
Introduction
Hierarchical Text Classification(HTC)是指文本标签之间存在层次结构文本分类任务。不同的标签之间存在的潜在关联会为分类提供正向指导。一般来说,HTC大致可以分为两类:为每个节点或级别构建分类器的局部方法,仅为整个图构建一个分类器的全局方法。
本文提出一种用于层次文本分类的对比学习方法。Hierarchy guided Contrastive Learning (HGCLR)直接将分层嵌入到文本编码器中而不是单独地创建层次的结构。在训练过程中,HGCLR在标签层次结构的指导下,为输入文本构建正样本。通过将输入文本和它的正样本放在一起,文本编码器可以学习独立地生成支持层次结构的文本表示。具体的结构如下:

Methodology
总体的模型结构如下:
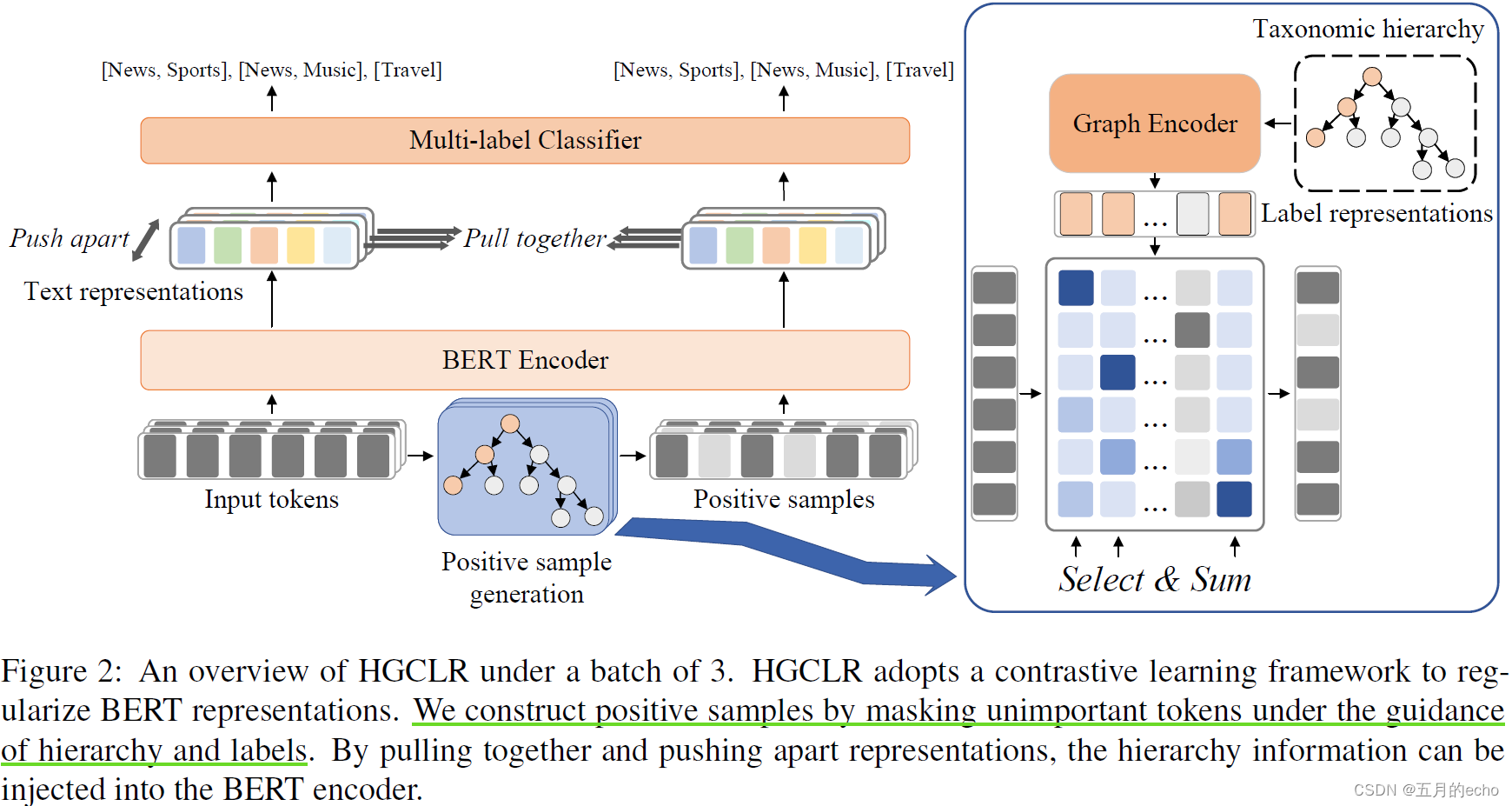
Text Encoder
首先,本文利用BERT作为文本的编码器:

得到的不同token的隐状态为:

Graph Encoder
之后,将图结构构建为一个Directed Acyclic Graph (DAG)无环有向图 G = ( Y ; E ) G = (Y;E) G=(Y;E),并使用Graphormer对图进行编码(本来也想写一个关于Graphormer文章的,但是其原论文还是比较通俗易懂的,就算了)。标签作为节点,其初始特征为其编号以及文本的嵌入的加和:

之后,采用基于Transformer的传播方式在标签图上进行特征传播。首先,Graphormer利用两个节点 f i , f j f_i,f_j fi,fj之间的一些潜在特征为其生成相似矩阵:

遵从Graphormer,公式中的三个项分别表示节点 f i , f j f_i,f_j fi,fj之间的注意力、 c i j c_{ij} cij表示节点之间的边的编码, b ϕ b_{\phi} bϕ则表示两个节点之间的连通性。在这里,还是参照一下Graphormer中的定义:
ϕ ( y i , y j ) \phi{(y_i,y_j)} ϕ(yi,yj)表示节点之间的最短路径长度,然后 b ϕ b_{\phi} bϕ是针对最短路径的值indexed的一个可学习的标量。这个项目很明显用于统计一些静态的图信息,最短路径值值是固定的。
c i j c_{ij} cij则是节点之间路径上的边的特征编码:

这里的 N N N表示路径上的边的条数, x e n x_{e_n} xen是相应的边的特征。而在本文中, c i j c_{ij} cij的定义略有不同,省略了可学习的变换 w n E w_n^E wnE:

D D D就是 N N N, w e i ∈ R 1 w_{e_i} \in R^1 wei∈R1,是一个可学习的量。之后,类似于Transformer中的操作,也对 A i j G A_{ij}^G AijG做Softmax乘一个可学习的参数矩阵 V V V,然后添加残差 F F F(所有节点的初始特征矩阵):

Positive Sample Generation
其实上述针对标签图的学习主要还是对Graphormer做一个相关回顾,本文的重点我觉得还是在如何构造对比学习上。为了选取正样本,需要利用上一步学习到的标签特征对样本做一个注意力的选择(也就是图2中蓝色框内的部分):

其中 e i e_i ei是每一个token的表示:

A i j A_{ij} Aij最终的实际含义就是每一个不同token对相应的标签的贡献概率,通过softmax获取到一个概率分布。如此一来,通过给定一个特定的标签,可以从这个分布中抽取token x ^ \hat{x} x^并形成一个正样本。为了使得采样的过程可微,将softmax改写为Gumbel-Softmax:

这里的 P i j P_{ij} Pij表示token对不同标签的影响的概率。对于多标签分类,只需将所有ground-truth的概率相加,得到一个令牌 x i x_i xi对其ground-truth标签集 y y y的概率为:

在这里,通过设置一个阈值 γ \gamma γ确定采样的token的数量:

其中0是一个特殊的token,其embedding的每一位都是0。正样品与原始样本送入相同的BERT:

Contrastive Learning Module
负样本的构建过程要相对简单。对于学习到的真实样本表示 h i h_i hi以及相应的正例 h i ^ \hat{h_i} hi^,只需要通过添加一个非线性层即可得到两个对应的负样本:

所以,对于一个batch为 N N N的输入,会产生 2 ( N − 1 ) 2(N-1) 2(N−1)个负例。然后,采用NT-Xent强迫正负例之间的距离变大:

s i m ( ) sim() sim()是余弦相似度, μ \mu μ的定义为:

τ \tau τ则是很常见的温度参数啦。总对比损失是所有例子的平均损失:

Classification and Objective Function
之后,将多标签分类的层次结构扁平化。将隐藏的特征输入线性层,并使用sigmoid函数计算概率:

