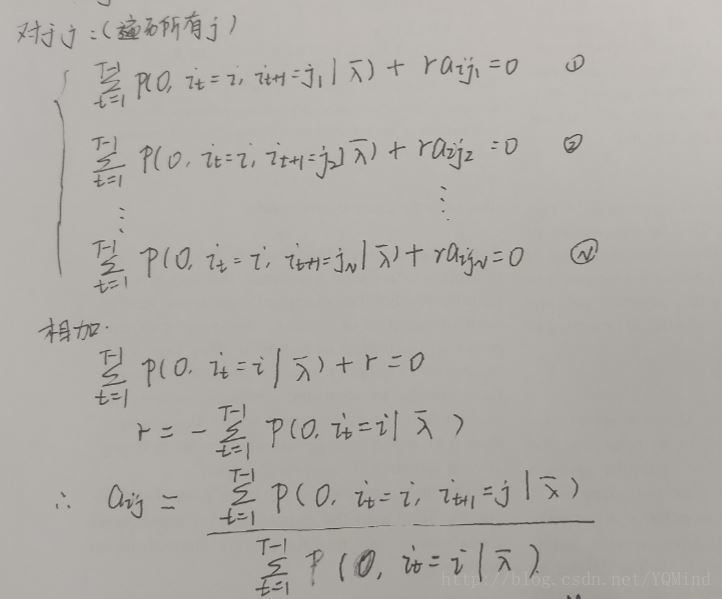HMM是生成模型,根据HMM,可以计算
首先,隐马尔科夫模型里有两条假设:
假设一:
隐藏的马尔科夫链在任意时刻t 的状态只依赖前一时刻的状态假设二:
任意时刻的观测只依赖于该时刻的隐状态
由此,引出隐马尔科夫模型的三个重要参数:
π 是初始状态概率向量,πi=P(i1=qi) 是t=1时刻,隐状态为qi 的概率。A 是状态转移概率矩阵,假设状态数是N ,那么A 是N×N 的矩阵,其中aij=P(it=qj|it−1=qi) 表示时刻t-1的状态为qi 的条件下,时刻t的状态为qj 的概率。B 是观测概率矩阵,假设观测数是M ,那么B 是N×M 的矩阵,其中bj(k)=P(ot=vk|it=qj) 表示时刻t为状态qj 的条件下,生成观测vk 的概率。
隐马尔科夫模型由初始概率矩阵
隐马尔科夫模型的三个基本问题
概率计算问题。给定模型参数
λ=(π,A,B) 和观测序列O=(o1,o2,...,oT) ,计算P(O|λ) 扫描二维码关注公众号,回复: 813347 查看本文章
学习问题。已知观测序列
O=(o1,o2,...,oT) ,求解模型参数λ=(π,A,B) 使得在该模型参数下,P(O|λ) 最大预测问题。给定模型参数
λ=(π,A,B) 和观测序列O=(o1,o2,...,oT) ,求解使得P(I|O) 最大的状态序列I=(i1,i2,...,iT)
问题1:概率计算问题
用前向算法或者后向算法求解。
- 前向算法
定义前向概率,αit=P(o1,o2,...,ot,it=qi) 。可以通过递推法求解观测序列概率P(O|λ) 。
观测序列概率计算的前向算法步骤如下:
输入:隐马尔科夫模型λ ,观测序列O
输出:观测序列概率P(O|λ)
step1: 初始化前向概率
αi1=πibi(o1) , i=1,2,…,N
step2:递推求解各个时刻的αit
αit=∑j=Nj=1αjt−1ajibi(ot) ,t=2,3,...,Ti=1,2,...,N
step3:求得目标观测序列概率P(O|λ)
P(O|λ)=∑iαiT
在step2递推过程中,可以理解为,
- 后向算法
定义后向概率,βit=P(ot+1,ot+2,...,oT|it=qi) 。可以通过递推法求解观测序列概率P(O|λ) 。
观测序列概率计算的后向算法步骤如下:
输入:隐马尔科夫模型λ ,观测序列O
输出:观测序列概率P(O|λ)
step1:初始化后向概率
βiT=1,i=1,2,...,N
step2:递推求解各个时刻的βit
βit=∑jβjt+1aijbj(ot+1) ,t=T−1,T−2,...,1i=1,2,...,N
step3:求得目标观测序列概率P(O|λ)
P(O|λ)=∑jπjβj1bj(o1)
条件概率意味着给定某某,求其他的概率。当反向递推时,只要意识到给定状态
我们先讲解问题三:预测问题
给定模型参数
用维特比算法求解。
维特比算法是用动态规划思想来求解隐马尔科夫模型预测问题的。我们需要求解使得
简单来说,我们想找到从A到B的最长路径,途径C。如果A到B的最长路径是
定义:
可以递推
定义
维特比算法具体步骤:
输入:隐马尔科夫模型
输出:最优路径
step1:初始化
step2:递推
step3:
step4:最优路径回溯:
问题2:学习算法
已知观测序列
监督学习算法
非监督学习算法—-Baum-Welch算法(EM算法)
第一步:确定完全数据的对数似然函数
第二步:E步,写出Q函数
我们写出Q函数之后后面就要对它进行极大化,也就是说EM算法的M步骤。既然是最大化,那么只要保证不影响最终的结果,对Q函数进行对于最大化来说没有影响的常数因子乘除是可以的。为什么要这么做呢?这是为了后面将概率计算问题中有意义的一些概率计算公式直接套进去。
step3:M步,极大化Q函数