本博客为博主查阅大量资料后整理原创,虽水仍不易,如需转载,请附上本文链接https://blog.csdn.net/JasonLeeeeeeeeee/article/details/81106558,谢谢
本文若有不足之处可以交流沟通,互相学习
1. 聚类简介
在机器学习中,分为监督学习、无监督学习和半监督学习。前一篇博客中提到的回归和分类都属于监督学习,本文着重探讨无监督学习中的聚类算法。
博主之前看过一些资料,这两天也翻阅了网上的各大博客后,也想总结一下,写一写聚类相关的知识点,对自己所看的知识也算是总结,以后回想也有翻的资料。
聚类算法是数据在没有标签的情况下,但是还是认为数据具有各自族群,不属于同一类,对这些数据进行聚类后,可以总结发现各个类的特点,有助于更深刻理解数据,判断数据的来源;分类算法是有所有数据的标签,然后让机器来学习这些数据中潜在的规律,把这个规律记住,当有新数据来了的时候,可以自动判断该数据属于哪一类。
翻阅了网上各大博客后,好多博客都会说的很全面,例如下图中,涵盖聚类算法的各种方法。
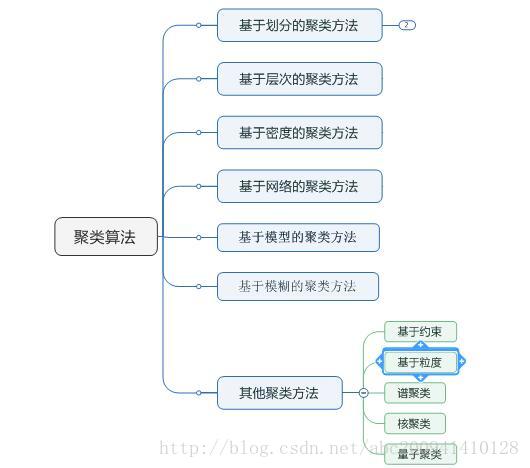
个人认为k均值聚类、层次聚类、密度聚类基本可以解决大部分数据聚类问题,这三个也是比较容易理解的方法,下面就对这三个方法进行介绍。
2. k均值聚类(k-means)
k-means算法属于基于划分的聚类方法(Partition-based methods),这种聚类方法的中心思想是认为“族内点的距离都足够近,族间点的距离都是相对较远的”。k-means算法首先要确定k值,即最终所聚簇群个数;然后选取k个点作为中心点,计算其他点到k个点的距离,围绕该聚类方法的中心思想,将所有数据分为k个簇群。对于该方法的各个环节中优化改进的变体算法包括k-medoids、k-modes、k-medians、kernel k-means等算法。算法步骤如下:
(1)从n个向量对象任意选择k个向量作为初始聚类中心;
(2)计算剩余每个对象与这k个中心对象各自的距离;
(3)把这个向量和距离它最近的中心向量对象归为一个类簇中;
(4)重新计算每个簇的平均值,更新为新的簇中心;
(5)重复(2)、(3)、(4)步骤,直到当前均值向量均未更新。
优点:对于大型数据集也是简单高效、时间复杂度、空间复杂度低。
缺点:最重要是数据集大时结果容易局部最优;需要预先设定K值,对最先的K个点选取很敏感;对噪声和离群值非常敏感;只用于numerical类型数据;不能解决非凸(non-convex)数据。
针对以上缺点目前有一些改进算法:
k-means对初始值的设置很敏感,所以有了k-means++(极可能选取较远的点作为初始聚类中心)、intelligent k-means、genetic k-means。
k-means对噪声和离群值非常敏感,所以有了k-medoids和k-medians。
k-means只用于numerical类型数据,不适用于categorical类型数据,所以k-modes。
k-means不能解决非凸(non-convex)数据,所以有了kernel k-means。
对于算法的一次次迭代更新,对每一个点都进行计算来说,计算量也不小。针对这个情况,可以参考采用k-d树来优化,这样可以只计算关键点,一些其他的非关键点可以不用计算,k-d树的详细讲解可以参考该博客,用k-d树来进行聚类优化可参考该博客。
3. 层次聚类(Hierarchical methods)
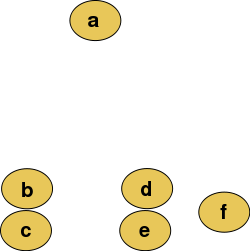
k-means聚类是将样本聚成若干类就可,现在讨论的层次聚类是将样本聚成若干类后,每个类群中再分为若干类,依次类推,可以形成一种树状的结构,例如下图。
源数据
聚类结果
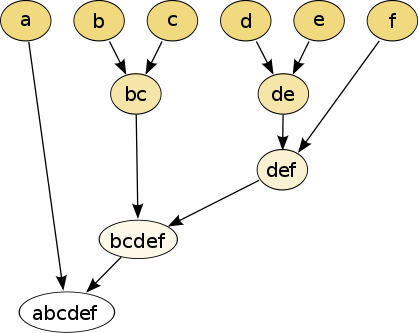
层次聚类主要有两种形式:合并的层次聚类和分裂的层次聚类。合并的层次聚类是上图中自顶向下合并,首先把每个对象作为一个簇,然后进行相似簇群合并,直到达到某个终结条件为止;分裂的层次聚类则是上图中自下向上分裂,首先将所有对象看作是一个簇群,然后进行分裂,直到达到某个终结条件为止。以自下向上为例,算法流程为:
(1)将每个对象看作一个簇,计算两两之间的最小距离;
(2)将距离最小的两个簇合并为一个簇;
(3)重复计算新簇之间的距离;
(4)重复(2)、(3)直到达到终止条件。
这种聚类合并有3种不同的策略原则:
- Ward策略:让所有类簇中的方差最小化;
- Maximum策略:也叫completed linkage(全连接策略),力求将类簇之间的最大距离最小化;
- Average linkage策略:力求将类簇之间的平均距离最小化。
优点:可解释性好;可以产生高质量的类群;可以在k-means设置比较大的k值计算后,进一步进行聚类。
缺点:(1)时间复杂度高,
;贪心算法的统一缺点,一步错步步错。
该聚类算法因为计算复杂度比较大适用于小数量级,如对中国省会城市聚类。改进的算法有BIRCH(Balanced Iterative Reducing and Clustering Using Hierarchies)主要是在数据体量很大的时候使用,而且数据类型是numerical。
4. 密度聚类(DBSCAN)
k-means只能解决形状规则的聚类,解决不了不规则形状聚类,但是DBSCAN正好弥补这部分,可以系统解决这个问题。同时DBSCAN也可以用来离群点的识别,其他离群点识别算法在后面应该会专门写一篇博客来介绍。
在介绍算法步骤之前首先需要搞清楚几个概念:
Ε邻域:给定对象半径为Ε内的区域称为该对象的Ε邻域;
核心对象:如果给定对象Ε邻域内的样本点数大于等于MinPts,则称该对象为核心对象;
直接密度可达:对于样本集合D,如果样本点q在p的Ε邻域内,并且p为核心对象,那么对象q从对象p直接密度可达。
密度可达:对于样本集合D,给定一串样本点p1,p2….pn,p= p1,q= pn,假如对象pi从pi-1直接密度可达,那么对象q从对象p密度可达。
密度相连:存在样本集合D中的一点o,如果对象o到对象p和对象q都是密度可达的,那么p和q密度相联。
算法步骤流程如下:
(1) 从任一对象点p开始;
(2)寻找并合并核心p对象直接密度可达(eps)的对象;
(3)如果p是一个核心点,则找到了一个聚类,如果p是一个边界点(即从p没有密度可达的点)则寻找下一个对象点;
(4)重复(2)、(3),直到所有点都被处理;
(5)最终将样本点少于MinPts的簇群全部视为噪声点。
优点:可以对任意形状的稠密数据集进行聚类;可以在聚类的同时发现异常点,对数据集中的异常点不敏感;聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
缺点:如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合;如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进;调参相对于传统的K-Means之类的聚类算法稍复杂,主要需要对距离阈值ϵ,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
5. 后记
对于聚类还有一些其他的算法,例如西瓜书中还提到的LVQ、高斯混合聚类。LVQ的应用场景是当有一些好瓜和一些非好瓜的数据混合在一起(知道哪些是好瓜哪些是非好瓜),然后聚成5类,其中好瓜聚成3类,非好瓜聚成2类。博主觉得既然知道标签了,可以将问题分成好瓜的聚类和非好瓜的聚类,利用之前介绍的聚类算法,分两步解决,当然并不是否定这种算法就不行,只是觉得前面的算法基本可以解决该问题。高斯混合聚类是假定数据都是由若干高斯模型产生,然后将这些样本数据找出具体所产生的模型。可以先假定这些样本数据各自所属哪一模型,然后转化为EM算法进行求解,循环多次,直到结果收敛。博主觉得这个计算成本无疑是很大的,在工业生产中应该很少用到的吧。
聚类算法中都有一步是相似度距离计算,那么有哪些方法可以用呢?较为常用的是欧式距离,还有内积距离、余弦距离、曼哈顿距离等都可以用,具体用哪个距离方法,根据自己的实际情况而定。
之前介绍了常用的聚类算法的步骤,那么聚类的结果该如何去评判?这又回到了聚类的出发点,聚类的出发点是将相似的样本放到一个簇群里,另一种解释方法就是簇群内部相似度高,簇群间相似度低。那么围绕这个点可以对聚类结果进行量化计算,博主之前有一篇博客进行了详细介绍【传送门在这里】。
参考文献:
1. 机器学习 周志华
2. 白话大数据与机器学习 高扬等
3. https://www.zhihu.com/question/34554321
4. https://blog.csdn.net/abc200941410128/article/details/78541273?locationNum=1&fps=1
5. https://www.cnblogs.com/earendil/p/8135074.html
6. https://blog.csdn.net/datoutong_/article/details/78804151
7. https://www.cnblogs.com/xmeo/p/6543057.html
8. https://baike.baidu.com/item/DBSCAN/4864716?fr=aladdin
9. https://www.cnblogs.com/pinard/p/6208966.html