则样本的多标签损失则是常用的BCE损失函数:


同样,对比学习中的正样本应该也有一个一样的损失 L ^ C \hat{L}^C L^C。最终的损失函数是原始数据的分类损失、构造正样本的分类损失和对比学习损失的组合:

在测试过程中,只使用文本编码器进行分类,模型退化为带分类头的BERT编码器。
Experiments

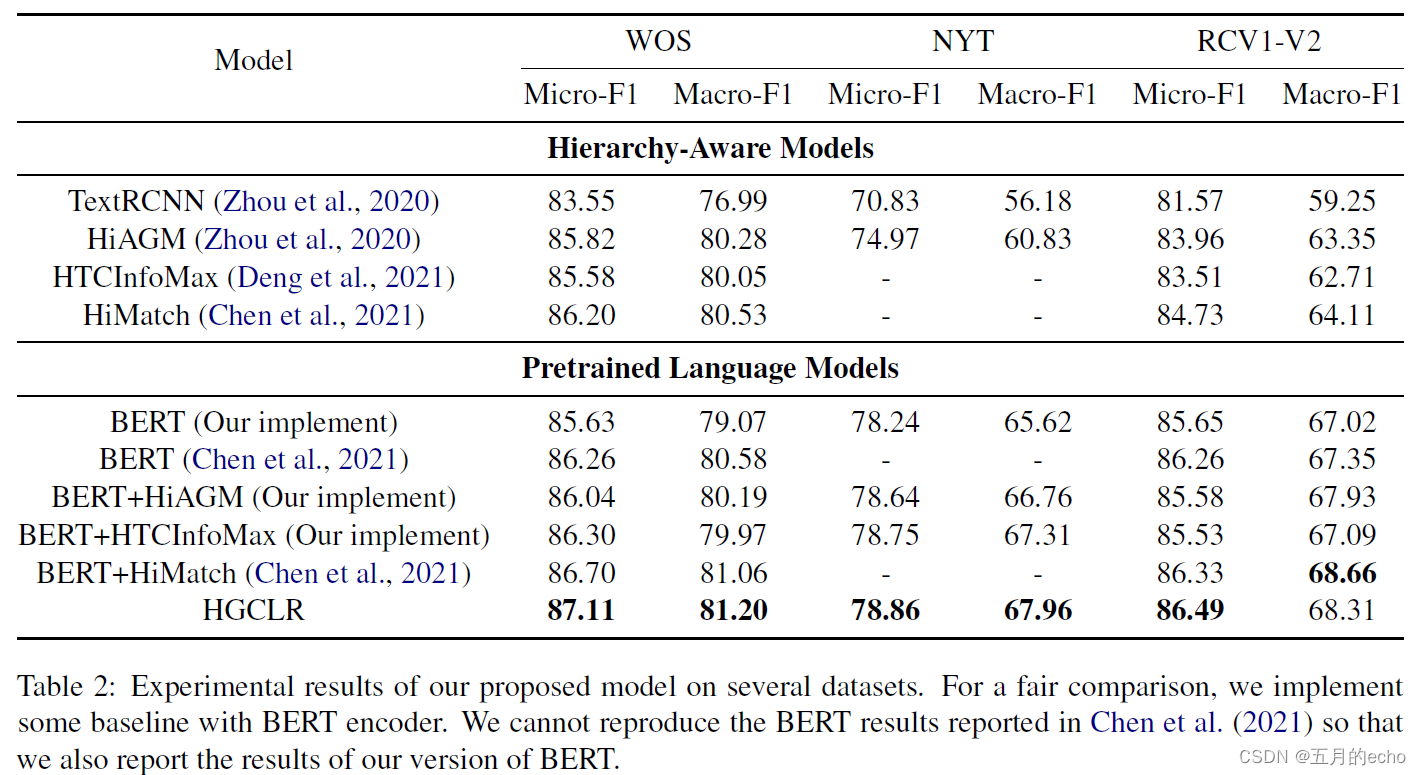
对比:
消融实验,其中rp表示替代; rm表示移除:

标签可视化的分析:

同一个颜色表示具有相同的父亲,本文的方法能够很好地提取出标签之间的层次结构相比于BERT来说。
一些基于Graphormer的变体:

不同正例生成技术的影响:
