1≤i≤m)中,首先是一个正整数 s_i(2 ≤ s_i ≤ n)si(2≤si≤n),表示第ii 趟车次有 s_isi 个停靠站;接下来有s_isi个正整数,表示所有停靠站的编号,从小到大排列。每两个数之间用一个空格隔开。输入保证所有的车次都满足要求。
输出格式:
一个正整数,即 nn 个火车站最少划分的级别数。
输入输出样例
输入样例#1: 复制
9 2
4 1 3 5 6
3 3 5 6 输出样例#1: 复制
2输入样例#2: 复制
9 3
4 1 3 5 6
3 3 5 6
3 1 5 9 输出样例#2: 复制
3说明
对于20\%20%的数据,1 ≤ n, m ≤ 101≤n,m≤10;
对于 50\%50%的数据,1 ≤ n, m ≤ 1001≤n,m≤100;
对于 100\%100%的数据,1 ≤ n, m ≤ 10001≤n,m≤1000。
题目看懂了以后就是在S——》T区间中,所有读入的点的值必须大于没有读入的值
可以连边后跑DAG上DP
但是如果暴力连的话有O(n^2),
这时有两种优化:线段树优化,构造虚点优化
前个优化菜鸡不会,先讲构造虚点优化
构造虚点:顾名思义就是构造一个不应存在的点帮助解题(就像辅助线一样),
两个点集合两两相连有n^2条边,可以在中间构造一个虚点,把两个点集中所有点与虚点连边
这时候只有2n条边,很优秀
之后反向建图后跑记忆化搜即可
#include<cstdio>
#include<iostream>
using namespace std;
int read()
{
int ret=0; char ch=getchar();
while(ch<'0'||ch>'9') ch=getchar();
while(ch>='0'&&ch<='9')
ret=(ret<<1)+(ret<<3)+ch-'0',ch=getchar();
return ret;
}
const int N=1e6+5;
int m,nn,f[N],ans,a[N];
int cnt,to[N],nxt[N],he[N];
inline void add(int u,int v)
{
to[++cnt]=v,nxt[cnt]=he[u],he[u]=cnt;
}
void dfs(int u)
{
for(int e=he[u];e;e=nxt[e])
{
int v=to[e];
if(!f[v]) dfs(v);
f[u]=max(f[u],f[v]);
}
f[u]+=a[u];
ans=max(ans,f[u]);
}
int main()
{
nn=read(),m=read();
for(int i=1;i<=m;i++)
{
int x=read();
int lst=read();
add(lst,i+nn);
for(int j=2;j<=x;j++)
{
int y=read();
for(int k=lst+1;k<y;k++) add(i+nn,k);
add(lst=y,i+nn);
}
}
for(int i=1;i<=nn;i++) a[i]=1;
for(int i=1;i<=nn;i++)
if(!f[i]) dfs(i);
printf("%d\n",ans);
return 0;
}