因为语料是分好词来训练的,所以代码写起来还算简单,HMM的参数pi,A,B训练只是做一个简单的统计工作
反倒是写维特比算法时出了一些问题,因为之前都是纸上谈兵,真正写这个算法才发现之前有的地方没有搞明白!!
维特比的算法大致如下:
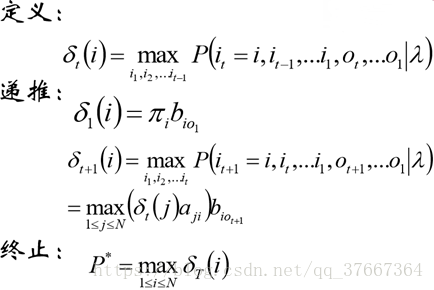
注:下面[]中代表下标
在计算δ[t](i)是需要遍历δ[t-1](j),j遍历所有的隐状态,找到一个隐状态使得δ[t](i)最大,计算完所有的δ后是一个观测序列O长度*状态长度的矩阵,特别注意的是这时候并不是在矩阵中找出每一个观测最优可能的状态构成的状态序列成为预测序列,因为计算δ[t](i)时是由前一个δ[t-1](j)影响的,而j这个状态影响了δ[t](i)使得最大,我们需要一个矩阵(大小同δ矩阵,记为states)保存δ[t-1](j)是由哪一个状态影响才得到最优状态,最后计算预测序列时,先从之前的δ矩阵的最后一行,也就是最后一个观测值找出它最有可能的状态,然后从这个状态出发,由之前的状态矩阵states回溯得到预测序列,这将在代码中体现!
下面是python代码实现:
# coding: utf-8
import numpy as np
import math
#每一个字的4个隐藏状态 0123/start(该字是一个词的开头) middle(该字是一个词的中间部分) end(该字是一个词的结束) single(该字是单独就是一个词)
#监督学习:用的语料库是分好词的来训练
#注:ord()函数获取一个字符的Unicode编码
infinite = float(-2.0**31)#负无穷
#训练参数(已知O和I的情况下监督学习),只需要做一个统计就可以得到参数
#传入字符串语料数据,必须是处理好分词的,并且传入分隔符
def mle(train_data,split_char=" "):
tokens = train_data.split(split_char)
#模型参数
pi = np.zeros(4)#状态概率pai
A = np.zeros((4,4))#状态转移矩阵
B = np.zeros((4,65536))#发射矩阵,某个隐状态下的观测分布
last_token = tokens[0]
for token in tokens:
token = token.strip()
token_len = len(token)
last_token_state =3 if len(last_token)==1 else 2#若上一个token长度为1则为single转移到某个状态否则是end转移到某个状态
#不为空字符判断
if token_len ==0:
continue
#单字成词
if token_len == 1:
pi[3]+=1
A[last_token_state][3]+=1#上一个状态转移到single
#给出状态single下出现的观测字符
B[3][ord(token)]+=1
elif token_len==2:
pi[0]+=1
pi[2]+=1
#start转移到end
A[0][2]+=1
A[last_token_state][0]+=1
#给出状态start和end下出现的观测字符
B[0][ord(token[0])]+=1
B[2][ord(token[1])]+=1
else:
pi[0]+=1
pi[2]+=1
pi[1]+=token_len -2
#start转移到middle,middle转移到middle,middle转移到end
A[0][1]+=1
A[1][1]+=(token_len-3)
A[1][2]+=1
A[last_token_state][0]+=1
#给出状态start,middle,end下出现的观测字符
B[0][ord(token[0])]+=1#start
B[2][ord(token[token_len-1])]+=1#end
for i in range(1,token_len-1):#middle
B[1][ord(token[i])]+=1
last_token = token
#取对数
sum1 = np.sum(pi)
for i in range(len(pi)):
pi[i] = math.log(pi[i] / sum1)
log_val(A)
log_val(B)
return pi,A,B
#对pi,A,B结果取对数,因为单个数值太小,会溢出
def log_val(data):
#遍历矩阵每一行,每一行概率相加为1,做取对数处理
col_len = data.shape[1]
for k,line in enumerate(data):
sum1 = np.sum(line)
log_sum = math.log(sum1)
for i in range(col_len):
if data[k][i] == 0:
data[k][i] = infinite
else:
data[k][i] = math.log(data[k][i]) - log_sum
#预测维特比算法
def viterbi(pi,A,B,O):
O = O.strip()
O_len = len(O)
pi_len = len(pi)
if O_len==0:
return
#保存所有状态的最大值是由哪一个状态产生的也就是计算δ[t](i)时,是由哪一个δ[t-1](q)产生的,q就是哪个状态
states = np.full(shape=(O_len,pi_len),fill_value=0.0)
#保存计算过所有的计算的δ
deltas = np.full(shape=(O_len,pi_len),fill_value=0.0)
#初始化计算最优P(I,O1) = max{P(O1|I)*p(I)}
for j in range(0,pi_len):
deltas[0][j] = pi[j] + B[j][ord(O[0])]#变加法是因为取了对数
#dp计算P(I|O1,O2,O3,...Ot,I1,I2...It-1)
for t in range(1,O_len):
for i in range(0,pi_len):#计算每一个δ[t](i=q1...q[pi_len]) = max{δt[j]*A[ji]*B[qi|Ot]},j是遍历所有状态
deltas[t][i] = deltas[t-1][0]+A[0][i]
#寻找最大的δ[t](i)
for j in range(1,pi_len):
current = deltas[t-1][j]+A[j][i]
if current > deltas[t][i]:
deltas[t][i] = current
#保存当前δ[t](i)取得最大值是是从上一个哪个状态来的
states[t][i] = j
deltas[t][i] +=B[i][ord(O[t])]
#回溯找到最优概率路径
max1 = deltas[O_len-1][0]
best_state = np.zeros(O_len)
#先找出最后一个观测的最可能状态是什么
for i in range(1,pi_len):
if deltas[O_len-1][i] > max1:
max1 = deltas[O_len-1][i]
best_state[O_len-1] = i
#由最后一个观测得到的最好状态往前回溯找出状态序列
for i in range(O_len-2, -1, -1):
best_state[i] = states[i+1][int(best_state[i+1])]
return best_state
def output_words(decode,O):
T = len(O)
for i in range(0,T):
#如果预测当前字符最有可能的状态是end或者single就分词
if decode[i] ==2 or decode[i] == 3:
print(O[i],"|",end='')
else:
print(O[i],end='')
#开始训练
f = open("./pku_training.utf8","r",encoding="utf-8")
data = f.read()[3:];
f.close()
pi,A,B = mle(data)#训练结束
#测试
f2 = open("./novel.txt","r",encoding="utf-8")
O = f2.read().strip()
states = viterbi(pi, A, B, O)
output_words(states, O)
测试结果:

附上训练语料库和测试语料库: