前段时间一直在看自然语言处理方面的知识,所以不可避免的接触到了隐马尔科夫模型和条件随机场模型。这两个模型可以说是自然语言处理方向的基础模型了,所以自然而然对它们上心许多。它们之间也确实是有许多的异同,当时为了清晰地区分开它们,确实是花费了我好一阵子时间,而且到现在自己也还没有完完全全把它们吃透,但还是斗胆把自己整理的一些资料和心得贴出来供大家参考,希望大家都能少走弯路,节约时间。
隐马尔科夫模型
第一部分我会简单介绍隐马尔科夫模型,我给出的介绍是我在知乎上看到的比较好的解答,所以我会借鉴部分(其实是能力不够,写不出来通俗易懂的东西啦)
这个是原作连接https://www.zhihu.com/question/35866596/answer/236886066
HMM属于典型的生成式模型。应该是要从训练数据中学到数据的各种分布,那么有哪些分布呢以及是什么呢?直接正面回答的话,正是HMM的5要素,其中有3个就是整个数据的不同角度的概率分布:
,隐藏状态集
, 我的隐藏节点不能随意取,只能限定取包含在隐藏状态集中的符号。
,观测集
, 同样我的观测节点不能随意取,只能限定取包含在观测状态集中的符号。
,状态转移概率矩阵,这个就是其中一个概率分布。他是个矩阵,
(N为隐藏状态集元素个数),其中
即第i个隐状态节点,即所谓的状态转移嘛。
,观测概率矩阵,这个就是另一个概率分布。他是个矩阵,
(N为隐藏状态集元素个数,M为观测集元素个数),其中
即第i个观测节点,
即第i个隐状态节点,即所谓的观测概率(发射概率)嘛。
,在第一个隐状态节点
,我得人工单独赋予,我第一个隐状态节点的隐状态是
所以图看起来是这样的:
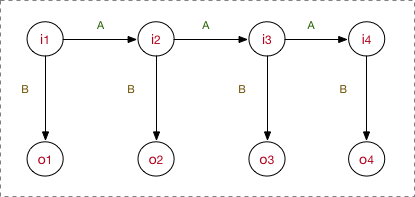
看的很清楚,我的模型先去学习要确定以上5要素,之后在inference阶段的工作流程是:首先,隐状态节点 是不能直接观测到的数据节点,
才是能观测到的节点,并且注意箭头的指向表示了依赖生成条件关系,
在A的指导下生成下一个隐状态节点
,并且
在
的指导下生成依赖于该
的观测节点
, 并且我只能观测到序列
。
好,举例子说明(序列标注问题,POS,标注集BES):
input: "学习出一个模型,然后再预测出一条指定"
expected output: 学/B 习/E 出/S 一/B 个/E 模/B 型/E ,/S 然/B 后/E 再/E 预/B 测/E ……
其中,input里面所有的char构成的字表,形成观测集,这些概率分布信息(上帝信息)都是我在学习过程中所确定的参数。
然后一般初次接触的话会疑问:为什么要这样?……好吧,就应该是这样啊,根据具有同时带着隐藏状态节点和观测节点的类型的序列,在HMM下就是这样子建模的。
下面来点高层次的理解:
- 根据概率图分类,可以看到HMM属于有向图,并且是生成式模型,直接对联合概率分布建模
(注意,这个公式不在模型运行的任何阶段能体现出来,只是我们都去这么来表示HMM是个生成式模型,他的联合概率
就是这么计算的)。
- 并且B中
,这意味着o对i有依赖性。
- 在A中,
,也就是说只遵循了一阶马尔科夫假设,1-gram。试想,如果数据的依赖超过1-gram,那肯定HMM肯定是考虑不进去的。这一点限制了HMM的性能。
模型运行过程
模型的运行过程(工作流程)对应了HMM的3个问题。
学习训练过程
HMM学习训练的过程,就是找出数据的分布情况,也就是模型参数的确定。
主要学习算法按照训练数据除了观测状态序列 是否还有隐状态序列
分为:
- 极大似然估计, with 隐状态序列
- Baum-Welch(前向后向), without 隐状态序列
感觉不用做很多的介绍,都是很实实在在的算法,看懂了就能理解。简要提一下。
1. 极大似然估计
一般做NLP的序列标注等任务,在训练阶段肯定是有隐状态序列的。所以极大似然估计法是非常常用的学习算法,我见过的很多代码里面也是这么计算的。比较简单。
- step1. 算A
- step2. 算B
- step3. 直接估计
比如说,在代码里计算完了就是这样的:



2. Baum-Welch(前向后向)
就是一个EM的过程,如果你对EM的工作流程有经验的话,对这个Baum-Welch一看就懂。EM的过程就是初始化一套值,然后迭代计算,根据结果再调整值,再迭代,最后收敛……好吧,这个理解是没有捷径的,去隔壁钻研EM吧。
这里只提一下核心。因为我们手里没有隐状态序列 信息,所以我先必须给初值
,初步确定模型,然后再迭代计算出
,中间计算过程会用到给出的观测状态序列
。另外,收敛性由EM的XXX定理保证。
序列标注(解码)过程
好了,学习完了HMM的分布参数,也就确定了一个HMM模型。需要注意的是,这个HMM是对我这一批全部的数据进行训练所得到的参数。
序列标注问题也就是“预测过程”,通常称为解码过程。对应了序列建模问题3.。对于序列标注问题,我们只需要学习出一个HMM模型即可,后面所有的新的sample我都用这一个HMM去apply。
我们的目的是,在学习后已知了 ,现在要求出
,进一步
再直白点就是,我现在要在给定的观测序列下找出一条隐状态序列,条件是这个隐状态序列的概率是最大的那个。
具体地,都是用Viterbi算法解码,是用DP思想减少重复的计算。Viterbi也是满大街的,不过要说的是,Viterbi不是HMM的专属,也不是任何模型的专属,他只是恰好被满足了被HMM用来使用的条件。谁知,现在大家都把Viterbi跟HMM捆绑在一起了, shame。
Viterbi计算有向无环图的一条最大路径,应该还好理解。如图:
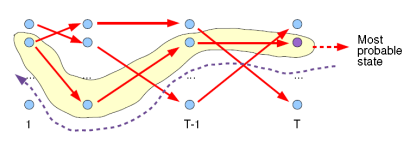
关键是注意,每次工作热点区只涉及到t 与 t-1,这对应了DP的无后效性的条件。如果对某些同学还是很难理解,请参考这个答案下@Kiwee的回答吧。
序列概率过程
我通过HMM计算出序列的概率又有什么用?针对这个点我把这个问题详细说一下。
实际上,序列概率过程对应了序列建模问题2.,即序列分类。
在3.2.2第一句话我说,在序列标注问题中,我用一批完整的数据训练出了一支HMM模型即可。好,那在序列分类问题就不是训练一个HMM模型了。我应该这么做(结合语音分类识别例子):
目标:识别声音是A发出的还是B发出的。
HMM建模过程:
1. 训练:我将所有A说的语音数据作为dataset_A,将所有B说的语音数据作为dataset_B(当然,先要分别对dataset A ,B做预处理encode为元数据节点,形成sequences),然后分别用dataset_A、dataset_B去训练出HMM_A/HMM_B
2. inference:来了一条新的sample(sequence),我不知道是A的还是B的,没问题,分别用HMM_A/HMM_B计算一遍序列的概率得到,比较两者大小,哪个概率大说明哪个更合理,更大概率作为目标类别。
所以,本小节的理解重点在于,如何对一条序列计算其整体的概率。即目标是计算出 。这个问题前辈们在他们的经典中说的非常好了,比如参考李航老师整理的:
- 直接计算法(穷举搜索)
- 前向算法
- 后向算法
后面两个算法采用了DP思想,减少计算量,即每一次直接引用前一个时刻的计算结果以避免重复计算,跟Viterbi一样的技巧。
HMM实现中文分词源码
import pickle
import os
class HMM(object):
def __init__(self):
# 主要是用于存储算法中间结果,不用每次都训练模型
self.model_file = 'data/hmm_model.pkl'
# 状态值集合
self.state_list = {'B', 'M', 'E', 'S'}
# 参数加载,用于判断是否需要重新加载model_file
self.load_para = False
# 接受一个参数,用于判断是否加载中间文件结果
def try_laod_model(self, trained):
if trained:
with open(self.model_file, 'rb') as f:
self.A_dic = pickle.load(f)
self.B_dic = pickle.load(f)
self.Pi_dic = pickle.load(f)
self.load_para = True
else:
# 状态转移概率(状态->状态的条件概率)
self.A_dic = {}
# 发射概率(状态->词语的条件概率)
self.B_dic = {}
# 状态的初始概率
self.Pi_dic = {}
self.load_para = False
# 训练给定的分词语料,得出HMM所需的初始概率,转移概率以及发射概率
def train(self, path):
# 重置几个基本的概率矩阵
self.try_laod_model(False)
# 统计状态出现次数,求p(o)
count_dic = {s: 0 for s in self.state_list}
# 初始化相关参数
self.init_parameters()
line_num = -1
# 观察者集合,主要是字以及标点等
words = set()
with open(path, encoding='utf-8') as f:
for line in f:
line_num += 1
line = line.strip()
if not line:
continue
# 集合为字以及标点等
word_list = [i for i in line if i != ' ']
# 更新字的集合
words |= set(word_list)
linelist = line.split()
line_state = []
for w in linelist:
line_state.extend(self.makeLabel(w))
for k, v in enumerate(line_state):
count_dic[v] += 1
if k == 0:
# 每个句子的第一个字的状态,用于计算初始状态概率
self.Pi_dic[v] += 1
else:
# 计算转移概率
self.A_dic[line_state[k - 1]][v] += 1
# 计算发射概率
self.B_dic[line_state[k]][word_list[k]] = self.B_dic[line_state[k]].get(word_list[k], 0) + 1
self.Pi_dic = {k: v / line_num for k, v in self.Pi_dic.items()}
self.A_dic = {k: {k1: v1 / count_dic[k] for k1, v1 in v.items()} for k, v in self.A_dic.items()}
# 加一平滑
self.B_dic = {k: {k1: (v1 + 1) / count_dic[k] for k1, v1 in v.items()} for k, v in self.B_dic.items()}
print("B_dic['S'].", self.B_dic['S'].keys())
with open(self.model_file, 'wb') as f:
pickle.dump(self.A_dic, f)
pickle.dump(self.B_dic, f)
pickle.dump(self.Pi_dic, f)
print("B_dic['S'].", self.B_dic['S'].keys())
return self
# 初始化相关参数
def init_parameters(self):
for state in self.state_list:
self.A_dic[state] = {s: 0.0 for s in self.state_list}
self.Pi_dic[state] = 0.0
self.B_dic[state] = {}
# 为text句子打上状态标记
def makeLabel(self, text):
out_text = []
if len(text) == 1:
out_text.append('S')
else:
out_text += ['B'] + ['M'] * (len(text) - 2) + ['E']
return out_text
def viterbi(self, text, states, start_p, trans_p, emit_p):
V = [{}]
path = {}
for y in states:
V[0][y] = start_p[y] * emit_p[y].get(text[0], 0)
path[y] = [y]
for t in range(1, len(text)):
V.append({})
newpath = {}
# 检验训练的发射概率矩阵中是否有该字
neverSeen = text[t] not in emit_p['S'].keys() and text[t] not in emit_p['M'].keys() and \
text[t] not in emit_p['E'].keys() and text[t] not in emit_p['B'].keys()
for y in states:
# 设置未知字单独成词\n",
emitP = emit_p[y].get(text[t], 0) if not neverSeen else 1.0
(prob, state) = max([(V[t - 1][y0] * trans_p[y0].get(y, 0) * emitP, y0)
for y0 in states if V[t - 1][y0] > 0])
V[t][y] = prob
newpath[y] = path[state] + [y]
path = newpath
if emit_p['M'].get(text[-1], 0) > emit_p['S'].get(text[-1], 0):
(prob, state) = max([(V[len(text) - 1][y], y) for y in ('E', 'M')])
else:
(prob, state) = max([(V[len(text) - 1][y], y) for y in states])
print("emit_p['S'].keys()", emit_p['S'].keys())
return prob, path[state]
def cut(self, text):
if not self.load_para:
self.try_laod_model(os.path.exists(self.model_file))
prob, pos_list = self.viterbi(text, self.state_list, self.Pi_dic, self.A_dic, self.B_dic)
begin, next = 0, 0
for i, char in enumerate(text):
pos = pos_list[i]
if pos == 'B':
begin = i
elif pos == 'E':
yield text[begin: i + 1]
next = i + 1
elif pos == 'S':
yield char
next = i + 1
if next < len(text):
yield text[next:]
if __name__ == '__main__':
hmm = HMM()
hmm.train('data/trainCorpus.txt_utf8')
text = '这是一个非常棒的方案'
res = hmm.cut(text)
print(str(list(res)))
以下是 'data/trainCorpus.txt_utf8' 这个文件的百度云盘连接
链接:https://pan.baidu.com/s/1p-b4ENP8xui7DDlmuwTYuQ
提取码:yz10
最后还是稍微讲讲关于HMM与CRF之间的区别吧
CRF就像一个反向的隐马尔可夫模型(HMM),两者都是用了马尔科夫链作为隐含变量的概率转移模型,只不过HMM使用隐含变量生成可观测状态,其生成概率有标注集统计得到,是一个生成模型;而CRF反过来通过可观测状态判别隐含变量,其概率亦通过标注集统计得来,是一个判别模型。由于两者模型主干相同,其能够应用的领域往往是重叠的,但在命名实体、句法分析等领域CRF更胜一筹。当然你并不必须学习HMM才能读懂CRF,但通常来说如果做自然语言处理,这两个模型应该都有了解。
关于HMM暂时就贴这么多了,CRF我会多贴东西,敬请期待啦